36
RNA Synthesis, Processing, & Modification
OBJECTIVES
After studying this chapter, you should be able to:
![]() Describe the molecules involved and the mechanism of RNA synthesis.
Describe the molecules involved and the mechanism of RNA synthesis.
![]() Explain how eukaryotic DNA-dependent RNA polymerases, in collaboration with an array of specific accessory factors, can differentially transcribe genomic DNA to produce specific mRNA precursor molecules.
Explain how eukaryotic DNA-dependent RNA polymerases, in collaboration with an array of specific accessory factors, can differentially transcribe genomic DNA to produce specific mRNA precursor molecules.
![]() Describe the structure of eukaryotic mRNA precursors, which are highly modified at both termini.
Describe the structure of eukaryotic mRNA precursors, which are highly modified at both termini.
![]() Appreciate the fact that the majority of mammalian mRNA-encoding genes are interrupted by multiple non-protein coding sequences termed introns, which are interspersed between protein coding regions termed exons.
Appreciate the fact that the majority of mammalian mRNA-encoding genes are interrupted by multiple non-protein coding sequences termed introns, which are interspersed between protein coding regions termed exons.
![]() Explain that since intron RNA does not encode protein, the intronic RNA must be specifically and accurately removed in order to generate functional mRNAs from the mRNA precursor molecules in a series of precise molecular events termed RNA splicing.
Explain that since intron RNA does not encode protein, the intronic RNA must be specifically and accurately removed in order to generate functional mRNAs from the mRNA precursor molecules in a series of precise molecular events termed RNA splicing.
![]() Explain the steps and molecules that catalyze mRNA splicing, a process that converts the end-modified mRNA precursor molecules into mRNAs that are functional for translation.
Explain the steps and molecules that catalyze mRNA splicing, a process that converts the end-modified mRNA precursor molecules into mRNAs that are functional for translation.
BIOMEDICAL IMPORTANCE
The synthesis of an RNA molecule from DNA is a complex process involving one of the group of RNA polymerase enzymes and a number of associated proteins. The general steps required to synthesize the primary transcript are initiation, elongation, and termination. Most is known about initiation. A number of DNA regions (generally located upstream from the initiation site) and protein factors that bind to these sequences to regulate the initiation of transcription have been identified. Certain RNAs—mRNAs in particular—have very different life spans in a cell. The RNA molecules synthesized in mammalian cells are made as precursor molecules that have to be processed into mature, active RNA. It is important to understand the basic principles of messenger RNA (mRNA) synthesis and metabolism, for modulation of this process results in altered rates of protein synthesis and thus a variety of both metabolic and phenotypic changes. This is how all organisms adapt to changes of environment. It is also how differentiated cell structures and functions are established and maintained. Errors or changes in synthesis, processing, splicing, stability, or function of mRNA transcripts are a cause of disease.
RNA EXISTS IN FOUR MAJOR CLASSES
All eukaryotic cells have four major classes of RNA (Table 36-1): ribosomal RNA (rRNA), mRNA, transfer RNA (tRNA), and small RNAs, the small nuclear RNAs and microRNAs (snRNA and miRNA). The first three are involved in protein synthesis, while the small RNAs are involved in mRNA splicing and modulation of gene expression by altering mRNA function. The various classes of RNA are different in their diversity, stability, and abundance in cells.
TABLE 36–1 Classes of Eukaryotic RNA

RNA IS SYNTHESIZED FROM A DNA TEMPLATE BY AN RNA POLYMERASE
The processes of DNA and RNA synthesis are similar in that they involve (1) the general steps of initiation, elongation, and termination with 5′-3’ polarity; (2) large, multicomponent initiation complexes; and (3) adherence to Watson-Crick base-pairing rules. However, DNA and RNA synthesis do differ in several important ways, including the following: (1) ribonucleotides are used in RNA synthesis rather than deoxyribonucleotides; (2) U replaces T as the complementary base for A in RNA; (3) a primer is not involved in RNA synthesis as RNA polymerases have the ability to initiate synthesis de novo; (4) only portions of the genome are vigorously transcribed or copied into RNA, whereas the entire genome must be copied, once and only once during DNA replication; and (5) there is no highly active, efficient proofreading function during RNA transcription.
