INTRODUCTION
The science of genetics defines and analyzes heredity of the vast array of structural and physiologic functions that form the properties of organisms. The basic unit of heredity is the gene, a segment of deoxyribonucleic acid (DNA) that encodes in its nucleotide sequence information for a specific physiologic property. The traditional approach to genetics has been to identify genes on the basis of their contribution to phenotype, or the collective structural and physiologic properties of an organism. A phenotypic property, be it eye color in humans or resistance to antibiotics in a bacterium, is generally observed at the level of the organism. The chemical basis for variation in phenotype is change in genotype, or alteration in the DNA sequence, within a gene or within the organization of genes.
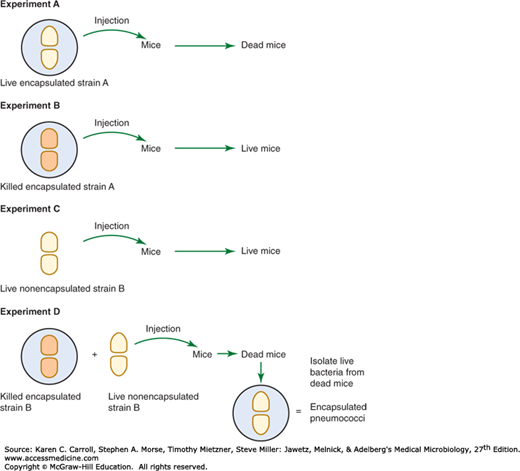
DNA as the fundamental element of heredity was suggested in the 1930s from a seminal experiment performed by Frederick Griffith (Figure 7-1). In this experiment, killed virulent Streptococcus pneumoniae type III-S (possessing a capsule), when injected into mice along with living but nonvirulent type II-R pneumococci (lacking a capsule), resulted in a lethal infection from which viable type III-S pneumococci were recovered. The implication was that some chemical entity transformed the live, nonvirulent strain to the virulent phenotype. A decade later, Avery, MacLeod, and McCarty discovered that DNA was the transforming agent. This formed the foundation for molecular biology as we understand it today.
FIGURE 7-1
Griffith’s experiment demonstrating evidence for a transforming factor, later identified as DNA. In a series of experiments, mice were injected with live or killed encapsulated or nonencapsulated Streptococcus pneumoniae, as indicated in experiments A through D. The key experiment is D, showing that the killed encapsulated bacteria could supply a factor that allowed the nonencapsulated bacteria to kill mice. Besides providing key support for the importance of the capsule for pneumococcal virulence, experiment D also illustrates the principle of DNA as the fundamental basis of genetic transformation. (Reproduced by permission from McClane BA, Mietzner TA: Microbial Pathogenesis: A Principles-Oriented Approach. Fence Creek Publishing, 1999.)
Recombinant DNA technology was born in the 1960s and 1970s when investigations with bacteria revealed the presence of restriction enzymes, proteins that cleave DNA at specific sites, giving rise to DNA restriction fragments. Plasmids were identified as small genetic elements carrying genes and capable of independent replication in bacteria and yeasts. The introduction of a DNA restriction fragment into a plasmid allows the DNA fragment to be amplified many times. Amplification of specific regions of DNA also can be achieved with bacterial enzymes using polymerase chain reaction (PCR) or other enzyme-based method of nucleic acid amplification. DNA amplified by these sources and digested with appropriate restriction enzymes can be inserted into plasmids. Genes can be placed under control of high-expression bacterial promoters that allow encoded proteins to be expressed at increased levels. Bacterial genetics have fostered the development of genetic engineering not only in prokaryotes but also in eukaryotes. This technology is responsible for the tremendous advances in the field of medicine realized today.
