Genetic element
Size in base pairs
Human chromosome
3.3 × 109
Bacterial chromosome
1–4 × 106
Mitochondrial chromosome
16,569
Bacteriophage
39,000
CAM plasmid
500,000
pUC19 plasmid (engineered plasmid)
2,686
Retrotransposon (i.e., SINE to LINE 1)
75–7,000
Long intergenic noncoding RNA (lincRNA)
>200
Transcribed ultraconserved regions (T-UCR)
>200
Telomeric repeat containing RNAs (TERRA)
>200
Small nucleolar RNA (snoRNA)
60–300
Promoter upstream transcripts (PROMPTs)
<200
Promoter-associated small RNAs (PASR)
22–200
Transcription start site-associated RNA (TSSa-RNA)
20–90
PIWI-interacting RNA (piRNA)
26–31
microRNA (miRNA)
22
Transcription initiation RNA (tiRNA)
17–18
Eukaryotic Cells
Cytoplasm
In contrast to prokaryotic cells, eukaryotic cells are complex, highly compartmentalized structures. The cytoplasm contains multiple membrane-bound compartments known as organelles. The cellular membrane separates the cellular cytoplasm from the external environment. The membranes consist of hydrophobic lipid bilayers. The lipid bilayer contains proteins that serve as receptors and channels.
Nucleus and Nucleolus
The nucleus of the cell contains the cell’s linear chromosomes and serves as the primary locus of inherited genetic material. Inner- and outer-pore-containing membranes define the nucleus and separate the chromosomes from the surrounding cytoplasm. Further partitioning occurs within the nucleus to generate the nucleolus, which functions as the ribosome-generating factory of the cell. Instead of additional membranes, fibrous protein complexes separate the nucleolus from the rest of the nucleus. In this structure, the nucleolus organizer (a specific part of a chromosome containing the genes that encode ribosomal RNAs) interacts with other molecules to form immature large and small ribosomal subunits. Following processing, immature subunits depart the nucleolus and enter the nucleus. Eventually, mature ribosomal subunits and other molecules exit the nucleolus through the nuclear pores and enter the cytoplasm.
Mitochondria
Mitochondria are membrane-bound organelles within the cytoplasm of cells that have several cellular functions. Inheritable genetic material, independent from the nuclear chromosomes, resides in mitochondria. These maternally derived organelles contain their own circular chromosome (16,569 bp) and replicate independently from the cell and one another. As a result, not all mitochondria in a given cell have the same mitochondrial DNA (mtDNA) sequence. The genetic diversity of these organelles within and between different cells of the same organism is known as heteroplasmy. A range (approximately 39–1,283) of mitochondrial genomes are present per cell, and this number may vary with different disease states [6, 7]. Mitochondrial genes encode mitochondria-specific transfer RNA molecules (tRNA). In addition, the mtDNA contains genes that encode proteins used in oxidative phosphorylation, including subunits of the cytochrome c oxidase, cytochrome b complex, some of the ATPase complex, and various subunits of NAD dehydrogenase. Other components of the oxidative phosphorylation pathway are encoded by nuclear genes. For this reason, not all mitochondrial genetic diseases demonstrate maternal transmission. Mutations associated with mitochondrial diseases can be found at MITOMAP (http://www.mitomap.org/MITOMAP). The higher copy number per cell of mtDNA compared with genomic DNA (i.e., approximately 100 to 1) enables the detection and characterization of mtDNA from severely degraded samples and scant samples. For this reason, mtDNA is suitable for paleontological, medical, and forensic genetic investigations. Analysis of mtDNA has applications for diagnosis of mitochondrial-inherited genetic diseases, disease prognosis, as well as forensic identification of severely decomposed bodies [6–9].