The process of synthesizing RNA from a DNA template has been characterized best in prokaryotes. Although in mammalian cells, the regulation of RNA synthesis and the processing of the RNA transcripts are different from those in prokaryotes, the process of RNA synthesis per se is quite similar in these two classes of organisms. Therefore, the description of RNA synthesis in prokaryotes, where it is best understood, is applicable to eukaryotes even though the enzymes involved and the regulatory signals, though related, are different.
The Template Strand of DNA Is Transcribed
The sequence of ribonucleotides in an RNA molecule is complementary to the sequence of deoxyribonucleotides in one strand of the double-stranded DNA molecule (Figure 34–8). The strand that is transcribed or copied into an RNA molecule is referred to as the template strand of the DNA. The other DNA strand, the nontemplate strand, is frequently referred to as the coding strand of that gene. It is called this because, with the exception of T for U changes, it corresponds exactly to the sequence of the messenger RNA primary transcript, which encodes the (protein) product of the gene. In the case of a double-stranded DNA molecule containing many genes, the template strand for each gene will not necessarily be the same strand of the DNA double helix (Figure 36–1). Thus, a given strand of a double-stranded DNA molecule will serve as the template strand for some genes and the coding strand of other genes. Note that the nucleotide sequence of an RNA transcript will be the same (except for U replacing T) as that of the coding strand. The information in the template strand is read out in the 3′-5’ direction. Though not shown in Figure 36–1 there are instances of genes embedded within other genes.
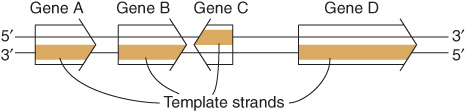
FIGURE 36–1 Genes can be transcribed off both strands of DNA. The arrowheads indicate the direction of transcription (polarity). Note that the template strand is always read in the 3′-5’ direction. The opposite strand is called the coding strand because it is identical (except for T for U changes) to the mRNA transcript (the primary transcript in eukaryotic cells) that encodes the protein product of the gene.
DNA-Dependent RNA Polymerase Initiates Transcription at a Distinct Site, the Promoter
DNA-dependent RNA polymerase is the enzyme responsible for the polymerization of ribonucleotides into a sequence complementary to the template strand of the gene (see Figures 36-2 and 36-3). The enzyme attaches at a specific site—the promoter—on the template strand. This is followed by initiation of RNA synthesis at the starting point, and the process continues until a termination sequence is reached (Figure 36–3). A transcription unit is defined as that region of DNA that includes the signals for transcription initiation, elongation, and termination. The RNA product, which is synthesized in the 5′-3’ direction, is the primary transcript. Transcription rates vary from gene to gene but can be quite high. An electron micrograph of transcription in action is presented in Figure 36–4. In prokaryotes, this can represent the product of several contiguous genes; in mammalian cells, it usually represents the product of a single gene. If a transcription unit contains only a single gene, then the 5′ termini of the primary RNA transcript and the mature cytoplasmic RNA are identical. Thus, the starting point of transcription corresponds to the 5′ nucleotide of the mRNA. This is designated position +1, as is the corresponding nucleotide in the DNA. The numbers increase as the sequence proceeds downstream from the start site. This convention makes it easy to locate particular regions, such as intron and exon boundaries. The nucleotide in the promoter adjacent to the transcription initiation site in the upstream direction is designated -1, and these negative numbers increase as the sequence proceeds upstream, away from the initiation site. This +/- numbering system provides a conventional way of defining the location of regulatory elements in the promoter.
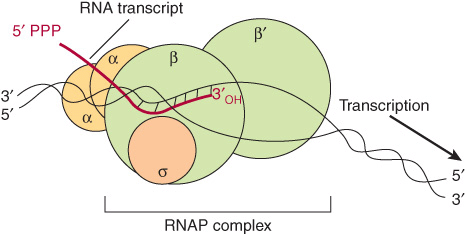
FIGURE 36–2 RNA polymerase (RNAP) catalyzes the polymerization of ribonucleotides into an RNA sequence that is complementary to the template strand of the gene. The RNA transcript has the same polarity (5’-3’) as the coding strand but contains U rather than T. E coli RNAP consists of a core complex of two α subunits and two β subunits (β and β’). The holoenzyme contains the σ subunit bound to the α2 ββ’ core assembly. The ω subunit is not shown. The transcription “bubble” is an approximately 20-bp area of melted DNA, and the entire complex covers 30-75 bp, depending on the conformation of RNAP.
