Chapter Three. Structure, organisation and regulation of genes
Introduction
‘Life depends on the ability of cells to store, retrieve and translate the genetic instructions to make and maintain a living organism’ (Alberts et al 2002). Over the last decade there have been major developments in the science of genetics. The finding that there is a genetic basis for many aspects of human disease has led to the search for treatments. The research has involved the Human Genome Project which was undertaken to identify the structure and function of all human genes. The study of the human genome is called genomics.
With the completion of mapping the human genome in the year 2000 ethical and moral implications became apparent. The rate of development of industries based on recombinant gene technology, cloning and gene therapyhas been so fast that the general public and the government have found it difficult to understand the implications. This has led to a sense of fear and distrust of technologies such as genetically modified (GM) foods.
Key discoveries
In 1865 a monk called Gregor Mendel presented a paper on the results of his experiments with garden peas. He had studied varieties of pea that differed in a single characteristic, such as tall and short plants or wrinkled and smooth seeds. He found an inheritance pattern where one of two characteristics—for example tall plants—seemed to dominate the next generation (i.e. the first filial (F1) generation) and these were called dominant factors. The opposite characteristic—short plants—disappeared, to reappear in the ‘grandchildren’ (the second (F2) generation); these were called recessive factors.
Mendel proposed that each pair of characteristics was controlled by a pair of factors, one of which was inherited from each parent plant. These factors were called genes by the Danish botanist Johannsen (Turnpenny & Ellard 2007). Pure-bred pea plants were homologous (‘homo’ means alike) and inherited two identical genes from their parents. The F1 generation resulted from the breeding of a tall plant with a short plant and were all tall plants. However, they inherited two different genes from their parents and were heterozygous (‘hetero’ means different). The alternative versions of genes are called allelomorphs, usually shortened to alleles.
Mendel’s laws
Out of Mendel’s work three main principles were developed:
1. The Law of Uniformity. When two homozygotes with different alleles are crossed, all the offspring of the F1 generation are identical and heterozygous. Characteristics do not blend and can reappear in subsequent generations.
2. The Law of Segregation. Each individual possesses two genes for a particular characteristic, only one of which can be passed on in the ovum or sperm to the next generation.
3. The Law of Independent Assortment. Members of different gene pairs segregate to offspring independently of one another.
The third law is not strictly true, because if two genes are situated closely together on the same chromosome (see below) they may be linked and inherited together.
Mendel’s findings were ignored until 1900, but, once the importance of his experiments was recognised, interest in inheritance developed. At that time thread-like structures had been seen in the nuclei of cells. These were the chromosomes and in 1903 two people independently proposed that they carried the hereditary factors known as genes. However, it was only in 1952 that deoxyribonucleic acid (DNA) was identified as the universal genetic material. In 1953, the structure of DNA was discovered by James D Watson and Francis HC Crick. However, without Rosalind Franklin, who revealed the power of X-ray crystallography, their discovery might not have occurred (Sayre 2000). The correct number of 46 human chromosomes was identified in 1956.
Composition of DNA
Building blocks
Cell nuclei contain large amounts of species-specific DNA. A second form of nucleic acid is ribonucleic acid (RNA). Nucleic acids are long polymers of molecules called nucleotides, which are composed of several simple chemical compounds bound together in a regular pattern. These building blocks are phosphoric acid, a pentose sugar with five carbon atoms called deoxyribose and four nitrogenous bases. These bases comprise two purines ( adenine and guanine) and two pyrimidines ( thymine and cytosine) identified by the single letters A, G, T and C. In RNA thymine is replace by uracil (U).
RNA is found in the cytoplasm, particularly concentrated in the nucleolus, whereas DNA is found mainly on the 46 chromosomes which are arranged in 23 pairs in somatic cells. One chromosome of each pair originates from the ovum and the other from the sperm. A cell containing two sets of chromosomes is described as diploid. Gametes are haploid, containing one of each pair of chromosomes. In 22 of the pairs the chromosomes are identical; these pairs are called autosomes. The two chromosomes are termed homologous. The 23rd pair is the sex chromosomes: two X chromosomes in females and an X and a Y chromosome in males. Maternal and paternal chromosomes become closely apposed during meiosis and exchange segments of DNA between homologues, a phenomenon called crossing over.
The double helix
DNA molecules consist of a double helix made up of two complementary chains of nucleotides. Two sugar-phosphate strands wind around each other and the base pairs are stacked between these strands, pointing inwards to the centre of the double helix (Turnpenny & Ellard 2007). The two chains are held together by hydrogen bonds between the base pairs. These bonds are easily broken, a feature necessary for DNA replication. The sugar-phosphate molecules form the backbone of the chains.