Other Cellular Organelles
Membranes not only segregate heritable genetic molecules into the nucleus and mitochondria, but also separate various cellular functions into distinct areas of the cell. The compartmentalization of cellular functions (such as molecular synthesis, modification, and catabolism) increases the local concentration of reactive molecules and improves the biochemical efficiency of the cell. This partitioning also protects inappropriate molecules from becoming substrates for these processes. One example of this segregation is the endoplasmic reticulum (ER), which consists of a complex of membranous compartments where proteins are synthesized. Glycoproteins are synthesized by ribosome-ER complexes known as rough ER (RER), while lipids are produced in the smooth ER. The Golgi apparatus possesses numerous membrane-bound sacs where molecules generated in the ER become modified for transportation out of the cell. In addition, peroxisomes and lysosomes segregate digestive and reactive molecules from the remainder of the cellular contents to prevent damage to the cell’s internal molecules and infrastructure. The pathologic accumulation of large molecules within lysosomes occurs when enzymes cannot chemically cleave or modify the large molecules. Lysosomal storage and mucopolysaccharide storage diseases are associated with a variety of genetic variants and mutations. Similarly, peroxisomal diseases are associated with genetic defects in the peroxisomal enzyme pathway [1].
Biological Molecules
Carbon can covalently bond to several biologically important atoms (i.e., oxygen, hydrogen, and nitrogen) and forms the scaffold for all biomolecules. Basic subunit biomolecules can combine to form more complex molecules such as carbohydrates, nucleic acids, and amino acids.
Carbohydrates
Carbohydrates serve as energy reservoirs and are a component of nucleic acids. In addition, carbohydrates also attach to lipids and proteins. The basic unit of a carbohydrate consists of the simple sugars or monosaccharides. These molecules have carbon, oxygen, and hydroxyl groups that most commonly form ringed structures. The oxygen can react with the hydroxyl group of another simple sugar to form a chain. As a result, the formula for a simple sugar is (CH2O) n , where n represents various numbers of these linked building block units.
Two pentose sugars, deoxyribose and ribose, comprise the sugar element of DNA and RNA molecules, respectively. As the name indicates, deoxyribose (“de-,” a prefix meaning “off” and “oxy,” meaning “oxygen”) lacks one hydroxyl (OH) group compared with ribose.
Nucleic Acids
Nucleic acids are composed of chains of nucleotides. Each nucleotide is composed of a sugar (either ribose or deoxyribose), a phosphate (–PO4) group, and a purine or pyrimidine base. The nucleotides are joined into a DNA or RNA strand by a sugar-phosphate-linked backbone with the bases attached to and extending from the first carbon of the sugar group. The purine and pyrimidine bases are weakly basic ring molecules, which form N-glycosidic bonds with ribose or deoxyribose sugar. Purines are comprised of two rings, a six-member ring and a five-member ring (C5H4N4), while pyrimidines consist of a single six-member ring (C4H2N2). Purines (guanine, G, and adenine, A) pair with pyrimidines (cytosine, C, and thymine, T) via hydrogen bonds between two DNA molecules (Fig. 1.1). The additional hydrogen bond that forms between G and C base pairing (i.e., three hydrogen bonds) dramatically enhances the strength of this interaction compared to the two hydrogen bonds present between A and T nucleotides. This hydrogen-bonding capacity between G:C and A:T forms a pivotal molecular interaction for all nucleic acids and assures the passage of genetic information during DNA replication, RNA synthesis from DNA (transcription), and the transfer of genetic information from nucleic acids to the amino acids of proteins.
