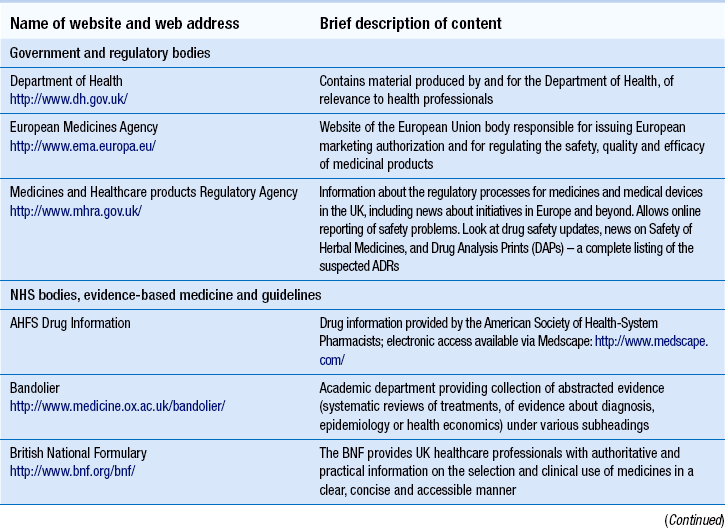
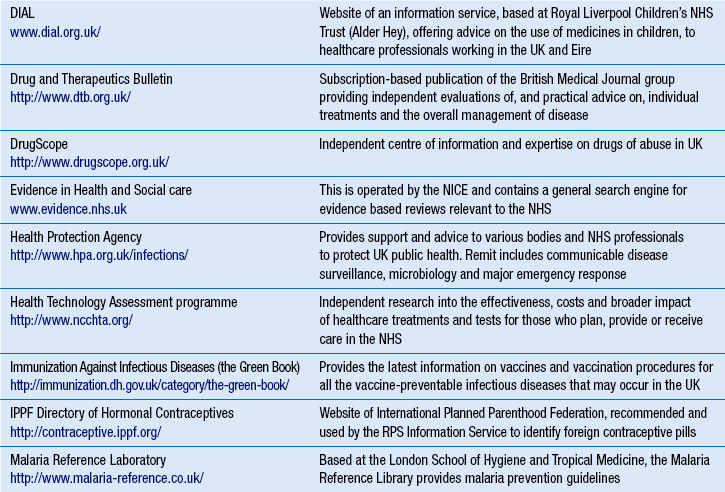
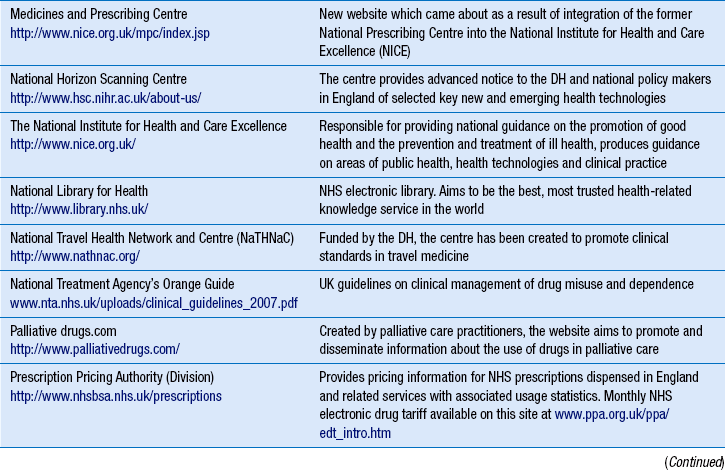
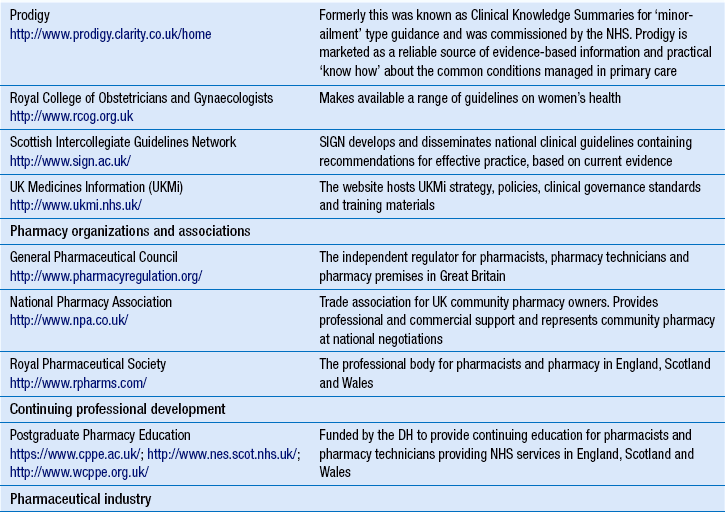
16 The current era is characterized by man’s inordinate ability to store, retrieve and transmit large volumes of information using computer technology. Albert Einstein proposed that the secret of success is ‘to know where to find the information and how to use it’. Most pharmacists would probably agree. This chapter aims to provide the reader with a theoretical understanding of how to source health- and medicines-related information in the present information age. While the quality of retrieved information is considered, guidance on the detailed evaluation of what is known broadly as ‘clinical evidence’ is found elsewhere (see Ch. 20). In the GPhC’s Standards of conduct, ethics and performance, the knowledge and provision of health- and medicines-related information, specifically, is considered in the following manner. In relation to their own knowledge and competence, pharmacists must develop their skills in-line with their area of expertise, keeping up-to-date with relevant progress through CPD (see Ch. 6). In relation to the provision of medicines-related information to those who want or need it, pharmacists are expected to be able to provide accurate, reliable, impartial, relevant and up-to-date information. Yet with thousands of medicinal products, dressings and appliances on the UK market, pharmacists are highly unlikely to hold in-depth knowledge of all health- and medicines-related issues at all times. Therefore, the ability to retrieve relevant health- and medicines-related information in a timely and efficient manner becomes central to the practice of all pharmacy professionals (Box 16.1). Information retrieval is the tracing and recovery of stored information. Information can range from patient information to drug monographs, to more sophisticated health technology assessments. It can exist in many forms from the archives of a drug company to the worldwide web. Effective information retrieval requires an understanding of the range of relevant information available, where it exists and how it might be sourced. Table 16.1 provides a list of some of the established health-related websites, although web addresses or pathnames can change or more useful sites can be created. To help order the directory, similar websites are grouped together. The list is not exhaustive and it should be used as a starting point. Hyperlinks provide a way of finding and bookmarking useful websites. Websites normally have a directory of related websites as ‘links’. There are also innovations such as the social bookmarking website http://delicious.com/, which provides a means of storing personal bookmarks online instead of within the browser, thus enabling bookmark information to be accessed and shared online. A variety of websites concentrate on providing internet search facilities. Some are set up as web portals with the aim of providing a complete resource for everything on the web that they consider to be worthwhile. Portals display their own editorial material, news headlines and other up-to-date information, as well as links to commercial partners and paid advertisements. They are good for general or commercial information but most will fail to identify websites for non-profit organizations, such as the NHS. Web portals also provide a search facility. Search engines attempt to search all the text on all the pages of the web. Software seeks out and indexes web pages, storing the results in sizeable databases. When a user types a query, the search engine searches its database for pages that contain words matching the query and displays the results as a list of links (Box 16.3). Each search engine ranks results according to its own criteria and so different search engines can give different results for the same query. Before beginning a new search, the user should take time to consider what they already know, knowledge gaps and information required. It is