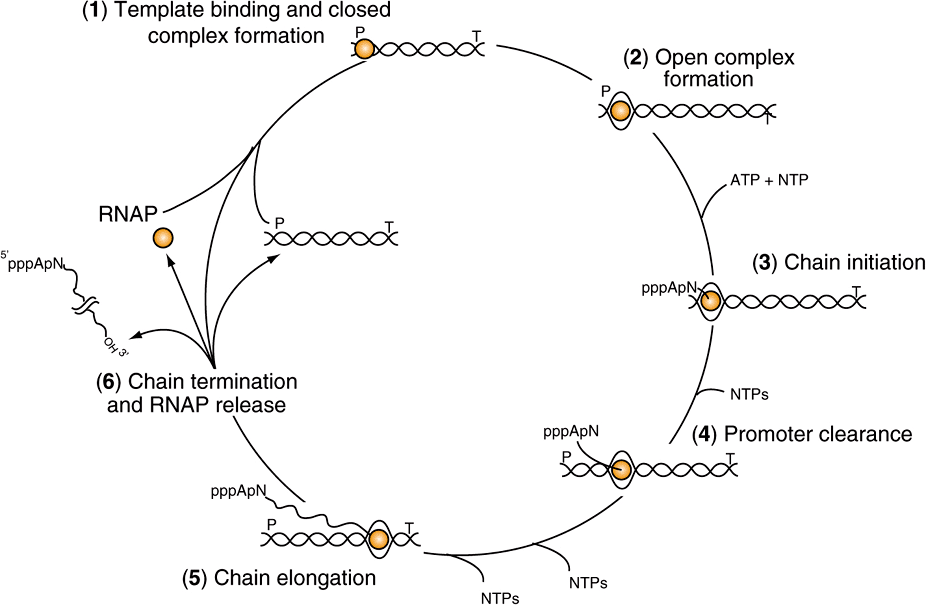
FIGURE 36–3 The transcription cycle. Transcription can be described in six steps: (1) Template binding and closed RNA polymerase-promoter complex formation: RNA polymerase (RNAP) binds to DNA and then locates a promoter (P), (2) Open promoter complex formation: once bound to the promoter, RNAP melts the two DNA strands to form an open promoter complex; this complex is also referred to as the preinitiation complex or PIC. Strand separation allows the polymerase to access the coding information in the template strand of DNA (3) Chain initiation: using the coding information of the template RNAP catalyzes the coupling of the first base (often a purine) to the second, template-directed ribonucleoside triphosphate to form a dinucleotide (in this example forming the dinucleotide 5′ pppApNOH 3′). (4) Promoter clearance: after RNA chain length reaches -10-20 nt, the polymerase undergoes a conformational change and then is able to move away from the promoter, transcribing down the transcription unit. (5) Chain elongation: Successive residues are added to the 3′-OH terminus of the nascent RNA molecule until a transcription termination signal (T) is encountered. (6) Chain termination and RNAP release: Upon encountering the transcription termination site RNAP undergoes an additional conformational change that leads to release of the completed RNA chain, the DNA template and RNAP. RNAP can rebind to DNA beginning the promoter search process and the cycle is repeated. Note that all of the steps in the transcription cycle are facilitated by additional proteins, and indeed are often subjected to regulation by positive and/or negative-acting factors.
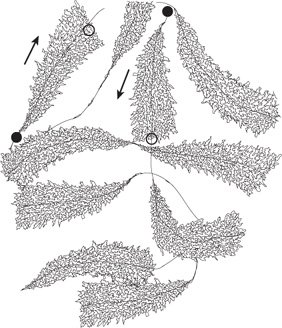
FIGURE 36–4 Schematic representation of an electron photomicrograph of multiple copies of amphibian rRNA-encoding genes in the process of being transcribed. The magnification is about 6000×. Note that the length of the transcripts increases as the RNA polymerase molecules progress along the individual rRNA genes from transcription start sites (filled circles) to transcription termination sites (open circles). RNA polymerase I (not visualized here) is at the base of the nascent rRNA transcripts. Thus, the proximal end of the transcribed gene has short transcripts attached to it, while much longer transcripts are attached to the distal end of the gene. The arrows indicate the direction (5’-3’) of transcription.