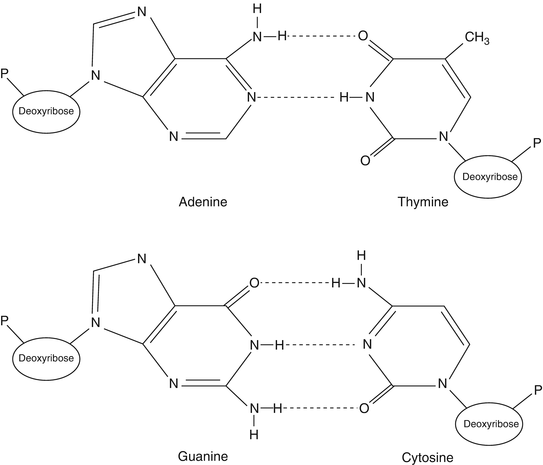
Figure 1.1
DNA base pairing. DNA nucleotides are composed of three moieties (e.g., sugar, base, and phosphate groups). The bases are either purine (adenine and guanine) or pyrimidine (thymine and cytosine). Note the difference in hydrogen bonds between adenine and thymine base pairs, with two hydrogen bonds, compared to cytosine and guanine base pairs, with three hydrogen bonds. Reprinted with permission from Leonard D. Diagnostic Molecular Pathology. 2003:1–13. Copyright Elsevier (2003)
Numerous types of base modifications increase the number of nucleotides beyond the classic four types (i.e., A, T, G, and C). Although these modifications do not alter the base’s hydrogen bonding characteristics, modified nucleotides serve various functions in the cell including (1) regulating gene function, (2) suppressing endoparasitic sequence reactivation, (3) identifying DNA damage, and (4) facilitating translation. Modifications such as 5-methylcytosine, 5-hydroxymethylcytosine, 5-formylcytosine, and 5-carboxylcytosine influence gene expression. Most endoparasitic sequences such as retrotransposons (e.g., long interspersed nucleotide elements [LINE 1]) are hypermethylated in normal tissue but hypomethylated in cancer tissue [10]. Presumably the hypermethylation of the LINE 1 sequences prevents various insults to the host genome by inactivating the ability of these elements to transpose themselves. Methylation also regulates the phenomenon of imprinting. Methylation mechanisms include P-element-induced wimpy testis (in Drosophila, PIWI) proteins and PIWI-interacting noncoding RNAs (specifically, piRNA) [11]. Additionally, certain modifications such as 8-oxoguanine and 8-oxoadenine are associated with DNA damage. Base pair modifications are not limited to DNA but also influence the function of tRNAs [12]. Some of these modifications include 5-formylcytidine, queuosine, 5-taurinomethyluridine, and 5-taurinomethyl-2-thiouridine. Certain tRNA modification defects result in mitochondrial disease [13]. Modifications of rRNA include 2′-O-methylation and pseudouridylation and enable rRNA folding and stability. Such modifications result from interactions of the bases with small nucleolar ribonucleoproteins and noncoding small nucleolar RNAs [5]. With the advent of methodologies that simplify the detection of modified bases, the role of modified bases in human disease may become better understood [14].
Amino Acids
Amino acids are the building blocks of proteins. Amino acids linked together via peptide bonds form large, complex molecules. Amino acids consist of an amino group (NH3), a carboxyl group (COO–), an R group, and a central carbon atom. The R group can be a simple hydrogen, as found in glycine, or as complex as an imidazole ring, as found in histidine. Twenty different R groups exist (Table 1.2), and determine whether an amino acid has a neutral, basic, or acidic charge. The amino group of a polypeptide is considered the beginning of the protein (N-terminus), while the carboxyl group is at the opposite end, providing directionality to the protein.
