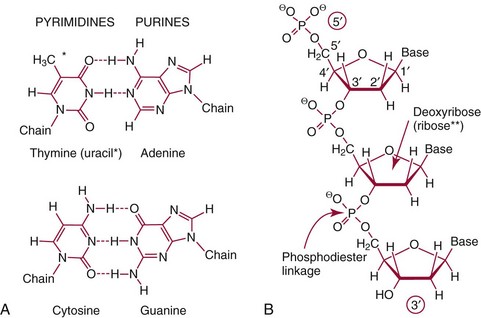
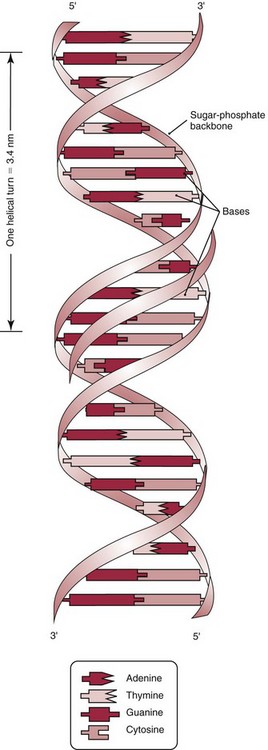
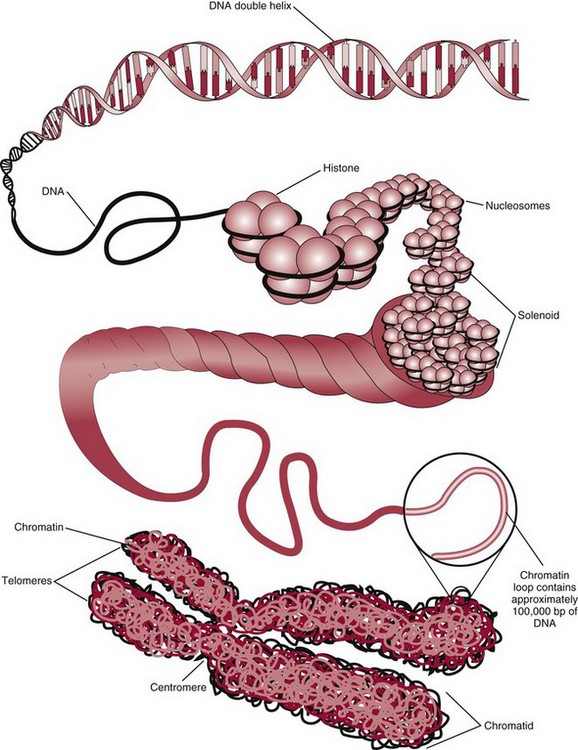
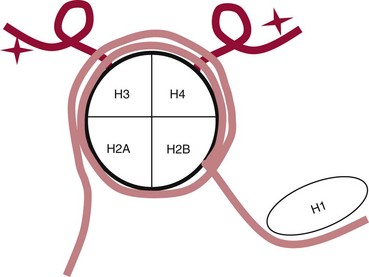
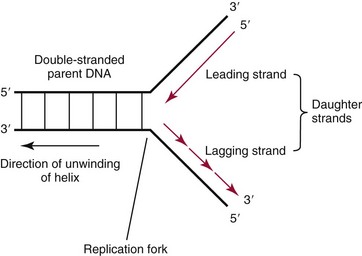
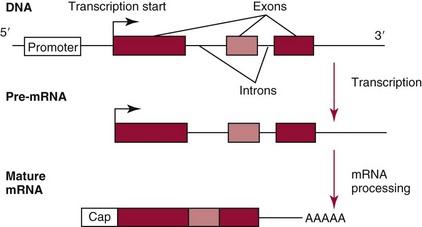
Chapter 37 Rossa W.K. Chiu, M.B.B.S., Ph.D., F.H.K.A.M.(Pathology), F.R.C.P.A. and Y.M. Dennis Lo, M.A., D.M., D.Phil., F.R.C.P.,(Lond. & Edin.), F.R.C.Path., F.R.S. Molecular diagnostics represents one of the most rapidly developing areas in clinical chemistry. Advances in the field have been made possible by our improved understanding of molecular biology and genetics and of their relationships with human diseases, and by the development of powerful technologies for analysis of nucleic acids.21 The chapters in this section attempt to provide an overview of important advances in molecular diagnostics. Fundamental concepts in molecular biology are reviewed in this chapter. Molecular diagnostic techniques are discussed in Chapters 38 and 39. The subsequent chapters focus on key areas of molecular diagnostics, specifically, inherited diseases (see Chapter 40), identity assessment (see Chapter 41), infectious diseases (see Chapter 42), pharmacogenetics (see Chapter 43), and hematologic malignancies (see Chapter 44). Last, molecular diagnostic applications based on analysis of plasma nucleic acids are discussed in Chapter 45. Amazing developments in biotechnology have taken place in the late twentieth century. For example, we have witnessed dramatic progress in sequencing of the human genome, cloning of organisms, and progress in stem cell research and gene therapy. Many of these advances would not have been possible without the many earlier landmark discoveries that unveiled the mysteries of genetics and paved the way for modern molecular diagnostics.32 Genetics began modestly when Mendel experimented with garden peas. His findings, published in 1866 and suggesting the concepts of alleles and genes as units of heredity, essentially captured the most fundamental concepts in inheritance. In 1910, Morgan revealed that the units of heredity are contained within chromosomes, but it was Avery in 1944 who confirmed through studies on bacteria that it was DNA that carried the genetic information. Franklin and Wilkins studied DNA by x-ray crystallography, which subsequently led to unraveling of the double-helical structure of DNA by Watson and Crick in 1953. In the 1960s, Smith demonstrated that DNA can be cleaved by restriction enzymes, which Arber had discovered earlier; this facilitated the subsequent development of recombinant DNA technologies. Nathans furthered the work on restriction enzymes and was the first to construct a genetic map. In 1975, the Southern blot was invented, which allowed the detection of specific DNA sequences. Soon after, in 1977, DNA-sequencing methods were developed, and the first complete DNA sequence of an organism, a bacteriophage, was published. Cloning of the first human gene mutation, a β-thalassemia mutation, was achieved by Orkin and associates in 1980. Prenatal genetic diagnosis of sickle cell disease was shown to be feasible by Chang and Kan in 1981. Mullis and coworkers developed the polymerase chain reaction in 1985. The existence of functional small noncoding RNAs (ncRNAs) in organisms was first realized in 1993. DNA microarrays, which allow the simultaneous interrogation of many DNA/cDNA loci by nucleic acid hybridization, became a reality in 1996. Remarkably, the draft human genome sequence was released in 2001 and completed in 2003.33,60 Massively parallel genomic sequencing became an accessible laboratory tool from 200541 and vastly accelerated the pace of molecular biology research in a way that was not achievable before. On the simplest level, genes can be defined as segments of deoxyribonucleic acid (DNA) that encode for proteins or ribonucleic acid (RNA) products with biological functions. DNA is a biological substance that carries