Pentose sugars
The five carbon atoms in the pentose sugar are numbered with primes, represented as 1′to 5′. The carbon atoms 3′ to 5′ are on the same side of the molecule. The 5′ carbon is always linked to the phosphate molecule and the 1′ carbon to the base. The two strands run in opposite directions as indicated by their 3′ and 5′ carbon atoms and are complementary or antiparallel (Fig. 3.1). A purine always pairs with a pyrimidine. A is paired with T by two hydrogen bonds and C is paired with G by three hydrogen bonds. The pairs stack one above the other and the structure is stabilised by two other forms of bond—hydrophobic and van der Waals interactions (Ch. 1)—between adjacent pairs.
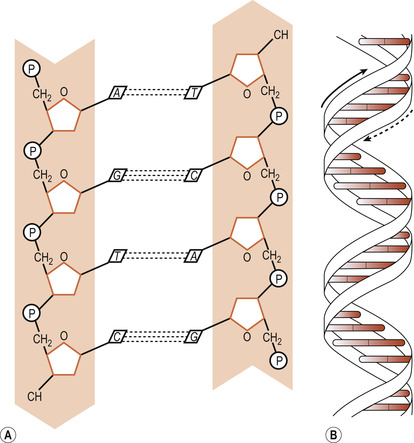 |
| Figure 3.1 DNA double helix. (A) Sugar phosphate backbone and nucleotide pairing of the DNA double helix (P, phosphate; A, adenine; T, thymine; G guanine; C, cytosine). (B) Representation of the DNA double helix. |
DNA holds the instructions for constructing, organising and maintaining the body and must be replicated accurately during mitosis (Ch. 2). One of the two strands must be passed on to the next generation by means of ova and sperm.
Chromosomes
Chromosomes take up different states depending on the stage of the cell cycle (Ch. 2). When the cell is not dividing, chromosomes are extended and their chromatin is in the form of long, thin tangled threads known as interphase chromosomes. The highly condensed chromosomes in a dividing cell are called mitotic chromosomes (Alberts et al 2002), which are much wider than the DNA double helix.
If the DNA of a single human cell were to be stretched out it would be several metres long, yet the total length of the chromosomes placed end to end is less than 0.5 mm. DNA is packaged into chromosomes by coiling and folding (Turnpenny & Ellard 2007). Besides the double helix there is a secondary coiling around spherical molecules called histones to form nucleosomes. A tertiary coiling of nucleosomes forms the chromatin fibres which are then wound into a tight coil to make the chromosomes.
Circulating lymphocytes from peripheral blood are commonly used to study chromosomes but skin or bone marrow cells can be used. Fetal cells from the chorionic villi or found in amniotic fluid ( amniocytes) can be sampled. The process of cell division is stopped during mitosis by adding colchicines, which prevents the formation of the spindle and arrests the cells in metaphase. Hypotonic saline solution is added, which destroys the cells, releasing the chromosomes. A photograph is taken. The chromosome images are cut out, laid out in a standard fashion, and photographed again to produce a karyotype (Fig. 3.2). Chromosomes are identified by their size, light and dark banding patterns and the position of the centromere.
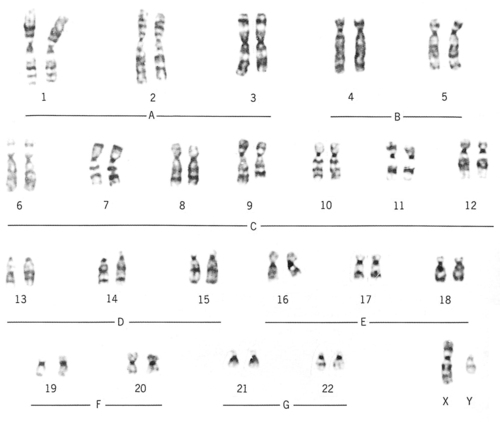 |
| Figure 3.2 A normal karyotype. (From Henderson C, Macdonald S 2004, with kind permission of Elsevier.) |
At that moment DNA replication has taken place and the chromosomes consist of two identical strands called sister chromatids which are held together by a centromere. Centromeres consist of lengths of repetitive DNA and are responsible for the movement of the chromosomes that takes place in cell division. A chromosome is divided by its centromere into short and long arms. The short arm is referred to as ‘p’ and the long arm as ‘q’. Chromosomes can be classified by the position of their centromeres. If located centrally the chromosome is metacentric, if intermediate it is sub-metacentric and if found at one end of the chromosome it is acrocentric. Acrocentric chromosomes may have stalks with satellites attached to them which contain multiple copies of the genes for ribosomal RNA.