Table 1.2
Amino acids
Amino acid | Amino acid symbols | Linear structure | |
|---|---|---|---|
Three letter | Single letter | ||
Alanine | ala | A | CH3–CH(NH2)–COOH |
Arginine | arg | R | HN=C(NH2)–NH–(CH2)3–CH(NH2)–COOH |
Asparagine | asn | N | H2N–CO–CH2–CH(NH2)–COOH |
Aspartic acid | asp | D | HOOC–CH2–CH(NH2)–COOH |
Cysteine | cys | C | HS–CH2–CH(NH2)–COOH |
Glutamic acid | glu | E | HOOC–(CH2)2–CH(NH2)–COOH |
Glutamine | gln | Q | H2N–CO–(CH2)2–CH(NH2)–COOH |
Glycine | gly | G | NH2–CH2–COOH |
Histidine | his | H | NH–CH=N–CH=C–CH2–CH(NH2)–COOH |
Isoleucine | ile | I | CH3–CH2–CH(CH3)–CH(NH2)–COOH |
Leucine | leu | L | (CH3)2–CH–CH2–CH(NH2)–COOH |
Lysine | lys | K | H2N–(CH2)4–CH(NH2)–COOH |
Methionine | met | M | CH3–S–(CH2)2–CH(NH2)–COOH |
Phenylalanine | phe | F | Ph–CH2–CH(NH2)–COOH |
Proline | pro | P | NH–(CH2)3–CH–COOH |
Serine | ser | S | HO–CH2–CH(NH2)–COOH |
Threonine | thr | T | CH3–CH(OH)–CH(NH2)–COOH |
Tryptophan | trp | W | Ph–NH–CH=C–CH2–CH(NH2)–COOH |
Tyrosine | tyr | Y | HO–Ph–CH2–CH(NH2)–COOH |
Valine | val | V | (CH3)2–CH–CH(NH2)–COOH |
Genetic Molecules
Nucleic acids encode genetic information but also participate in additional physiological processes ranging from metabolism to energy transfer. Nucleotides constitute the monomeric units of nucleic acids (Fig. 1.1). Nucleosides consist of two components (ribose or deoxyribose in RNA and DNA, respectively, and either a purine or pyrimidine base). A nucleotide is produced from a nucleoside by the addition of one to three phosphate groups through a covalent bond with the hydroxyl group of the 5′ carbon of the nucleoside’s sugar ring.
Nucleic acids consist of chains of nucleotides linked by phosphodiester bonds between the 3′ carbon of the first nucleotide’s sugar ring and the 5′ carbon of the adjacent nucleotide’s sugar ring. The phosphodiester linkages cause nucleic acids to have a 5′ to 3′ directionality. The alternating sugar-phosphate chain forms a continuous molecule with bases extending from the 1′ carbon of each sugar. For this reason, the sugar-phosphate chain is referred to as the backbone of nucleic acids (Fig. 1.2). The phosphate groups give nucleic acids a negative charge that imparts important physiochemical properties to nucleic acids. The negative charge of DNA facilitates the binding of mammalian DNA to various proteins and allows separation of nucleic acid molecules by charge and size during gel or capillary electrophoresis.
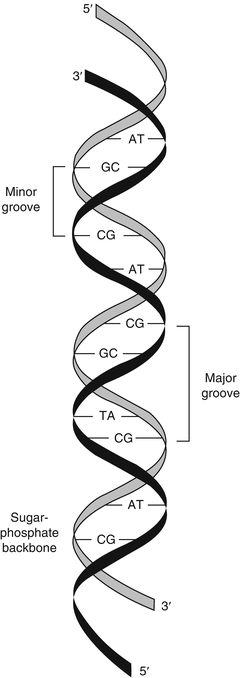
Figure 1.2
Double-stranded DNA. The two DNA strands are oriented in an antiparallel relationship, with asymmetric base pairing of two DNA strands that generates the minor and major grooves of the DNA double helix. Reprinted with permission from Leonard D. Diagnostic Molecular Pathology. 2003:1–13. Copyright Elsevier (2003)
Structure
In double-stranded DNA, the two DNA strands are held together by exact A:T and G:C hydrogen bonding between the bases of the two strands, in which case the two strands are said to be complementary. The two strands are oriented in opposite 5′ to 3′ directions, such that one strand is oriented 5′ to 3′ and the complementary strand is oriented 3′ to 5′ in an antiparallel fashion (see Fig. 1.2). In this case, “anti-” refers to the head (or 5′ end) of one DNA strand being adjacent to the tail (or 3′ end) of the opposite strand.
