11 Bivariate Analysis

A variety of statistical tests can be used to analyze the relationship between two or more variables. Similar to Chapter 10, this chapter focuses on bivariate analysis, which is the analysis of the relationship between one independent (possibly causal) variable and one dependent (outcome) variable. Chapter 13 focuses on multivariable analysis, or the analysis of the relationship of more than one independent variable to a single dependent variable. (The term multivariate technically refers to analysis of multiple independent and multiple dependent variables, although it is often used interchangeably with multivariable). Statistical tests should be chosen only after the types of clinical data to be analyzed and the basic research design have been established. Steps in developing a research protocol include posing a good question; establishing a research hypothesis; establishing suitable measures; and deciding on the study design. The selection of measures in turn indicates the appropriate methods of statistical analysis. In general, the analytic approach should begin with a study of the individual variables, including their distributions and outliers, and a search for errors. Then bivariate analysis can be done to test hypotheses and probe for relationships. Only after these procedures have been done, and if there is more than one independent variable to consider, should multivariable analysis be conducted.
I Choosing an Appropriate Statistical Test
Table 11-1 shows the numerous tests of statistical significance that are available for bivariate (two-variable) analysis. The types of variables and the research design set the limits to statistical analysis and determine which test or tests are appropriate. The four types of variables are continuous data (e.g., levels of glucose in blood samples), ordinal data (e.g., rankings of very satisfied, satisfied, and unsatisfied), dichotomous data (e.g., alive vs. dead), and nominal data (e.g., ethnic group). An investigator must understand the types of variables and how the type of variable influences the choice of statistical tests, just as a painter must understand types of media (e.g., oils, tempera, watercolors) and how the different media influence the appropriate brushes and techniques to be used.
Table 11-1 Choice of Appropriate Statistical Significance Test in Bivariate Analysis (Analysis of One Independent Variable and One Dependent Variable)
II Making Inferences (Parametric Analysis) From Continuous Data
Studies often involve one variable that is continuous (e.g., blood pressure) and another variable that is not (e.g., treatment group, which is dichotomous). As shown in Table 11-1, a t-test is appropriate for analyzing these data. A one-way analysis of variance (ANOVA) is appropriate for analyzing the relationship between one continuous variable and one nominal variable. Chapter 10 discusses the use of Student’s and paired t-tests in detail and introduces the concept of ANOVA (see Variation between Groups versus Variation within Groups).
1. Is there a real relationship between the variables or not?
2. If there is a real relationship, is it a positive or negative linear relationship (a straight-line relationship), or is it more complex?
3. If there is a linear relationship, how strongly linear is it—do the data points almost lie along a straight line?
4. Is the relationship likely to be true and not just a chance relationship?
A Joint Distribution Graph
The raw data concerning the systolic and diastolic blood pressures of 26 young, healthy, adult participants were introduced in Chapter 10 and listed in Table 10-1. These same data can be plotted on a joint distribution graph, as shown in Figure 11-1. The data lie generally along a straight line, going from the lower left to the upper right on the graph, and all the observations except one are fairly close to the line.
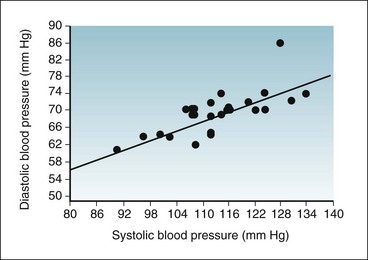
Figure 11-1 Joint distribution graph of systolic (x-axis) and diastolic (y-axis) blood pressure values of 26 young, healthy, adult participants.
The raw data for these participants are listed in Table 10-1. The correlation between the two variables is strong and is positive.
As indicated in Figure 11-2, the correlation between two variables, labeled x and y, can range from nonexistent to strong. If the value of y increases as x increases, the correlation is positive; if y decreases as x increases, the correlation is negative. It appears from the graph in Figure 11-1 that the correlation between diastolic and systolic blood pressure is strong and positive. Based on Figure 11-1, the answer to the first question posed previously is that there is a real relationship between diastolic and systolic blood pressure. The answer to the second question is that the relationship is positive and is almost linear. The graph does not provide quantitative information about how strong the association is (although it looks strong to the eye), and the graph does not reveal the probability that such a relationship could have occurred by chance. To answer these questions more precisely, it is necessary to use the techniques of correlation and simple linear regression. Neither the graph nor these statistical techniques can answer the question of how general the findings are to other populations, however, which depends on research design, especially the method of sampling.
