Genetics and Heredity
LANGUAGE OF SCIENCE
 Before reading the chapter, say each of these terms out loud. This will help you avoid stumbling over them as you read.
Before reading the chapter, say each of these terms out loud. This will help you avoid stumbling over them as you read.
[chrom- color, -som- body, terri- land, -ory place]
[co- together, –domina- rule, -ance state]
[diplo- twofold, -oid form of]
[epi- upon, gen- produce, -ic relating to]
[gene- produce, -ic relating to, muta- change, -ation process]
[gen- produce, -ic relating to]
[gen- produce (gene), -ome entire collection]
[gen- produce (gene), -om- entire collection, -ic relating to]
[gen- produce (gene), -type kind]
[haplo- single, -oid of or like]
[hetero- different, -zygo- union or yoke, -ous characterized by]
[homo- same, -zygo- union or yoke, -ous characterized by]
mitochondrial DNA (mDNA, mtDNA)
[mito- thread, -chondrion- granule, –al relating to)
[mono- single, -gen- produce (gene), -ic relating to]
[mono- single, -som- body (chromosome), –y state]
[nucleo- kernel (nucleus), -som- body]
[pied de grue crane’s foot pattern]
[poly- many, -gen- produce, -ic relating to]
principle of independent assortment
[prote- protein, -ome entire collection]
[prote- first rank (protein), -om- entire collection, -ic relating to]
[Reginald C. Punnett English geneticist]
[q follows p in Roman alphabet]
[recess- retreat, -ive relating to, gene produce]
[trans- across, -script- written document, -ome entire collection]
[trans- across, -script- written document, -om- entire collection, -ic relating to]
LANGUAGE OF MEDICINE
[alb- white, -in- characterized by, -ism state]
[Alois Alzheimer German neurologist]
[amnio- birth membrane, -centesis a pricking]
[an- without, –emia blood condition]
chorionic villus sampling (CVS)
[chorion- skin, -ic relating to, villus shaggy hair]
[chrom- color, -soma- body, -al relating to, gen- produce, -ic relating to]
[cyst- sac, -ic relating to fibr- fiber, -osis condition]
[diabetes passer through or siphon, mellitus honey–sweet]
[John L. Down English physician, syn- together, -drome running or (race)course
Duchenne muscular dystrophy (DMD)
(doo-SHEN MUSS-kyoo-lar DISS-troh-fee)
[hemo- blood, -phil- love, -ia condition]
human engineered chromosome (HEC)
[George S. Huntington American physician]
(hye-per-koh-les-ter-ohl-EE-mee-ah)
[hyper- excessive, -chole- bile, -stero- solid, -ol- alcohol, -emia blood condition]
[Harry F. Klinefelter American physician, syn- together, -drome running or (race)course]
[mal- bad, -ar- air, -ia condition]
(noo-roh-fye-broh-mah-TOH-sis)
[neuro- nerve, –fibr- fiber, -oma- tumor, -t- combining form, -osis condition]
[non- not, -dis- split in two, -junction joint]
[onco- swelling or mass (cancer), –gen- produce or generate]
(os-tee-oh-JEN-eh-sis im-per-FEK-tah)
[osteo- bone, -gen- produce, -esis process, imperfecta not perfect]
[James Parkinson English physician]
[phen- shining (phenol), -yl-chemical, -keton- acetone, -ur- urine, -ia condition]
[RNA ribonucleic acid, i interference, therapy treatment]
[sickle crescent, cell storeroom, an without, -emia blood condition]
[Warren Tay English ophthalmologist, Bernard Sachs American neurologist]
[tumor swelling, suppress- press down, -or agent, gen- produce or generate]
[Harry H. Turner American endocrinologist, syn- together, -drome running or (race)course]
(zeer-oh-DER-mah pig-men-TOH-sum)
[xero- dry, -derma skin, pigment- paint, -osum characterized by]
THE SCIENCE OF GENETICS
History shows that humans have been aware of patterns of inheritance—or heredity—for thousands of years, but it was not until the 1860s that the scientific study of these patterns—genetics—was born. At that time, a monk living in Brno, Moravia (now the Czech Republic) became the first to discover the basic mechanism by which traits are transmitted from parents to offspring. That man, Gregor Mendel, proved that independent units (which we now call genes) are responsible for the inheritance of biological traits.