advisable to have a plan that focuses the search. The user should select a set of keywords that best reflect the information need and narrow the search to a particular subject or topic. Results should be compared to the original information need. If appropriate material is found on the first page of the search then the activity need go no further. It is important to know when to stop searching, especially when there is limited time. There is no restriction on what is placed on the web or by whom. There is certainly no process of editorial or peer review for material placed on the web. Apart from the Advertising Standards Authority, which recently gained the authority to regulate marketing material on UK websites, no UK organization is currently responsible for regulating health- and medicines-related information on the internet. Under these conditions, there is always the danger that an internet site contains incomplete, inaccurate, irrelevant, obsolete or even hoax information. As a result, the utmost care should be taken in making use of health-related information from the internet. An informed approach must include a system for evaluating the quality of the information found against the intended use of that information. Factors listed below can all affect the quality of an information source; they are not mutually exclusive and must be considered in combination (see Table 16.2). Table 16.2 Evaluating the quality of an internet-based website for health- and medicines-related information
Information retrieval in pharmacy practice
 How to categorize health- and medicine-related information
How to categorize health- and medicine-related information
 Relevant search and retrieval processes
Relevant search and retrieval processes
 Organizations that can help with information retrieval
Organizations that can help with information retrieval
Introduction
Where does information exist and how can it be retrieved?
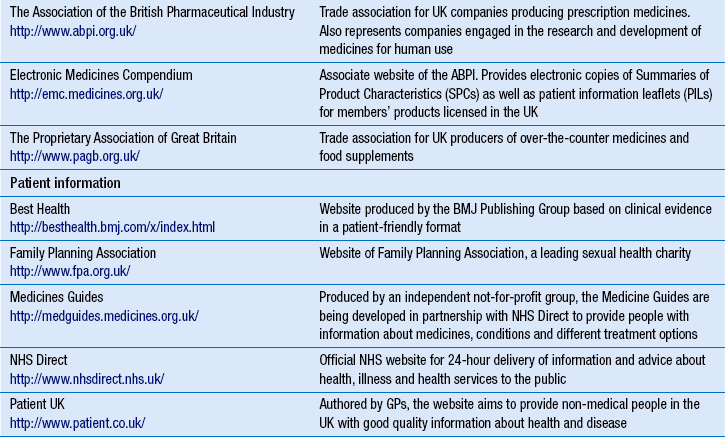
Directory of useful websites
Bookmarking
Searching the internet
Commercial search engines
Effective use of search engines
Assessing the quality of information on the web
Activity
Purpose
Follow internal links
To find out as much as possible about the resource, e.g. the scope of the material; the intended audience and coverage; the origin of the information; who is responsible for the content; involvement of others in the production of material; any access restrictions
Analyse the URL
To find out where the information comes from and to judge if they are qualified to provide the information, e.g. the individual or group that has taken responsibility for the website
Examine the information contained
To find out the subjects and types of materials covered; comprehensiveness of coverage; notable omissions; notable indicators of accuracy; editorial procedures; research basis to the information; creation date; the frequency and/or regularity of any updating
Consider the presentation
To find out if the resource is frequently unavailable or noticeably slow to access; any access restrictions (e.g. by geographical region, hardware/software requirements); whether there is a registration procedure and whether this is straightforward; whether the available content is free or subscription based; the copyright statement and copyright restrictions; whether the site is particularly difficult or easy to use; presence or absence of user support facilities and/or help information
Obtain additional information
To find out if an individual or group has taken responsibility for the website; whether they are qualified to provide this information; whether the resource is well known (e.g. recommended via links), reviewed and/or heavily used
Compare with other similar websites
To find out if a resource is unique in terms of content or format and any differences between mirror and original sites for the same materials ![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Information retrieval in pharmacy practice









Only gold members can continue reading. Log In or Register to continue