genetic information and is a polymer of nucleotides or bases. Genetic information is reproduced from parent to daughter cells during cell division through the process of DNA replication. When genes are expressed (“switched on”), the DNA sequence is transcribed into RNA. RNA molecules (RNAs) are polymers of ribonucleotides that exist in a number of functional forms. RNA molecules that act as intermediates for protein production are termed messenger RNA (mRNA). RNA molecules that serve a direct biological function without coding for a protein are collectively termed ncRNAs.58 mRNA is the product of a transcribed nucleotide sequence and is in turn translated into a protein, which is a polymer of amino acids. Each amino acid is encoded by a triplet nucleotide code, termed a codon. The human genetic code comprises 64 codons encoding for 21 amino acids and 3 stop codons. mRNA codons are read by the anticodon regions of transfer RNA (tRNA) molecules, which are small RNAs that bring the corresponding amino acid to the growing polypeptide chain. The polypeptide chain is synthesized by ribosomes, which are macromolecular complexes containing ribosomal RNA (rRNA) and a protein component with catalytic function. The physicochemical properties and functions of nucleic acids are largely governed by the compositions and structures of DNA and RNA. A single molecule of DNA is a polymer consisting of a backbone of invariant composition and side groups arranged in a variable sequence (Figures 37-1 and 37-2). The polymer is synthesized from monomers (nucleotides) composed of the sugar deoxyribose, a phosphate residue, and a purine or pyrimidine base. The purines are adenine (A) and guanine (G), and the pyrimidines are cytosine (C) and thymine (T) (see Figure 37-1). The four nucleotide building blocks of DNA are abbreviated dATP (deoxyadenosine-triphosphate), dGTP (deoxyguanosine-triphosphate), dCTP (deoxycytidene-triphosphate), and dTTP (deoxythymidene-triphosphate), respectively. Nucleotides are joined by phosphodiester bonds that link the 5′-phosphate group of one to the 3′-hydroxyl group of the next (see Figure 37-2). No 3′-3′ or 5′-5′ linkages are present; thus the sugar and phosphate moieties compose the nonspecific portions of the molecule. The sequence of the bases varies from molecule to molecule and uniquely identifies each DNA polymer, which, as discussed later, determines the identity and function of the protein or RNA products that the DNA encodes. Although the purines and pyrimidines are of different compositions and sizes, when in the proper orientation, adenine forms two hydrogen bonds with thymine, and guanine forms three hydrogen bonds with cytosine, to form planar structures of similar dimensions (see Figure 37-1). This combined with the fact that the base portion of each nucleotide is hydrophobic contributes to the energetically favorable secondary structure of DNA as it is found in its native form: a right-handed, double-stranded helix. The planar base pairs stack in the inside of the helix, 10 bases per turn, whereas the hydrophilic sugar-phosphate backbone forms noncovalent bonds with surrounding water molecules. For the two DNA polymers to form the proper hydrogen bonds between the bases, two requirements must be fulfilled: the polymers must run in opposite directions (antiparallel) as defined by the free hydroxyl groups at each end (3′-5′ vs. 5′-3′), and the sequences of each molecule must be such that A : T and G : C hydrogen bonds are always formed (base pairing). Two DNA strands that meet this requirement are called complementary. RNA is chemically very similar to DNA but differs in important ways. The sugar unit is ribose with an added hydroxyl group at the 2′ position, and the methylated pyrimidine uracil (U) replaces thymine. RNA exists in various functional forms but mostly as a single-stranded polymer that is much shorter than DNA and that has an irregular three-dimensional structure. Despite their irregular