The science of genetics developed from Mendel’s quest to explain how normal biological characteristics are inherited. As time went by and more genetic studies were done, it became clear that certain diseases also have a genetic basis. As you may recall from Chapter 1, some diseases are inherited directly. For example, the group of blood-clotting disorders called hemophilia can be inherited by children from parents who have the genetic code for hemophilia. Directly inherited diseases are often called “hereditary diseases.” Other diseases are only partly determined by genetics—that is, they involve genetic risk factors (Chapter 1, pp. 25–27). For example, certain forms of skin cancer are thought to have a genetic basis. A person who inherits the genetic code associated with skin cancer will develop the disease only if the skin is also heavily exposed to the ultraviolet radiation in sunlight.
CHROMOSOMES AND GENES
Mechanism of Gene Function
Mendel proposed that the genetic code is transmitted to offspring in discrete, independent units that we now call genes. Recall from Chapters 2 and 4 that each gene is a sequence of nucleotide bases in the deoxyribonucleic acid (DNA) molecule.
Figure 37-1 shows a detailed view of human DNA. Beginning at the left of the diagram, you can see a fully condensed chromosome unfold toward the right, where a single double-helix strand of DNA is visible. As the genetic codes of a DNA molecule’s genes are being actively transcribed in a cell’s nucleus, the DNA is in the threadlike form called chromatin. Chromatin, as you can see in Figure 37-1, is actually a thread of DNA wound around little spools made of proteins called histones. The chromatin is thus organized into little “thread on spool” subunits called nucleosomes.
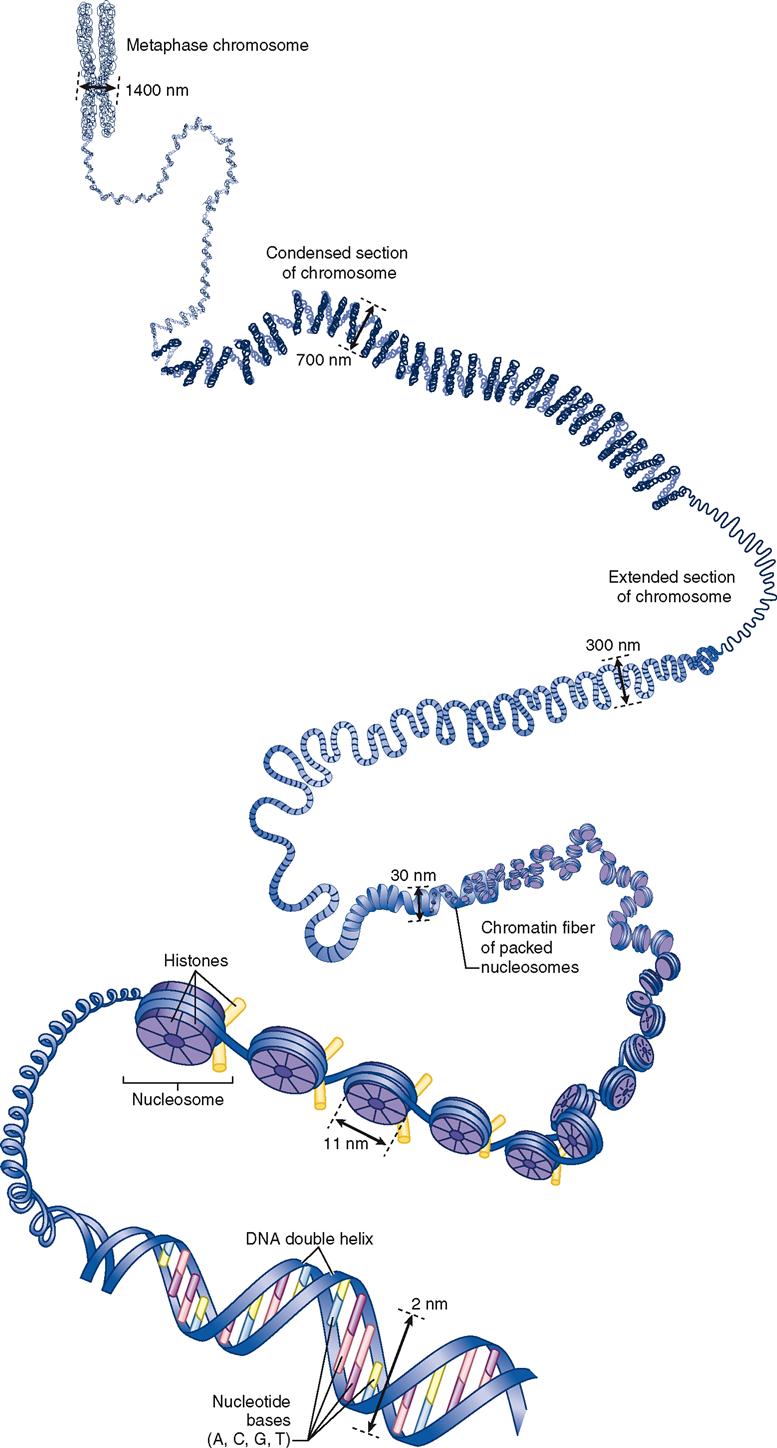
During cell division, each replicated strand of chromatin coils on itself to form a compact chromosome (see Figure 37-1). Each DNA molecule can be called either a chromatin strand or a chromosome, depending on what form it is in. Throughout this chapter we will use the term chromosome for DNA, regardless of its actual form, and the term gene for each distinct encoding segment within a DNA molecule.