NUCLEIC ACIDS AND THEIR ORGANIZATION IN EUKARYOTIC, PROKARYOTIC, AND VIRAL GENOMES
Genetic information in bacteria is stored as a sequence of DNA bases (Figure 7-2). Most DNA molecules are double stranded, with complementary bases (A-T; G-C) paired by hydrogen bonding in the center of the molecule (Figure 7-3). The orientation of the two DNA strands is antiparallel: One strand is chemically oriented in a 5′→3′ direction, and its complementary strand runs 3′→5′. The complementarity of the bases enables one strand (template strand) to provide the information for copying or expression of information in the other strand (coding strand). The base pairs are stacked within the center of the DNA double helix, and they determine its genetic information. Each turn of the helix has one major groove and one minor groove. Certain proteins have the capacity to bind DNA and regulate gene expression by interacting predominately with the major groove, where atoms comprising the bases are more exposed. Each of the four bases is bonded to phospho-2′-deoxyribose to form a nucleotide. The negatively charged phosphodiester backbone of DNA faces the solvent. The length of a DNA molecule is usually expressed in thousands of base pairs, or kilobase pairs (kbp). Whereas a small virus may contain a single DNA molecule of less than 0.5 kbp, the single DNA genome that encodes Escherichia coli is greater than 4000 kbp. In either case, each base pair is separated from the next by about 0.34 nm, or 3.4 × 10−7 mm, so that the total length of the E coli chromosome is roughly 1 mm. Because the overall dimensions of the bacterial cell are roughly 1000-fold smaller than this length, it is evident that a substantial amount of folding, or supercoiling, contributes to the physical structure of the molecule in vivo.
FIGURE 7-2
A schematic drawing of the Watson-Crick structure of DNA, showing helical sugar-phosphate backbones of the two strands held together by hydrogen bonding between the bases. (Redrawn with permission from Snyder L, Champness W: Molecular Genetics of Bacteria, 2nd ed. Washington, DC: ASM Press, 2003. ©2003 American Society for Microbiology. No further reproduction or distribution is permitted without the prior written permission of American Society for Microbiology.)
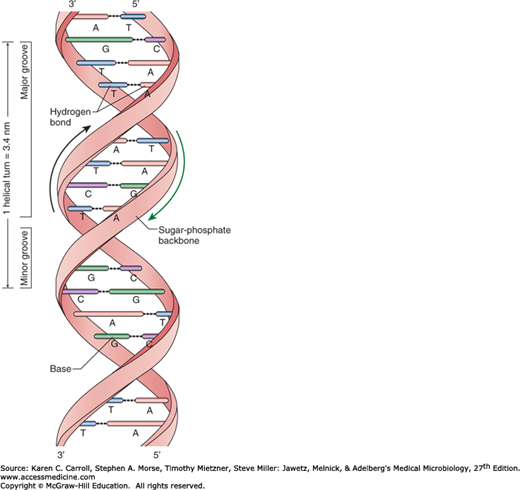
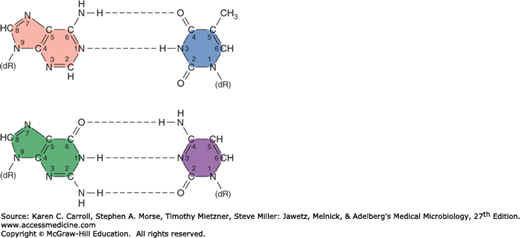
FIGURE 7-3
Normal base pairing in DNA. Top: Adenine-thymidine (A-T) pairing; bottom: guanine-cytosine (G-C) pair. Hydrogen bonds are indicated by dotted lines. Note that the G-C pairing shares three sets of hydrogen bonds, but the A-T pairing has only two. Consequently, a G-C interaction is stronger than an A-T interaction. dR, deoxyribose of the sugar-phosphate DNA backbone.
Ribonucleic acid (RNA) most frequently occurs in single-stranded form. The uracil base (U) replaces thymine base (T) in DNA, so the complementary bases that determine the structure of RNA are A-U and C-G. The overall structure of single-stranded RNA (ssRNA) molecules is determined by pairing between bases within the strand-forming loops, with the result that ssRNA molecules assume a compact structure capable of expressing genetic information contained in DNA.