shape, RNA conformations are not random structures, and the folding mechanism of RNA molecules is complex.1,53 The secondary structure adopted by an RNA molecule is to a large extent related to its nucleotide sequence. RNA molecules fold sequentially from 5′ to 3′ to form stable submotifs dictated by their primary sequence. One such example is the hairpin loop structure of precursor miRNAs (see below section on ncRNAs). RNA molecules may adopt further tertiary folding. An RNA molecule has the potential to be folded into a number of different conformations, but usually only one conformation is functional.53 The folding process is influenced by ions, cofactors, and proteins.1 Once an RNA molecule adopts a conformation most favored by its immediate cellular environment, it rarely switches to another conformation.1 RNA molecules can further interact with other RNA or protein molecules to form complex quaternary structures, such as ribonucleoproteins, that are essential to certain cellular processes. DNA molecules are extremely long and in the eukaryotic cell are maintained in orderly and compact three-dimensional structures. Each diploid human cell contains two full sets of the human genome, with each copy consisting of approximately 3.2 billion nucleotides. This vast amount of genetic material is organized into 23 homologous chromosome pairs, with each pair contributed by a homolog of maternal origin and one of paternal origin. The two chromosomes of each pair are similar (homologous) and, except for the sex chromosomes (X and Y), contain the same genes arranged in the same sequence. Each chromosome is a highly ordered structure of a single dsDNA molecule, compacted many times with the aid of structural DNA-binding proteins, for example, histones (Figure 37-3). The chromosomes are in their most compact state and appear as finger-like structures during metaphase of the cell cycle. A primary constriction, the centromere, is also notable on each chromosome (see Figure 37-3). The ends of the chromosomes are termed the telomeres (see Figure 37-3). Both centromeres and telomeres have specialized functions, which are discussed later. The nonsex chromosomes, the autosomes, in the human genome are numbered in order of decreasing size (except chromosomes 21 and 22). Chromosome 1 is 250 Mbp long, and chromosome 21 is 48 Mbp long. The chromosomal arrangement of human DNA not only allows packaging of the vast human genome into the limited physical dimensions of the cell nucleus, but also governs one of the mendelian laws of inheritance on independent assortment whereby genes located on different chromosomes recombine at random from one generation to the next. Nuclear DNA in conjunction with its associated structural proteins, including histone and nonhistone proteins, is known as chromatin. Chromatin is arranged and organized in a hierarchical fashion whereby the degree of packing or condensation increases with higher levels of structural organization.9,23,51 The nucleosome represents the most basic level of chromatin organization and is present as repeated units along the full length of each chromosome. Each nucleosome unit consists of a nucleosome core particle and 20 to 80 base pairs of linker DNA, which spans between adjacent nucleosomes, resembling what has been referred as “beads on a string” (Figure 37-4). A nucleosome core particle involves 147 base pairs of dsDNA tightly wound 1.65 times around an octamer of histone proteins, two each of four histone proteins, namely, H2A, H2B, H3, and H4.9,23 Amino termini or “tails” of these histone molecules protrude from the nucleosomal core. The histone tails are subjected to covalent modifications, including acetylation, methylation, phosphorylation, and ubiquitination.34 The linker DNA segments are associated with the linker histone H1. Nucleosomes are further packed in successive levels of complexity by up to a factor of 10,00023; in the most compact stage, chromatin appears