The primary transcripts generated by RNA polymerase II—one of the three distinct nuclear DNA-dependent RNA polymerases in eukaryotes—are promptly capped by 7-methyl-guanosine triphosphate caps (Figure 34–10) that persist and eventually appear on the 5’ end of mature cyto-plasmic mRNA. These caps are necessary for the subsequent processing of the primary transcript to mRNA, for the translation of the mRNA, and for protection of the mRNA against exonucleolytic attack.
Bacterial DNA-Dependent RNA Polymerase Is a Multisubunit Enzyme
The DNA-dependent RNA polymerase (RNAP) of the bacterium Escherichia coli exists as an approximately 400 kDa core complex consisting of two identical α subunits, similar but not identical β and β’ subunits, and an ω subunit. The β subunit binds Mg2+ ions and composes the catalytic subunit (Figure 36–2). The core RNA polymerase, ββ’α2ω, often termed E, associates with a specific protein factor (the sigma [σ] factor) to form holoenzyme, ββ’α2ωσ, or Eσ. The σ subunit helps the core enzyme recognize and bind to the specific deoxy-nucleotide sequence of the promoter region (Figure 36–5) to form the preinitiation complex (PIC). There are multiple, distinct σ-factor encoding genes in all bacterial species. Sigma factors have a dual role in the process of promoter recognition; σ association with core RNA polymerase decreases its affinity for nonpromoter DNA while simultaneously increasing holoenzyme affinity for promoter DNA. The multiple σ-factors compete for interaction with limiting core RNA polymerase (ie, E). Each of these unique σ-factors act as a regulatory protein that modifies the promoter recognition specificity of the resulting unique RNA polymerase holoenzyme (ie, Eσ1, Eσ2,…). The appearance of different σ-factors and their association with core RNA polymerase forming novel holoenzyme forms can be correlated temporally with various programs of gene expression in prokaryotic systems such as sporulation, growth in various poor nutrient sources, and the response to heat shock.
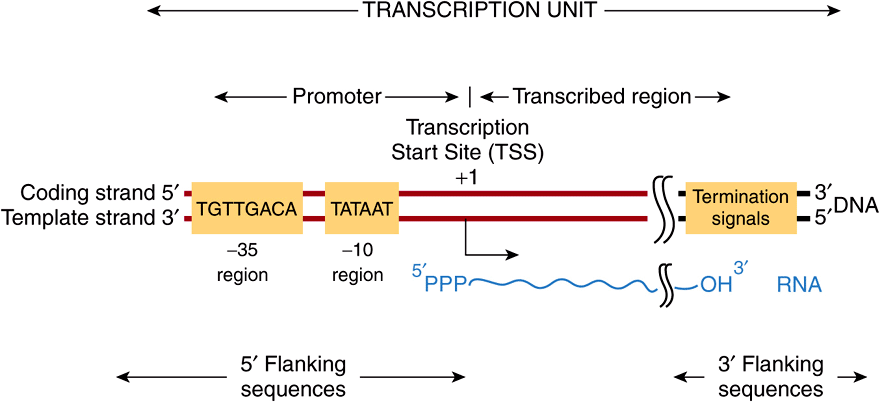
FIGURE 36–5 Bacterial promoters, such as that from E coli shown here, share two regions of highly conserved nucleotide sequence. These regions are located 35 and 10 bp upstream (in the 5′ direction of the coding strand) from the transcription start site (TSS), which is indicated as +1. By convention, all nucleotides upstream of the transcription initiation site (at +1) are numbered in a negative sense and are referred to as 5′-flanking sequences, while sequences downstream are numbered in a positive sense with the TSS as +1. Also by convention, the promoter DNA regulatory sequence elements such as the -35 and TATA box elements are described in the 5′-3’ direction and as being on the coding strand. These elements function only in double-stranded DNA, however. Other transcriptional regulatory elements, however, can often act in a direction independent fashion, and such cis-elements are drawn accordingly in any schematic (see also Figure 36–8). Note that the transcript produced from this transcription unit has the same polarity or “sense” (ie, 5′-3’ orientation) as the coding strand. Termination cis-elements reside at the end of the transcription unit (see Figure 36–6 for more detail). By convention, the sequences downstream of the site at which transcription termination occurs are termed 3′-flanking sequences.