In nondividing cells, chromosomes are found in the form of chromatin strands that occupy specific chromosome territories (CTs) within the nucleus. See an example of a CT map in Chromosome Territories online at A&P Connect.

Each gene in a chromosome contains a genetic code that the cell transcribes to a ribonucleic acid (RNA) molecule (see Box 5-2 on p. 120). Some RNA molecules do not code for polypeptides but have a functional role—for example, ribosomal RNA (rRNA) and transfer RNA (tRNA). A transcribed messenger RNA (mRNA) molecule, however, associates with a ribosome in which the code is translated to form a specific polypeptide molecule. By way of slight differences in editing of mRNA, one mRNA may perhaps actually produce several specific polypeptides. And the polypeptides may be complete tertiary proteins by themselves—or they may combine with any of several other polypeptides to form several different specific large quaternary proteins (see Figure 2-28 on p. 54).
Many of the protein molecules formed from the polypeptides encoded by genes are enzymes, functional proteins that help regulate the various metabolic pathways of the body by catalyzing specific chemical reactions. Because enzymes and other functional proteins such as hemoglobin regulate the biochemistry of the body, they regulate the entire structure and function of the body. Some proteins, such as collagen and keratin, are important structural components of the body—and thus determine important structural characteristics of various body parts.
As you can see, genes determine the structure and function of the human body by producing a set of specific structural proteins, along with many functional proteins and RNA molecules.
How many different kinds of amino acids are needed to form the proteins of the body? Find out in Amazing Amino Acids online at A&P Connect.