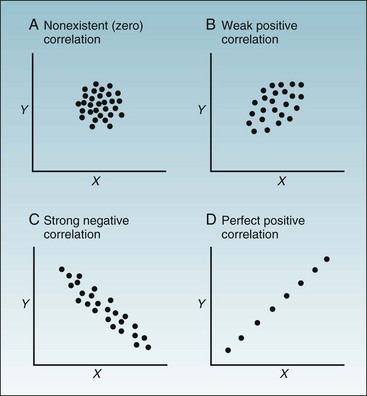
Figure 11-2 Four possible patterns in joint distribution graphs.
As seen in examples A to D, the correlation between two continuous variables, labeled X and Y, can range from nonexistent to perfect. If the value of y increases as x increases, the correlation is positive. If y decreases as x increases, the correlation is negative.
B Pearson Correlation Coefficient
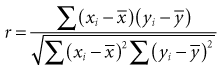
Using statistical computer programs, investigators can determine whether the value of r is greater than would be expected by chance alone (i.e., whether the two variables are statistically associated). Most statistical programs provide the p value along with the correlation coefficient, but the p value of the correlation coefficient can be calculated easily. Its associated t can be calculated from the following formula, and the p value can be determined from a table of t (see Appendix, Table C)1:
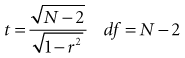
As with every test of significance, for any given level of strength of association, the larger the sample size, the more likely it is to be statistically significant. A weak correlation in a large sample might be statistically significant, despite that it was not etiologically or clinically important (see later and Box 11-5). The converse may also be true; a result that is statistically weak still may be of public health and clinical importance if it pertains to a large portion of the population.
There is no perfect statistical way to estimate clinical importance, but with continuous variables, a valuable concept is the strength of the association, measured by the square of the correlation coefficient, or r2. The r2 value is the proportion of variation in y explained by x (or vice versa). It is an important parameter in advanced statistics. Looking at the strength of association is analogous to looking at the size and clinical importance of an observed difference, as discussed in Chapter 10.
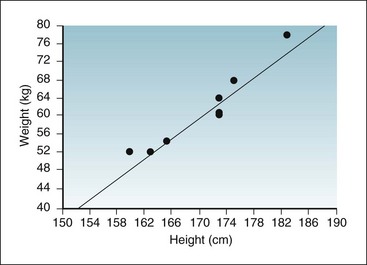
For purposes of showing the calculation of r and r2, a small set of data is introduced in Box 11-1. The data, consisting of the observed heights (variable x) and weights (variable y) of eight participants, are presented first in tabular form and then in graph form. When r is calculated, the result is 0.96, which indicates a strong positive linear relationship and provides quantitative information to confirm what is visually apparent in the graph. Given that r is 0.96, r2 is (0.96),2 or 0.92. A 0.92 strength of association means that 92% of the variation in weight is explained by height. The remaining 8% of the variation in this sample is presumed to be caused by factors other than height.
Box 11-1 Analysis of Relationship between Height and Weight (Two Continuous Variables) in Eight Study Participants
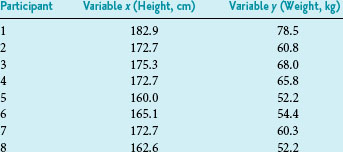

Part 3 Calculation of Pearson Correlation Coefficient (r) and Strength of Association of Variables (r2)
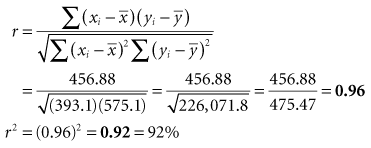
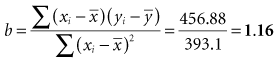
Data from unpublished findings in a sample of eight professional persons in Connecticut.
C Linear Regression Analysis
The formula for a straight line, as expressed in statistics, is y = a + bx (see Chapter 10). The y is the value of an observation on the y-axis; x is the value of the same observation on the x-axis; a is the regression constant (value of y when value of x is 0); and b is the slope (change in value of y for a unit change in value of x). Linear regression is used to estimate two parameters: the slope of the line (b) and the y-intercept (a). Most fundamental is the slope, which determines the impact of variable x on y. The slope can tell how much weight is expected to increase, on the average, for each additional centimeter of height.
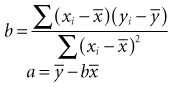
Box 11-1 shows the calculation of the slope (b) for the observed heights and weights of eight participants. The graph in Box 11-1 shows the linear relationship between the height and weight data, with the regression line inserted. In these eight participants, the slope was 1.16, meaning that there was an average increase of 1.16 kg of weight for every 1-cm increase in height.
Just as it is possible to set confidence intervals around parameters such as means and proportions (see Chapter 10), it is possible to set confidence intervals around the parameters of the regression, the slope, and the intercept, using computations based on linear regression formulas. Most statistical computer programs perform these computations, and moderately advanced statistics books provide the formulas.2 Multiple linear regression and other methods involved in the analysis of more than two variables are discussed in Chapter 13.