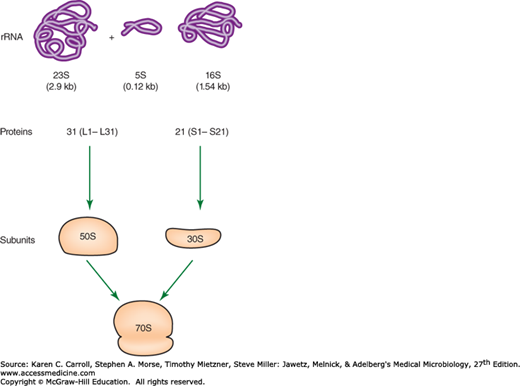
The most general function of RNA is communication of DNA gene sequences in the form of messenger RNA (mRNA) to ribosomes. These processes are referred to as transcription and translation. mRNA (referred to as +ssRNA) is transcribed as the RNA complement to the coding DNA strand. This mRNA is then translated by ribosomes. The ribosomes, which contain both ribosomal RNA (rRNA) and proteins, translate this message into the primary structure of proteins via aminoacyl-transfer RNAs (tRNAs). RNA molecules range in size from the small tRNAs, which contain fewer than 100 bases, to mRNAs, which may carry genetic messages extending to several thousand bases. Bacterial ribosomes contain three kinds of rRNA, with respective sizes of 120, 1540, and 2900 bases, and a number of proteins (Figure 7-4). Corresponding rRNA molecules in eukaryotic ribosomes are somewhat larger. The need for expression of an individual gene changes in response to physiologic demand, and requirements for flexible gene expression are reflected in the rapid metabolic turnover of most mRNAs. On the other hand, tRNAs and rRNAs—which are associated with the universally required function of protein synthesis—tend to be stable and together account for more than 95% of the total RNA in a bacterial cell. A few RNA molecules have been shown to function as enzymes (ribozymes). For example, the 23S RNA in the 50S ribosomal subunit (see Figure 7-4) catalyzes the formation of the peptide bond during protein synthesis.
FIGURE 7-4
The composition of a ribosome containing one copy each of the 16S, 23S, and 5S RNAs as well as many proteins. The proteins of the large 50S subunit are designated L1–L31. The proteins of the small 30S subunit are designated S1–S21. (Redrawn with permission from Snyder L, Champness W: Molecular Genetics of Bacteria, 2nd ed. Washington, DC: ASM Press, 2003. ©2003 American Society for Microbiology. No further reproduction or distribution is permitted without the prior written permission of American Society for Microbiology.)
The genome is the totality of genetic information in an organism. Almost all of the eukaryotic genome is carried on two or more linear chromosomes separated from the cytoplasm within the membrane of the nucleus. Diploid eukaryotic cells contain two homologues (divergent evolutionary copies) of each chromosome. Mutations, or genetic changes, frequently cannot be detected in diploid cells because the contribution of one gene copy compensates for changes in the function of its homologue. Whereas a gene that does not achieve phenotypic expression in the presence of its homologue is recessive, a gene that overrides the effect of its homologue is dominant. The effects of mutations can be most readily discerned in haploid cells, which carry only a single copy of most genes. Yeast cells (which are eukaryotic) are frequently investigated because they can be maintained and analyzed in the haploid state. Of the entirety of the human genome, only 2% is considered coding DNA, the rest is noncoding DNA.
Eukaryotic cells contain mitochondria and, in the case of plants, chloroplasts. Within each of these organelles is a circular molecule of DNA that contains a few genes whose function relates to that particular organelle. Most genes associated with organelle function, however, are carried on eukaryotic chromosomes. Many yeast contain an additional genetic element, an independently replicating 2-μm circle containing about 6.3 kbp of DNA. Such small circles of DNA, termed plasmids or episomes, are frequently associated with prokaryotes. The small size of plasmids renders them amenable to genetic manipulation and, after their alteration, may allow their introduction into cells. Therefore, plasmids are commonly used in genetic engineering.
Repetitive DNA, which occurs in large quantities in eukaryotic cells, has been increasingly identified in prokaryotes. In eukaryotic genomes, repetitive DNA is infrequently associated with coding regions and is located primarily in extragenic regions. These short-sequence repeats (SSRs) or short tandemly repeated (STR) sequences occur in several to thousands of copies dispersed throughout the genome. The presence of prokaryotic SSRs and STRs is well documented, and some show extensive length-polymorphisms. This variability is thought to be caused by slipped-strand mispairing and is an important prerequisite for bacterial phase variation and adaptation. Many eukaryotic genes are interrupted by introns, intervening sequences of DNA that are missing in processed mRNA when it is translated. Introns have been observed in archaebacterial genes but with a few rare exceptions are not found in eubacteria (see Table 3-3).