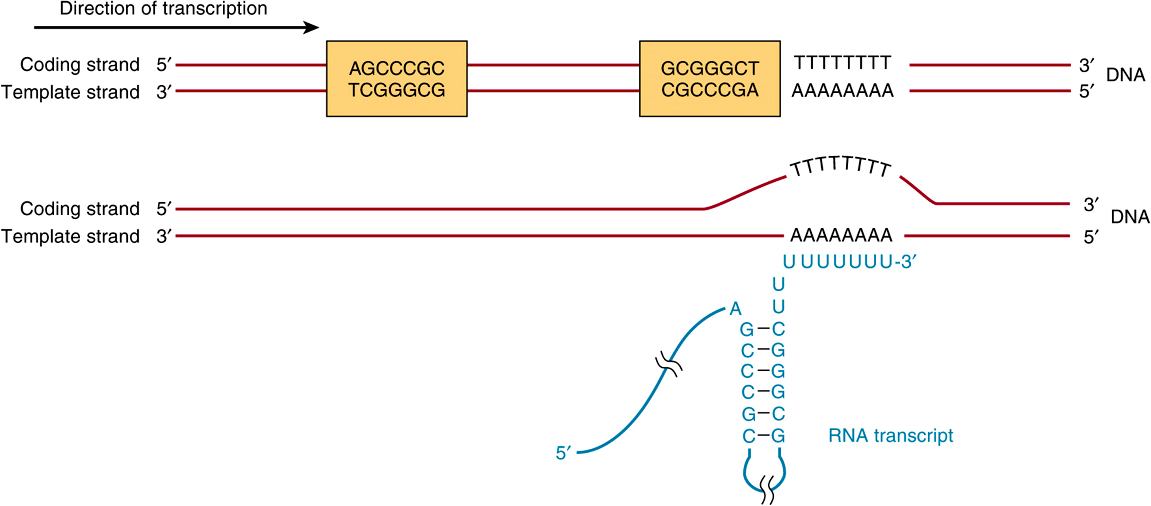
FIGURE 36–6 The predominant bacterial transcription termination signal contains an inverted, hyphenated repeat (the two boxed areas) followed by a stretch of AT base pairs (top). The inverted repeat, when transcribed into RNA, can generate the secondary structure in the RNA transcript (bottom). Formation of this RNA hairpin causes RNA polymerase to pause and subsequently the ρ (rho) termination factor interacts with the paused polymerase and induces chain termination through mechanisms not yet fully understood.
Mammalian Cells Possess Three Distinct Nuclear DNA-Dependent RNA Polymerases
The properties of mammalian nuclear polymerases are described in Table 36-2. Each of these DNA-dependent RNA polymerases is responsible for transcription of different sets of genes. The sizes of the RNA polymerases range from MW 500,000 to MW 600,000. These enzymes exhibit more complex subunit profiles than prokaryotic RNA polymerases. They all have two large subunits and a number of smaller subunits—as many as 14 in the case of RNA pol III. However, the eukaryotic RNA polymerase subunits do exhibit extensive amino acid sequence homologies with prokaryotic RNA polymerases. This homology has been shown recently to extend to the level of three-dimensional structures. The functions of each of the subunits are not yet fully understood.
A peptide toxin from the mushroom Amanita phalloides, α-amanitin, is a specific differential inhibitor of the eukaryotic nuclear DNA-dependent RNA polymerases and as such has proved to be a powerful research tool (Table 36-2). α-Amanitin blocks the translocation of RNA polymerase during phosphodiester bond formation.