III Making Inferences (Nonparametric Analysis) From Ordinal Data
Many medical data are ordinal, meaning the observations can be ranked from the lowest value to the highest value, but they are not measured on an exact scale. In some cases, investigators assume that ordinal data meet the criteria for continuous (measurement) data and analyze these variables as though they had been obtained from a measurement scale. If patients’ satisfaction with the care in a given hospital were being studied, the investigators might assume that the conceptual distance between “very satisfied” (e.g., coded as a 3) and “fairly satisfied” (coded as a 2) is equal to the difference between “fairly satisfied” (coded as a 2) and “unsatisfied” (coded as a 1). If the investigators are willing to make these assumptions, the data might be analyzed using the parametric statistical methods discussed here and in Chapter 10, such as t-tests, analysis of variance, and analysis of the Pearson correlation coefficient. This assumption is dubious, however, and seldom appropriate for use in publications.
If the investigator is not willing to assume an ordinal variable can be analyzed as though it were continuous, many bivariate statistical tests for ordinal data can be used1,3 (see Table 11-1 and later description). Hand calculation of these tests for ordinal data is extremely tedious and invites errors. No examples are given here, and the use of a computer for these calculations is customary.
A Mann-Whitney U Test
The test for ordinal data that is similar to the Student’s t-test is the Mann-Whitney U test. U, similar to t, designates a probability distribution. In the Mann-Whitney test, all the observations in a study of two samples (e.g., experimental and control groups) are ranked numerically from the smallest to the largest, without regard to whether the observations came from the experimental group or from the control group. Next, the observations from the experimental group are identified, the values of the ranks in this sample are summed, and the average rank and the variance of those ranks are determined. The process is repeated for the observations from the control group. If the null hypothesis is true (i.e., if there is no real difference between the two samples), the average ranks of the two samples should be similar. If the average rank of one sample is considerably greater than that of the other sample, the null hypothesis probably can be rejected, but a test of significance is needed to be sure. Because the U-test method is tedious, a t-test can be done instead (considering the ranks as though they were continuous data), and often this yields similar results.1
The Mann-Whitney U test was applied, for example, in a study comparing lithotripsy to ureteroscopy in the treatment of renal calculi.4
B Wilcoxon Matched-Pairs Signed-Ranks Test
The Wilcoxon test, for example, was used to compare knowledge, attitude, and practice measures between groups in an educational program for type 1 diabetes.5
C Kruskal-Wallis Test
If the investigators in a study involving continuous data want to compare the means of three or more groups simultaneously, the appropriate test is a one-way analysis of variance (a one-way ANOVA), usually called an F-test. The comparable test for ordinal data is called the Kruskal-Wallis test or the Kruskal-Wallis one-way ANOVA. As in the Mann-Whitney U test, for the Kruskal-Wallis test, all the data are ranked numerically, and the rank values are summed in each of the groups to be compared. The Kruskal-Wallis test seeks to determine if the average ranks from three or more groups differ from one another more than would be expected by chance alone. It is another example of a critical ratio (see Chapter 10), in which the magnitude of the difference is in the numerator, and a measure of the random variability is in the denominator. If the ratio is sufficiently large, the null hypothesis is rejected.
The Kruskal-Wallis test was used, for example, in an analysis of the effects of electronic medical record systems on the quality of documentation in primary care.6
D Spearman and Kendall Correlation Coefficients
The Spearman rank test was used, for example, in a validation study of a tool to address the preservation, for example, dignity at end of life.7
IV Making Inferences (Nonparametric Analysis) From Dichotomous and Nominal Data
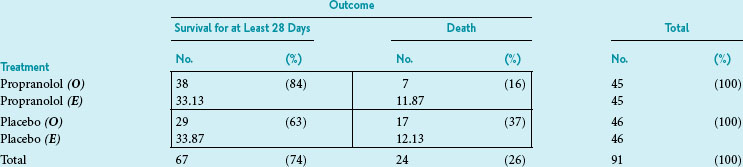
As indicated in Table 11-1, the chi-square test, Fisher exact probability test, and McNemar chi-square test can be used in the analysis of dichotomous data, although they use different statistical theory. Usually, the data are first arranged in a 2 × 2 table, and the goal is to test the null hypothesis that the variables are independent.
A 2 × 2 Contingency Table
Data arranged as in Box 11-2 form what is known as a contingency table because it is used to determine whether the distribution of one variable is conditionally dependent (contingent) on the other variable. More specifically, Box 11-2 provides an example of a 2 × 2 contingency table, meaning that it has two cells in each direction. In this case, the table shows the data for a study of 91 patients who had a myocardial infarction.9 One variable is treatment (propranolol vs. a placebo), and the other is outcome (survival for at least 28 days vs. death within 28 days).