The molecular curves of the two DNA strands form antiparallel helices known as the DNA double helix. This double-helix form (the B form) has ten nucleotide base pairs per turn, occupying 3.4 nm. Because the bonds between the sugar and the base are not perfectly symmetrical, the strands curve slightly. The slight curve of the offset glycosidic bonds results in major and minor grooves characteristic of the B form of the double helix [15]. Many clinical molecular tests target the minor groove of DNA with sequence-specific probes known as minor groove-binding (MGB) probes. Two other forms of DNA exist as the Z and A forms. The Z form acquires a zigzag shape, while the A form has very shallow and very deep grooves.
Thermodynamics of Nucleotide Base Pairing
Thermodynamics plays a major role in the structure and stability of nucleic acid molecules. The core mechanism of nucleic acid thermodynamics centers on the hydrogen-bonding capabilities of the nucleotides. The stability of these interactions not only influences the formation and stability of duplex (or double-stranded) nucleic acids but also impacts the structure and catalytic characteristics of single-stranded nucleic acids through intramolecular base pairing. In addition to these physiological functions, the phenomenon of complementary base pairing profoundly impacts clinical diagnostic test development. Prior to the advent of clinical molecular testing, many clinical tests required a target-specific antibody to identify or detect a target protein. The procedures for generating and validating diagnostic antibodies require extensive time and expense. The application of techniques utilizing the capability of two molecules to base pair as the basis for detection and characterization of target nucleic acids has greatly facilitated clinical molecular test development. The formation of hydrogen bonding between two pieces of nucleic acid is called hybridization, or annealing, and the disruption of the hydrogen bonds holding two nucleic acid molecules together is called denaturation, or melting. The fact that clinical molecular tests use hybridization techniques based on A:T and G:C base pairing underscores the necessity for understanding the thermodynamics of the hydrogen base pairing of nucleic acids.
Short pieces of DNA or RNA called probes, or primers, that contain a specific sequence complementary to a disease-related region of DNA or RNA from a clinical specimen are frequently used for clinical molecular tests. To achieve hybridization of a DNA or RNA probe to genomic DNA for a clinical molecular test, the two genomic DNA strands must be separated, or denatured, prior to probe hybridization. Increasing the temperature of a DNA molecule is one mechanism for disrupting the hydrogen bonds between the DNA base pairs and denaturing double-stranded DNA into single-stranded form. The temperature at which 50 % of the double-stranded DNA molecules separate into single-stranded form constitutes the melting temperature (T m). The shorter the two complementary DNA molecules are, the easier it is to calculate the T m. This primarily results from the decreased likelihood of nonspecific intramolecular annealing or base pairing compared to inter- and intramolecular base pairing. The simplest and least accurate formula for determining the T m for short double-stranded DNA multiplies the sum of the G:C base pairs by 4 and multiplies the sum of the A:T base pairs by 2 and then adds these numbers together:
![$$ {T}_{\mathrm{m}}=\left[4\left(\mathrm{G}:\mathrm{C}\right)\right]+\left[2\left(\mathrm{A}:\mathrm{T}\right)\right] $$](/wp-content/uploads/2016/10/A78412_2_En_1_Chapter_Equa.gif)
Although this is the least accurate method for calculation of the T m of a double-stranded DNA molecule, it mathematically illustrates that G:C bonds are roughly twice the strength of A:T bonds. This formula works fairly well for short DNA molecules (i.e., <18 bp); however, as the length of the DNA molecule increases to 100 bp, the nearest neighbor T m calculation for DNA and RNA is more accurate [16, 17]:
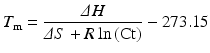 where
where
∆H = enthalpy of the nucleic acid fragment
∆S = entropy of the nucleic acid fragment
R = 1.987 calK−1 mol−1
Ct = total strand concentration
For longer sequences (>100 bp), the most accurate formula for calculation of T m is as follows [18]:
![$$ \begin{array}{l}{T}_{\mathrm{m}}=81.5{}^{\circ}\mathrm{C}+16.6\;\left({ \log}_{10}\;\left[{\mathrm{Na}}^{+}\right]\right)+0.41\;\left[\%\mathrm{G}\mathrm{C}\right]\\ {}-0.65\;\left(\%\;\mathrm{formamide}\right)-675/\mathrm{length}-\%\mathrm{mismatch}\end{array} $$](/wp-content/uploads/2016/10/A78412_2_En_1_Chapter_Equc.gif)
Table 1.3 demonstrates the effect of increasing the relative amounts of G:C base pairs on the T m using these formulas.