TABLE 36–2 Nomenclature and Properties of Mammalian Nuclear DNA-Dependent RNA Polymerases

RNA SYNTHESIS IS A CYCLICAL PROCESS & INVOLVES RNA CHAIN INITIATION, ELONGATION, & TERMINATION
The process of RNA synthesis in bacteria—depicted in Figure 36–3—is cyclical and involves multiple steps. First RNA polymerase holoenzyme (E-σ) must bind DNA and locate a promoter (P; Figure 36–3). Once the promoter is located, the Eσ-promoter DNA complex undergoes a temperature-dependent conformational change and unwinds, or melts the DNA in and around the transcription start site (at +1). This complex is termed the preinitiation complex, or PIC. This unwinding allows the active site of the Eσ to access the template strand, which of course dictates the sequence of ribonucleotides to be polymerized into RNA. The first nucleotide (typically, though not always a purine) then associates with the nucleotide-binding site on the β subunit of the enzyme, and in the presence of the next appropriate nucleotide bound to the polymerase, RNAP catalyzes the formation of the first phosphodiester bond, and the nascent chain is now attached to the polymerization site on the β subunit of RNAP. This reaction is termed initiation. The analogy to the A and P sites on the ribosome should be noted; see Figure 37–9, below. The nascent dinucleotide retains the 5′-triphosphate of the initiating nucleotide (Figure 36–3, ATP).
RNA polymerase continues to incorporate nucleotides 3 to ~10, at which point the polymerase undergoes another conformational change and moves away from the promoter; this reaction is termed promoter clearance. The elongation phase then commences, here the nascent RNA molecule grows 5′ -3’ as consectutive NTP incorporation steps continue cyclically, antiparallel to its template. The enzyme polymerizes the ribonucleotides in the specific sequence dictated by the template strand and interpreted by Watson-Crick base-pairing rules. Pyrophosphate is released following each cycle of polymerization. As for DNA synthesis, this pyrophosphate (PPi) is rapidly degraded to 2 mol of inorganic phosphate (Pi) by ubiquitous pyrophosphatases, thereby providing irreversibility on the overall synthetic reaction. The decision, to stay at the promoter in a poised or stalled state, or transition to elongation appears to be an important regulatory step in both prokaryotic and eukaryotic mRNA gene transcription.
As the elongation complex containing RNA polymerase progresses along the DNA molecule, DNA unwinding must occur in order to provide access for the appropriate base pairing to the nucleotides of the coding strand. The extent of this transcription bubble (ie, DNA unwinding) is constant throughout transcription and has been estimated to be about 20 base pairs per polymerase molecule. Thus, it appears that the size of the unwound DNA region is dictated by the polymerase and is independent of the DNA sequence in the complex. RNA polymerase has an intrinsic “unwindase” activity that opens the DNA helix (ie, see PIC formation above). The fact that the DNA double helix must unwind, and the strands part at least transiently for transcription implies some disruption of the nucleosome structure of eukaryotic cells. Topoisomerase both precedes and follows the progressing RNA polymerase to prevent the formation of superhelical tensions that would serve to increase the energy required to unwind the template DNA ahead of RNAP.
Termination of the synthesis of the RNA molecule in bacteria is signaled by a sequence in the template strand of the DNA molecule—a signal that is recognized by a termination protein, the rho (ρ) factor. Rho is an ATP-dependent RNA-stimulated helicase that disrupts the ternary transcription elongation complex composed of RNA polymerase-nascent RNA and DNA. In some cases, bacterial RNAP can directly recognize DNA-encoded termination signals (Figure 36–3; T) without assistance by the rho factor. After termination of synthesis of the RNA, the enzyme separates from the DNA template and probably dissociates to free core enzyme and free factor. With the assistance of another σ-factor, the core enzyme then recognizes a promoter at which the synthesis of a new RNA molecule commences. In eukaryotic cells, termination is less well understood but the proteins catalyzing RNA processing, termination, and polyadenylation proteins all appear to load onto RNA polymerase II soon after initiation (see below). More than one RNA polymerase molecule may transcribe the same template strand of a gene simultaneously, but the process is phased and spaced in such a way that at any one moment each is transcribing a different portion of the DNA sequence (Figures 36-1 and 36-4).