as discrete mitotic chromosomes seen in the metaphase of a cell cycle, as described earlier. The orderly process of chromatin condensation involves DNA methylation, histone modifications, ncRNAs, and sequence-specific DNA binding proteins. Chromatin packing serves the function of containing the genome within the nucleus, but this could potentially render the genetic code inaccessible to various cellular machineries.23 However, this is not the case because chromatin condensation is not a static process but a dynamic one that changes in a coordinated fashion during the cell cycle. In general, chromatin is much less condensed during interphase, at which time DNA is replicated. The extent of chromatin condensation during interphase varies among regions of the genome. Genomic regions that are rich in genes generally open up to become less compactly organized during interphase and are termed euchromatin. Regions that are gene-poor or that span transcriptionally silent genes remain mostly densely packed and are called heterochromatin. Heterochromatin is important for maintenance of specialized chromatin structures, inactivation of the X chromosome in females, and maintenance of genome stability by stabilizing repetitive DNA sequences.19,30 Eukaryote chromosomes contain two specialized regions of heterochromatin, namely, centromeres and telomeres. Centromeres play an important role in directing the movement of chromosomes between daughter cells during cell division.2 Poor execution of this process could result in incorrect segregation of chromosomes, leading to chromosomal gains or losses in the daughter cells. Telomeres contain repetitive nucleotide sequences that are located on and protect the ends of chromosomes. Alterations in the lengths of telomeres contribute to aging and cancer development.5 Genomic regions that remain condensed during the cell cycle, such as centromeres, telomeres, and the inactivated X chromosome in female cells, are termed constitutive heterochromatin. On the contrary, some other heterochromatin domains are scattered throughout the genome and are able to respond dynamically in various cellular states. Those regions are termed facultative heterochromatin and are associated with regulation of gene expression.19,30 Functional implications of the structural organization of chromatin will be discussed further in the following sections. Each time a cell divides, the entire DNA content of that cell must be faithfully duplicated, so that the total complement of hereditary information (the human genome) is retained in each daughter cell. This process is called replication. Owing to the laws of base pairing (i.e., adenine pairs only with thymine, and guanine only with cytosine), the sequence of a single strand of DNA dictates the sequence of its complementary strand. In replication, each of the two parent strands of a dsDNA molecule serves as the template for the synthesis of a daughter strand (Figure 37-5). The process is called semiconservative because each of the duplicated dsDNA molecules produced in this manner is composed of one parent (conserved) strand and one daughter strand. For replication to occur, the original double-stranded helix must be separated. This is an energetically unfavorable event that is accomplished with a combination of DNA-specific proteins and enzymes, and synthesis of both daughter strands proceeds as the parent strands separate. Replication is initiated at multiple sites (origins of replication) during this process, but each origin of replication is used only once during a single cell cycle. Daughter strands are synthesized by DNA polymerase III, an enzyme that reads the parent template and attaches nucleotides to the growing daughter strand according to the base pairing rules of dsDNA. DNA polymerase III begins synthesis at the replication fork (see Figure 37-5), the point of strand separation, with a short RNA primer that base pairs to the parent template. Later, this