Table 1.3
Melting temperature calculations for short oligomers
Total length | Number of G:C | Number of A:T | T m a | %G:C b | A:T + G:C c |
|---|---|---|---|---|---|
30 | 30 | 0 | 106.2 | 100.0 | 100.0 |
30 | 25 | 5 | 101.2 | 93.2 | 100.0 |
30 | 20 | 10 | 89.5 | 79.5 | 90.0 |
30 | 10 | 20 | 83.4 | 72.7 | 80.0 |
30 | 0 | 30 | 71.6 | 59.0 | 60.0 |
20 | 20 | 0 | 90.4 | 88.8 | 80.0 |
20 | 10 | 10 | 72.7 | 65.1 | 60.0 |
20 | 0 | 20 | 55.9 | 47.8 | 40.0 |
Intramolecular base pairing also generates complex three-dimensional forms within single-stranded nucleic acid molecules. As a result, the single-stranded nature of eukaryotic RNA molecules affords great structural diversity via intramolecular base pairing. These conformations strain the linear RNA molecule and produce chemically reactive RNA forms. Catalytic RNA molecules play pivotal roles in cellular functions and in gene-targeting therapies.
Intra- and intermolecular base pairing can negatively affect hybridizations. Dimers, bulge loops, and hairpin loops exemplify some of these interactions. Hairpins inhibit plasmid replication and attenuate bacterial gene expression [2]. These detrimental effects also may include initiation of spurious nonspecific polymerization, steric hindrance of hybridization of short stretches of nucleic acids (i.e., 10–30 base pieces of single-stranded nucleic acids, known as oligomers or primers), and depletion of probes or primers away from the specific target by either primer dimerization or other mechanisms. These interactions can result in poor sensitivity or specificity for clinical molecular tests.
Topology
The DNA and RNA molecules assume various geometric shapes or topologies that are independent of base pair interactions. Eukaryotic nucleic acids take on linear forms, in contrast to the circular forms of mitochondrial and bacterial chromosomal DNA. Transposable elements within the human genome also have a linear topology. Viral genomes occur as different forms, ranging from segmented linear to circular, and can be present in the nucleus, cytoplasm, or integrated within the human genome. Although the conformation of RNA molecules can be complex via intramolecular base pairing, the topology of messenger RNA (mRNA) molecules is primarily linear. An organism’s genomic topology influences the biochemical mechanisms used during replication and the number of replication cycles a given chromosome can undertake. In contrast to circular genomes, linear genomes limit the total number of possible replication cycles due to progressive shortening of the linear chromosome. In order to mitigate the shortening of the linear chromosomes, the ends of the chromosome contain tandem guanine base-rich repeats known as telomeres.