The Human Genome
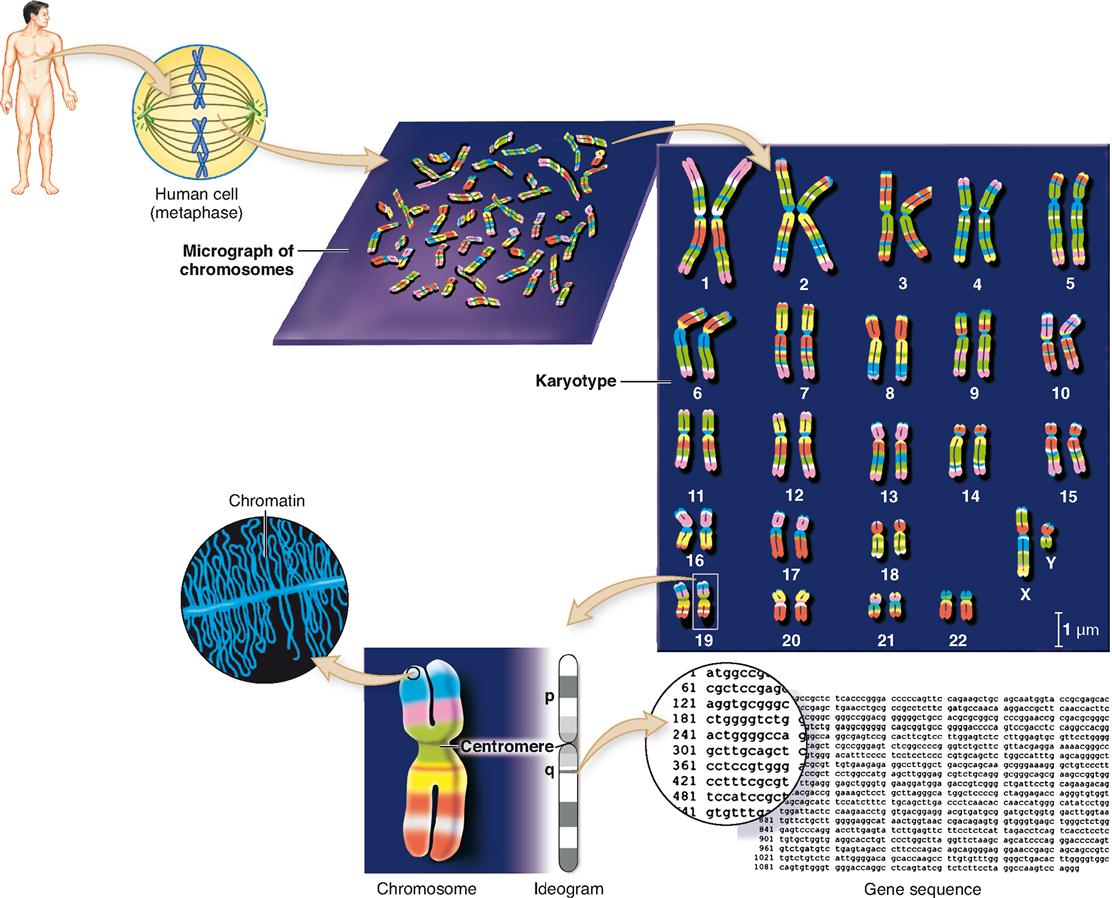
The entire collection of genetic material in each typical cell of the human body is called the genome (JEE-nome). The structure of the human genome is summarized in Figure 37-2. The typical human genome includes 46 individual nuclear chromosomes and one mitochondrial chromosome. In 2003, the Human Genome Project—a publicly funded, worldwide collaboration to map all the genes in the human genome—was completed. This landmark event coincided exactly with the fiftieth anniversary of the discovery of DNA.
We now know that the human genome contains only about 20,000 to 25,000 genes. This is about one fifth to one quarter of the number originally estimated. Amazingly, it is roughly the same number of genes as in a rat or mouse—and only about one and one-half times as many genes as in a fruit fly!
We also know that less than 2% of the DNA carries protein-coding genes. A bit more of the DNA carries code for functional RNAs, such as rRNA, tRNA, and ribozymes (see Figure 5-2 on p. 115). Most of the rest of the DNA is often called “junk” code that is either not used or is edited out of mRNA before it is used to make proteins. Some of this noncoding DNA may actually be made up of broken bits of genes that are no longer functional—remnants of our evolutionary past. Termed pseudogenes, these bits of formerly functional genes are like genetic fossils that have begun to reveal an interesting history of our genetic past.
The current draft of the human genome shows us that most coding genes tend to lie in clusters rich in C (cytosine) and G (guanine), separated by long stretches of noncoding DNA rich in A (adenine) and T (thymine). Chromosome 1 has the most genes, with nearly 3000 genes, and the Y chromosome has the fewest, with just over 200 genes. Hundreds of the newly discovered genes in the human genome seem to be bacterial in origin, perhaps inserted there by bacteria in our distant ancestors.