THE FIDELITY & FREQUENCY OF TRANSCRIPTION IS CONTROLLED BY PROTEINS BOUND TO CERTAIN DNA SEQUENCES
Analysis of the DNA sequence of specific genes has allowed the recognition of a number of sequences important in gene transcription. From the large number of bacterial genes studied, it is possible to construct consensus models of transcription initiation and termination signals.
The question, “How does RNAP find the correct site to initiate transcription?” is not trivial when the complexity of the genome is considered. E coli has ![]() transcription initiation sites (ie, gene promoters) in
transcription initiation sites (ie, gene promoters) in ![]() base pairs (bp) of DNA. The situation is even more complex in humans, where as many as 105 transcription initiation sites are distributed throughout 3 × 109 bp of DNA. RNAP can bind, with low affinity, to many regions of DNA, but it scans the DNA sequence—at a rate of ≥103 bp/s—until it recognizes certain specific regions of DNA to which it binds with higher affinity. These regions are termed promoters, and it is the association of RNAP with promoters that ensures accurate initiation of transcription. The promoter recognition-utilization process is the target for regulation in both bacteria and humans.
base pairs (bp) of DNA. The situation is even more complex in humans, where as many as 105 transcription initiation sites are distributed throughout 3 × 109 bp of DNA. RNAP can bind, with low affinity, to many regions of DNA, but it scans the DNA sequence—at a rate of ≥103 bp/s—until it recognizes certain specific regions of DNA to which it binds with higher affinity. These regions are termed promoters, and it is the association of RNAP with promoters that ensures accurate initiation of transcription. The promoter recognition-utilization process is the target for regulation in both bacteria and humans.
Bacterial Promoters Are Relatively Simple
Bacterial promoters are approximately 40 nucleotides (40 bp or four turns of the DNA double helix) in length, a region small enough to be covered by an E coli RNA holopolymerase molecule. In a consensus promoter, there are two short, conserved sequence elements. Approximately 35-bp upstream of the transcription start site there is a consensus sequence of eight nucleotide pairs (consensus: 5′-TGTTGACA-3’) to which the RNAP binds to form the so-called closed complex. More proximal to the transcription start site—about 10 nucleotides upstream—is a six-nucleotide-pair A+T-rich sequence (consensus: 5′-TATAAT-3’). These conserved sequence elements together comprise the promoter, and are shown schematically in Figure 36–5. The latter sequence has a low melting temperature because of its lack of GC nucleotide pairs. Thus, the so-called TATA “box” is thought to ease the dissociation of the two DNA strands so that RNA polymerase bound to the promoter region can have access to the nucleotide sequence of its immediately downstream template strand. Once this process occurs, the combination of RNA polymerase plus promoter is called the open complex. Other bacteria have slightly different consensus sequences in their promoters, but all generally have two components to the promoter; these tend to be in the same position relative to the transcription start site, and in all cases the sequences between the two promoter elements have no similarity but still provide critical spacing functions that facilitate recognition of -35 and -10 sequences by RNA polymerase holoenzyme. Within a bacterial cell, different sets of genes are often coordinately regulated. One important way that this is accomplished is through the fact that these co-regulated genes share particular -35 and -10 promoter sequences. These unique promoters are recognized by different σ-factors bound to core RNA polymerase (ie, Eσ1, Eσ2,…).
Rho-dependent transcription termination signals in E coli also appear to have a distinct consensus sequence, as shown in Figure 36–6. The conserved consensus sequence, which is about 40 nucleotide pairs in length, can be seen to contain a hyphenated or interrupted inverted repeat followed by a series of AT base pairs. As transcription proceeds through the hyphenated, inverted repeat, the generated transcript can form the intramolecular hairpin structure, also depicted in Figure 36–6.
Transcription continues into the AT region, and with the aid of the ρ termination protein the RNA polymerase stops, dissociates from the DNA template, and releases the nascent transcript.
As discussed in detail in Chapter 38 bacterial gene transcription is controlled through the action of repressor and activator proteins. These proteins typically bind to unique and specific DNA sequences that lie adjacent to promoters. These repressors and activators affect the ability of the RNA polymerase to bind promoter DNA and/or form open complexes. The net effect is to stimulate or inhibit PIC formation and transcription initiation—consequently blocking or enhancing specific RNA synthesis.
Eukaryotic Promoters Are More Complex
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