Mammalian Chromosomal Organization
The human genome contains approximately 3.3 × 109 base pairs of DNA. At least 2.94 % of the genome encodes genes according to the GENCODE reference gene set [19]. However, more protein-encoding genes may be identified if the bioinformatic definition of a gene changes [20]. Approximately, 80.4 % of the genome engages in at least one RNA- and/or chromatin-based activity with many of these bases being located in regions possessing repeated sequences. Most of the repeated sequences are retrotransposons, including long interspersed repeat sequences 1 (LINE 1), short interspersed repeat sequences (SINE, including Alu sequences), retrotransposable element 1 (RTE-1), endogenous retroviruses, a chimeric element (SVA) composed of “SINE-R,” and variable number of tandom repeats (VNTRs). The ability of retrotransposons to duplicate and insert within the genome (i.e., either autonomously or with the help of autonomous elements) has been associated with various types of genetic mutations. Mechanisms for mutations include insertional mutagenesis, unequal homologous recombination resulting in the loss of genomic sequences, and generation of novel genes. More than 100 different reports associate retrotransposons with various genetic disorders ranging from hemophilia to breast cancer [21, 22]. Retrotransposons influence transcription of microRNAs (discussed later in this chapter). Because transposable elements can replicate and cause genetic deletions with the human genome, the number of human base pairs is not static. However in germline cells, piRNAs stabilize the genome by cleaving transposable element transcripts [5].
The total DNA is contained in 46 double-stranded DNA pieces complexed with proteins to form chromosomes. The diploid human cell possesses 46 chromosomes: two of each of the 22 autosomal chromosomes, plus either two X chromosomes in females, or one X and one Y chromosome in males. Since the length of each helical turn of a double-stranded DNA molecule is 3.4 nm and consists of ten bases, the length of the total genomic DNA in each cell measures approximately 1 m in length.
For each cell to contain these long DNA molecules, the double-stranded DNA must be compressed. A complex of eight basic histones (two copies each of histone 2 [H2], H3, H4, and H5) package the DNA [23]. The histone complex contains positively-charged amino acids that bind to 146 bases of negatively-charged DNA. Histones fold the DNA either partially or tightly, resulting in compression of the DNA strand. Tight folding of the DNA condenses the DNA into heterochromatin. Following packaging and condensation, the nucleic acid strand widens from 2 to 1,400 nm, with extensive overall shortening of the nucleic acid in the metaphase chromosome. Light microscopy easily permits the visualization of condensed metaphase chromosomes.
Hypersensitivity to DNase I identifies approximately 2.9 million sites with less condensed DNA in the genome [24]. Less condensed DNA binds histone 1 (H1) proteins or other sequence-specific DNA-binding molecules. Some of these DNA-binding molecules regulate gene expression (discussed later in this chapter). In contrast, tightly condensed chromosomes lack the “open spaces” for binding of regulatory proteins and prevent gene expression from highly condensed DNA regions. These proteins also may prevent access to nucleic acid probes or primers for clinical molecular tests. Some tissue fixation methods can create covalent links between the nucleic acid and these proteins that can cause molecular testing artifacts (e.g., false-negative results). As a result, many DNA extraction protocols include a protein-digestion step to liberate the DNA from the DNA-binding proteins. Removal of the proteins facilitates hybridization with short pieces of nucleic acid, such as primers or probes.
DNA Replication
Eukaryotic DNA Replication
The replication of DNA is a complex process requiring specific physiological temperatures and a host of proteins. As mentioned previously, clinical molecular testing methods rely on the ability to denature or melt a double-stranded DNA template. Using chemical or physical conditions, separation of DNA strands can be accomplished with alkaline conditions or high temperatures (i.e., 95 °C). Under physiological conditions, dissociation of DNA strands for replication is accomplished by numerous enzymes, such as helicases and topoisomerases. The region of transition from double-stranded to separated single-stranded DNA is called the replication fork. The replication fork moves along the double-stranded DNA molecule as replication proceeds. At the replication fork, various primases, initiating proteins, and polymerases bind to the original or parental DNA strands and generate two new daughter strands. Known collectively as a replisome, these enzymatic activities generate two new nucleic acid strands that are complementary to and base paired with each of the original two template or parent DNA strands. This replication process is known as semiconservative because each resulting double-stranded DNA molecule consists of one new and one old DNA strand (Fig. 1.3).