primer is excised and replaced with DNA by the DNA repair enzyme, DNA polymerase I. Because DNA polymerase III synthesizes DNA only in the 5′-3′ direction, one daughter strand, the leading strand, is synthesized continuously, whereas the other, the lagging strand, must be synthesized discontinuously in short segments (see Figure 37-5). Fragments on the discontinuous strand are then joined by the DNA ligase enzyme. Many other proteins are involved in unwinding and stabilizing the parent strands for synthesis, in protecting single-stranded regions, in recognizing initiation sites, and in synthesizing the RNA primer. In addition to synthetic capabilities, the DNA polymerases possess an exonuclease or “proofreading” function: when an incorrect nucleotide is added to the growing polymer, a conformational change brings the chain in contact with the exonuclease portion of the enzyme, which cuts out (“excises”) the incorrect nucleotide. This helps maintain the integrity of the original DNA sequence. In fact, it has been estimated that one nucleotide error could occur for every 105 nucleotides incorporated into the growing strand. However, the proofreading function of DNA polymerase works in concert with a set of DNA repair mechanisms that detect and correct DNA replication errors in such a way that the resultant error rate of DNA replication is reduced to one error per 109 to 1010 nucleotides replicated.39 Given that 3 billion base pairs are present in the human genome, about 0.3 to 3 errors occur per cell division. DNA carries information that specifies the production of RNA molecules and proteins that can execute biological functions. The segment of the genome that specifies the production of a functional product, that is, a protein or ncRNA, is termed a gene. In short, a gene is a functional unit of the genome. On the most basic level, the span of a gene encompasses the nucleotide sequence that specifies its ncRNA product or the amino acid sequence of its protein product. However, a series of processes determines the timing and rate of expression of each gene. Those processes that control gene expression act via regulatory regions of the genome. Thus, it is customary to define a gene to be inclusive of such associated regulatory elements.17,49 An important regulatory region is the promoter of a gene, which, as will be discussed later, is the genomic region where regulatory factors act in concert to activate expression of said gene. Previously, it was generally thought that the promoter region laid immediately 5′ to the start of the protein-coding portion of a gene. Yet, recent evidence demonstrates that regions showing properties of a promoter could be found within the protein-coding portion of genes, toward the 3′ end, or lying at a substantial distance between coding sequences.28 In addition, the same promoter region could trigger the expression of different DNA segments both 5′ or 3′ to it.28 Hence, it has become increasingly difficult to precisely define the physical boundaries of individual genes.17,49 When a gene is expressed, the DNA sequence is first transcribed into RNA. The process of transferring the sequence information from DNA to RNA is called transcription. Regulation of transcription is the primary mechanism that cells use to control gene expression.59 Similar to replication, transcription requires separation of duplex DNA strands and uses a polymerase to copy the template DNA strand. For transcription, the polymerase is RNA polymerase II, which first binds to specific sequences in the promoter, called the core promoter, upon initiation of gene expression. Core promoters that have been identified to date generally occur within a hundred bases around the initiation site of transcription, known as the transcription start site, where the first ribonucleotide unit is paired with the template DNA (uracil pairs with adenine). Several nucleotide sequence motifs or patterns have now been recognized among core