The tip of each chromosome arm is called the telomere, consisting of many repeats of a TTAGGG sequence which seals the ends of the chromosome to maintain its structural integrity. The length of these sequences is reduced each time the cell divides. This is part of normal cellular ageing; most cells can only undergo 50–60 divisions before becoming senescent.
Genes
The full complement of DNA is called the genome. Along the genome about 60–70% of DNA is in the form of single or short repeats of single sequences called low copy sequences, whereas 30–40% consists of highly repetitive sequences that appear inactive. DNA is arranged in discrete segments called genes and there may be 25 000–30 000 (far less than was originally conjectured) of these in the human genome. There is a rule of genetics that says ‘one gene, one protein’. However, genes often exist in families; for example, those that code for the various types of haemoglobin (Ch. 16) and those that code for antibodies (Ch. 29).
Genes code for polypeptides, which include enzymes, hormones, receptors and structural and regulatory proteins (Turnpenny & Ellard 2007). The alternative alleles of any gene are present at a specific place or locus on each of a pair of chromosomes. If both parents contribute an identical allele for a locus, the new individual is homozygous. If the two alleles differ, the new individual is heterozygous.
Discrete single genes form about 25% of the DNA and are separated from each other by long runs of inactive, repetitive DNA sequences. It is not known why there is so much redundant DNA. The coding sequences of genes are called exons and the intervening non-coding sequences introns. Exons are usually interrupted by introns. Individual introns can be much larger than the exons and some have been found to contain a gene within a gene.
The role of the environment
Genes act in response to environmental changes (Ch. 15). These may be internal, such as a response to fluctuations in hormone level, or external, such as a response to a meal. The full range of genes inherited by an individual is called the genotype. The outward appearance of an individual, i.e. their physical, biochemical and physiological nature, is known as the phenotype and results from gene–environment interactions.
From DNA to RNA to protein
Proteins are the working components of the cell. DNA stores the information. RNA (Fig. 3.3) carries out instructions encoded in DNA and synthesises the proteins involved in cellular function (Jorde et al 2006).
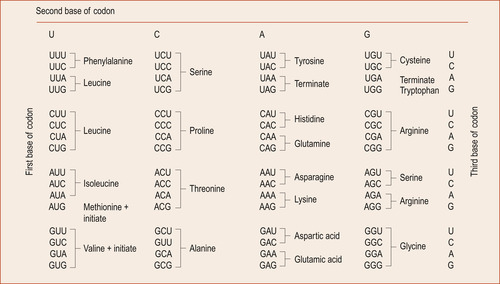 |
| Figure 3.3 Messenger RNA (mRNA) code words. (From Hinchliff S M, Montague S E 1990, with kind permission of Elsevier.) |
The genetic code
Twenty different amino acids are found in proteins, so it became obvious to Watson and Crick that, as there were only four bases, more than one base must be necessary to specify a particular amino acid. Even two bases would not be enough as 4 2 gives only 16 possibilities. However, 4 3 bases allows 64 possibilities of codon to occur with some redundancy. Each group of three nucleotides, called a triplet codon (Fig. 3.4), spells out each amino acid. The sequence of amino acids shapes a particular protein. There are also codons at the ends of genes that signify start and stop. The process of reading the DNA code which results in a functional protein product involves two processes: transcription and translation.
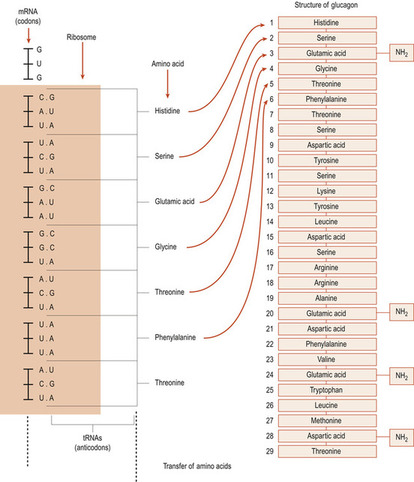 |
| Figure 3.4 An example of protein synthesis: glucagon. (From Hinchliff S M, Montague S E 1990 with kind permission of Elsevier.) |