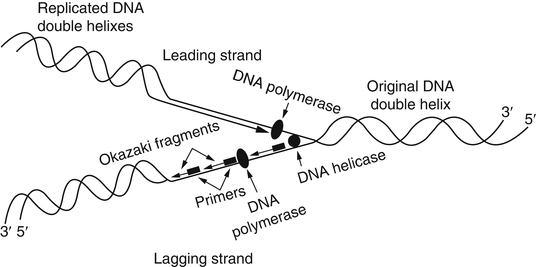
Figure 1.3
DNA replication. Replication fork depicting the leading and lagging strands and the numerous proteins and Okazaki fragments involved with replication. Reprinted with permission from Leonard D. Diagnostic Molecular Pathology. 2003:1–13. Copyright Elsevier (2003)
Polymerases function to synthesize new nucleic acid molecules from nucleotide building blocks. The sequence of the new strand is based on the sequence of an existing nucleic acid molecule, and the polymerase adds nucleotides according to the order of the bases of the parent strand, using G:C and A:T pairing. The new strand is antiparallel to the parent strand and is synthesized in a 5′ to 3′ direction. Of the two parent strands of genomic DNA, one strand (called the leading strand) can be read continuously in a 3′ to 5′ direction by the polymerase, with the new strand generated in a continuous 5′ to 3′ direction. In contrast, the opposite strand (known as the lagging strand) cannot be read continuously by the polymerase. The replication fork moves along the lagging strand in a 5′ to 3′ direction, and the polymerase synthesizes only by reading the parent strand in a 3′ to 5′ direction while synthesizing the new strand in a 5′ to 3′ direction. Therefore, synthesis cannot proceed continuously along the lagging strand, which must be copied in short stretches primed from RNA primers and forming short DNA fragments known as Okazaki fragments. The new strand complementary to the lagging strand is formed by removal of the RNA primer regions and ligation of the short DNA fragments into a continuous daughter strand complementary to the lagging strand.
Discontinuous 3′ to 5′ replication results in the progressive loss of ends of the chromosomes known as telomeres in normal cells. The guanine-rich telomeres form secondary structures (or caps) that prevent chemical processes that can damage the chromosome. Apoptosis occurs when the number of uncapped telomeres reaches a critical threshold that triggers cell death. Telomerase reverse transcriptase (hTERT) and telomeric repeat containing RNAs (TERRAs) contribute to telomere homeostasis by adding bases to the 3′ end. Mutations in the hTERT and/or the telomerase RNA template (hTERC) decrease telomerase activity and are associated with dyskeratosis congenital, bone marrow failure, and pulmonary fibrosis [25–27]. Telomerase activity varies with cell type with lymphocytes experiencing more telomere length shortening than granulocytes. Telomeres shorten with age with the most prominent shortening occurring between birth and the first year of age, followed by childhood and after puberty or adulthood [28]. In contrast to these age-related changes, some malignant cells retain telomerase activity that permits the addition of these terminal telomeric sequences to the chromosomes, prolonging the life of the cell.
While replication requires many proteins, the polymerase determines the speed and accuracy of new strand synthesis. The rate that the four nucleotides are polymerized into a nucleic acid chain defines the processivity of the enzyme. The processivity of most polymerases approximates 1,000 bases per minute.
The fidelity of the polymerase refers to the accuracy of the enzyme to incorporate the correct complementary bases in the newly synthesized DNA. Incorporation of incorrect bases or other replication errors can result in cell death or oncogenesis. The error rate of polymerases varies widely from 1 in 1,500 to 1 in 1,000,000 bases (Table 1.4). DNA is susceptible to base pair changes while in the single-stranded form due to the activity of various deaminating enzymes. Many of these enzymes are induced during inflammation and have been associated with somatic hypermutation of rearranged immunoglobulin genes [32].
Table 1.4
Fidelity of various polymerases
Polymerase | Error rate (×10 −6 ) |
|---|---|
pol aa | 250 |
pol betaa | 666 |
pol gammaa | 100 |
Pfub
Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
 Get Clinical Tree app for offline access
Get Clinical Tree app for offline access

|