promoters.26 For example, one of the best studied core promoter motifs, the TATA box, refers to a short stretch of nucleotides rich in thymine and adenine in repeating patterns. It is typically located between 24 to 31 nucleotides “upstream” (i.e., at the 5′ end) of the transcription start site.59 Some other core promoter elements are located just downstream to the transcription start site. Research has suggested that the various core promoter elements may have different strength and efficiency in activating gene expression.59 To initiate transcription, a series of protein cofactors, known as general transcription factors, is required to bind to RNA polymerase II to form an assembly known as the preinitiation complex, which, in turn, acts on the gene by interacting with the core promoter.59 Other regions of DNA known as activators or coactivators may interact with the preinitiation complex to stimulate or repress transcription. Once transcription is activated, RNA polymerase II moves along and unwinds the DNA double helix. The growing RNA transcript pairs with one of the DNA strands, called the template, where RNA polymerase II adds complementary ribonucleotide triphosphates in a 5′ to 3′ direction. It is now known that both DNA strands of the double helix can act as the template for RNA transcription.4 For example, when the growing RNA transcript pairs with the antisense (−) DNA strand, the resultant RNA molecule is a copy of the sense (+) strand of DNA, and vice versa. Natural antisense transcripts (i.e., RNA transcripts that are copies of the antisense DNA strand) have been better known only in recent years.45 Both protein-coding and non–protein-coding RNAs have been reported to be natural antisense RNAs.14 RNA elongation continues until chain termination occurs. The precise signaling mechanism for chain termination still is not well understood. The RNA transcript quickly detaches from the template DNA because restoration of the DNA-DNA duplex is energetically more favorable than is retention of the DNA-RNA hybrid or a segment of single-stranded DNA. The newly synthesized RNA molecule then undergoes further modification depending on its functional class. We shall discuss the fate of the ncRNAs in a later section of this chapter. Here we focus on describing subsequent processing of the protein coding RNAs, which are referred to as mRNA. First, the 5′ end of the RNA molecule is modified by the addition of 7-methylguanosine residues to form a structure called a cap (Figure 37-6). The 3′ end is modified by the addition of multiple adenine bases, called the poly(A) tail (see Figure 37-6). Both the cap and the tail are necessary for translation of mRNA into protein, and they protect the mRNA molecule from degradation by exonucleases. The coding region of a gene (i.e., segments that will contribute to the amino acid sequence of the protein) is divided into segments called exons interspersed with noncoding regions termed introns (see Figure 37-6). The number and size of introns and exons differ among genes. Excision or splicing of the noncoding introns is carried out by a molecular complex termed a spliceosome. These complexes are composed of multiple small nuclear ribonucleoprotein particles. Spliceosomes mediate the cleavage and ligation of RNA at specific recognition sequences, termed splicing donor and acceptor sequences. After the introns have been removed, the exons are juxtaposed to each other, forming a mature mRNA molecule (see Figure 37-6) that is transported into the cytoplasm, where protein translation takes place.
Principles of Molecular Biology
Landmark Developments in Genetics and Molecular Diagnostics
The Essentials
Nucleic Acid Structure and Organization
Molecular Compositions and Structures of DNA and RNA
RNA
Chromosome Structure
Chromatin Packing
Nucleic Acid Physiology and Functional Regulation
Replication
Transcription
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Principles of Molecular Biology