An important thing to remember about genes is that they are not each just one sequence that codes for one protein. Besides possibly coding for a nonprotein such as RNA, each gene is made up of several separated exons that join together before protein synthesis (see Figure 5-4 on p. 116). In some cases, different combinations of some of the same exons can make up genes for different products. Recall also that some proteins are quaternary proteins made up of polypeptides that may be made from different genes. So the definition of a gene is less straightforward than it first appears!
Although we now have the essential picture of the details of the human genome, much work still lies ahead in the field of genomics (jeh-NOM-iks), the analysis of the genome’s code. Besides filling in the remaining details of the rough draft, we have much work to do in discovering all the possible mutations that might exist (see the discussion later in this chapter) and all the proteins encoded by the genes that make up the human genome (Box 37-1).
 FYI
FYIIn fact, this quest has generated several other fields related to the genetic code. For example, transcriptomics (transkript-OHM-iks) is the analysis of all the mRNA codes actually transcribed from the human genome—the transcriptome (tran-SKRIPT-ome). This field may eventually shed light on which genes are expressed and under what conditions.
A field called proteomics (pro-tee-OH-miks) is the analysis of the proteins encoded by the genome. The entire group of proteins encoded by the human genome is called the human proteome (PRO-tee-ohm). The ultimate goal of proteomics is to understand the role of each protein in the body. Understanding the roles of every single protein in the body will certainly go a long way toward improving our knowledge of the normal function of the body as well as mechanisms for many diseases.
The analysis of the human genome, transcriptome, and proteome has surged forward recently with the widespread use of RNA interference (RNAi) techniques that silence particular genes in the laboratory setting as a means to find out what they do in the body—what proteins are transcribed from them.
Another proven technique that “knocks out” individual genes has been used for some time to demonstrate the effects of specific genes. Using embryonic stem cells from laboratory mice in which specific genes are targeted and disabled, a generation of genetically altered “knockout mice” can be produced. The mice are then studied to find out the effects of the gene(s) missing from the mouse genome.
Information obtained about the human genome can be expressed in a variety of ways. As you can see in Figure 37-2, an ideogram (ID-ee-oh-gram), or simple cartoon of a chromosome, is often used in genomics to show the overall physical structure of a chromosome. The constriction in the ideogram shows the relative position of the chromosome’s centromere. The shorter segment of the chromosome is called the p-arm and the longer segment is called the q-arm.
The bands in an ideogram of a chromosome show staining landmarks and help identify the regions of the chromosome. Sometimes physical maps of genes will show exact positions of individual genes on the p-arm and q-arm of a chromosome. A more detailed representation of a gene would show the actual sequence of nucleotide bases, abbreviated a, c, g, and t for adenine, cytosine, guanine, and thymine, as shown in Figure 37-2.
Distribution of Chromosomes to Offspring
MEIOSIS
Each cell of the human body contains 46 chromosomes. The only exceptions to this principle are the gametes—male spermatozoa and female ova. Recall from Chapter 36 that a special form of nuclear division called meiosis (see Figure 36-1 on p. 1098) produces gametes with only 23 chromosomes—exactly one half the usual number. This number is called the haploid number. This process follows a basic principle of genetics first discovered by Gregor Mendel called the principle of segregation. This principle simply states that the two members of a pair of chromosomes separate, or segregate, during meiosis.
When a sperm (with its 23 chromosomes) unites with an ovum (with its 23 chromosomes) at conception, a zygote with 46 chromosomes is formed. Thus the zygote has the same number of chromosomes (46, the diploid number) as each typical body cell in the parents.
As the karyotype in Figure 37-2 shows, the 46 human chromosomes can be arranged in 23 pairs according to size. One pair called the sex chromosomes may not match, but the remaining 22 pairs of autosomes always appear to be nearly identical to each other.
PRINCIPLE OF INDEPENDENT ASSORTMENT
Because one half of an offspring’s chromosomes are from the mother and one half are from the father, a unique blend of inherited traits is formed. According to another of Mendel’s principles, each chromosome assorts itself independently during meiosis. This principle of independent assortment
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


