10 Statistical Inference and Hypothesis Testing

With the nature of variation, types of data and variables, and characteristics of data distribution reviewed in Chapter 9 as background, we now explore how to make inferences from data.
I Nature and Purpose of Statistical Inference
A Differences between Deductive and Inductive Reasoning


If both propositions are true, then the following deduction must be true:

Deductive reasoning is of special use in science after hypotheses are formed. Using deductive reasoning, an investigator can say, “If the following hypothesis is true, then the following prediction or predictions also should be true.” If a prediction can be tested empirically, the hypothesis may be rejected or not rejected on the basis of the findings. If the data are inconsistent with the predictions from the hypothesis, the hypothesis must be rejected or modified. Even if the data are consistent with the hypothesis, however, they cannot prove that the hypothesis is true, as shown in Chapter 4 (see Fig. 4-2).
B Differences between Mathematics and Statistics
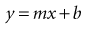
This equation is the formula for a straight line in analytic geometry. It is also the formula for simple regression analysis in statistics, although the letters used and their order customarily are different.
In the mathematical formula the b is a constant and stands for the y-intercept (i.e., value of y when the variable x equals 0). The value m also is a constant and stands for the slope (amount of change in y for a unit increase in the value of x). The important point is that in mathematics, one of the variables (x or y) is unknown and needs to be calculated, whereas the formula and the constants are known. In statistics the reverse is true. The variables x and y are known for all persons in the sample, and the investigator may want to determine the linear relationship between them. This is done by estimating the slope and the intercept, which can be done using the form of statistical analysis called linear regression (see Chapter 11).
II Process of Testing Hypotheses
The discussion in this section focuses on the justification for, and interpretation of, the p value, which is the probability that a difference as large as one observed might have occurred by chance. The p value is obtained from calculating one of the standard statistical tests. It is designed to minimize the likelihood of making a false-positive conclusion. False-negative conclusions are discussed more fully in Chapter 12 in the section on sample size.
A False-Positive and False-Negative Errors
Science is based on the following set of principles:
 Previous experience serves as the basis for developing hypotheses.
Previous experience serves as the basis for developing hypotheses.
 Hypotheses serve as the basis for developing predictions.
Hypotheses serve as the basis for developing predictions.
 Predictions must be subjected to experimental or observational testing.
Predictions must be subjected to experimental or observational testing.

Box 10-1 shows the usual sequence of statistical testing of hypotheses; analyzing data using these five basic steps is discussed next.
1 Develop Null Hypothesis and Alternative Hypothesis
The first step consists of stating the null hypothesis and the alternative hypothesis. The null hypothesis states that there is no real (true) difference between the means (or proportions) of the groups being compared (or that there is no real association between two continuous variables). For example, the null hypothesis for the data presented in Table 9-2 is that, based on the observed data, there is no true difference between the percentage of men and the percentage of women who had previously had their serum cholesterol levels checked.
3 Perform Test of Statistical Significance
When the alpha level is established, the next step is to obtain the p value for the data. To do this, the investigator must perform a suitable statistical test of significance on appropriately collected data, such as data obtained from a randomized controlled trial (RCT). This chapter and Chapter 11 focus on some suitable tests. The p value obtained by a statistical test (e.g., t-test, described later) gives the probability of obtaining the observed result by chance rather than as a result of a true effect. When the probability of an outcome being caused by chance is sufficiently remote, the null hypothesis is rejected. The p value states specifically just how remote that probability is.
4 Compare p Value Obtained with Alpha
After the p value is obtained, it is compared with the alpha level previously chosen.
B Variation in Individual Observations and in Multiple Samples
Why not just inspect the means to see if they were different? This is inadequate because it is unknown whether the observed difference was unusual or whether a difference that large might have been found frequently if the experiment were repeated. Although the investigators examine the findings in particular patients, their real interest is in determining whether the findings of the study could be generalized to other, similar hypertensive patients. To generalize beyond the participants in the single study, the investigators must know the extent to which the differences discovered in the study are reliable. The estimate of reliability is given by the standard error, which is not the same as the standard deviation discussed in Chapter 9.
1 Standard Deviation and Standard Error
Chapter 9 focused on individual observations and the extent to which they differed from the mean. One assertion was that a normal (gaussian) distribution could be completely described by its mean and standard deviation. Figure 9-6 showed that, for a truly normal distribution, 68% of observations fall within the range described as the mean ± 1 standard deviation, 95.4% fall within the range of the mean ± 2 standard deviations, and 95% fall within the range of the mean ± 1.96 standard deviations. This information is useful in describing individual observations (raw data), but it is not directly useful when comparing means or proportions.
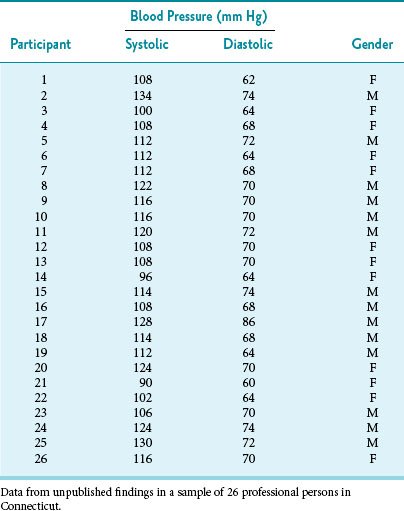
The data shown in Table 10-1 can be used to explore the concept of standard error. The table lists the systolic and diastolic blood pressures of 26 young, healthy, adult subjects. To determine the range of expected variation in the estimate of the mean blood pressure obtained from the 26 subjects, the investigator would need an unbiased estimate of the variation in the underlying population. How can this be done with only one small sample?
Although the proof is not shown here, an unbiased estimate of the standard error can be obtained from the standard deviation of a single research sample if the standard deviation was originally calculated using the degrees of freedom (N − 1) in the denominator (see Chapter 9). The formula for converting this standard deviation (SD) to a standard error (SE) is as follows:
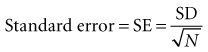
2 Confidence Intervals
The SD shows the variability of individual observations, whereas the SE shows the variability of means. The mean ± 1.96 SD estimates the range in which 95% of individual observations would be expected to fall, whereas the mean ± 1.96 SE estimates the range in which 95% of the means of repeated samples of the same size would be expected to fall. If the value for the mean ± 1.96 SE is known, it can be used to calculate the 95% confidence interval, which is the range of values in which the investigator can be 95% confident that the true mean of the underlying population falls. Other confidence intervals, such as the 99% confidence interval, also can be determined easily. Box 10-2 shows the calculation of the SE and the 95% confidence interval for the systolic blood pressure data in Table 10-1.