Most prokaryotic genes are carried on the bacterial chromosome. And with few exceptions, bacterial genes are haploid. Genome sequence data from more than 340 microbial genomes demonstrate that most prokaryotic genomes (>90%) consist of a single circular DNA molecule containing from 580 kbp to more than 5220 kbp of DNA (Table 7-1). A few bacteria (eg, Brucella melitensis, Burkholderia pseudomallei, and Vibrio cholerae) have genomes consisting of two circular DNA molecules. Many bacteria contain additional genes on plasmids that range in size from several to 100 kbp. In contrast to eukaryotic genomes, 98% of bacterial genomes are coding sequences.
| Organism | Size (kbp) | |
|---|---|---|
| Prokaryotes | ||
| Archae | Methanococcus jannaschii | 1660 |
| Archaeoglobus fulgidus | 2180 | |
| Eubacteria | Mycoplasma genitalium | 580 |
| Mycoplasma pneumoniae | 820 | |
| Borrelia burgdorferi | 910 | |
| Chlamydia trachomatis | 1040 | |
| Rickettsia prowazekii | 1112 | |
| Treponema pallidum | 1140 | |
| Chlamydia pneumoniae | 1230 | |
| Helicobacter pylori | 1670 | |
| Haemophilus influenzae | 1830 | |
| Francisella tularensis | 1893 | |
| Coxiella burnetii | 1995 | |
| Neisseria meningitides serogroup A | 2180 | |
| Neisseria meningitides serogroup B | 2270 | |
| Brucella melitensisa | 2117 + 1178 | |
| Mycobacterium tuberculosis | 4410 | |
| Escherichia coli | 4640 | |
| Bacillus anthracis | 5227 | |
| Burkholderia pseudomalleia | 4126 + 3182 | |
| Bacteriophage | Lambda | 48 |
| Viruses | Ebola | 19 |
| Variola major | 186 | |
| Vaccinia | 192 | |
| Cytomegalovirus | 229 |
Covalently closed DNA circles (bacterial chromosomes and plasmids), which contain genetic information necessary for their own replication, are called replicons or episomes. Because prokaryotes do not contain a nucleus, a membrane does not separate bacterial genes from cytoplasm as in eukaryotes.
Some bacterial species are efficient at causing disease in higher organisms because they possess specific genes for pathogenic determinants. These genes are often clustered together in the DNA and are referred to as pathogenicity islands. These gene segments can be quite large (up to 200 kbp) and encode a collection of virulence genes. Pathogenicity islands (1) have a different G + C content from the rest of the genome; (2) are closely linked on the chromosome to tRNA genes; (3) are flanked by direct repeats; and (4) contain diverse genes important for pathogenesis, including antibiotic resistance, adhesins, invasins, and exotoxins, as well as genes that can be involved in genetic mobilization.
Genes essential for bacterial growth (often referred to as “housekeeping genes”) can be carried on the chromosome or may be found on plasmids that carry genes associated with specialized functions (Table 7-2). Many plasmids also encode genetic sequences that mediate their transfer from one organism to another (eg, those involved with sex pili) as well as others associated with genetic acquisition or rearrangement of DNA (eg, transposase). Therefore, genes with independent evolutionary origins may be assimilated by plasmids that are widely disseminated among bacterial populations. A consequence of such genetic events has been observed in the swift spread among bacterial populations of plasmid-borne resistance to antibiotics after their liberal use in hospitals.
| Organism | Activity |
|---|---|
| Pseudomonas species | Degradation of camphor, toluene, octane, salicylic acid |
| Bacillus stearothermophilus | α-Amylase |
| Alcaligenes eutrophus | Utilization of H2 as oxidizable energy source |
| Escherichia coli | Sucrose uptake and metabolism, citrate uptake |
| Klebsiella species | Nitrogen fixation |
| Streptococcus (group N) | Lactose utilization, galactose phosphotransferase system, citrate metabolism |
| Rhodospirillum rubrum | Synthesis of photosynthetic pigment |
| Flavobacterium species | Nylon degradation |
Transposons are genetic elements that contain several genes, including those necessary for their migration from one genetic locus to another. In doing so, they create insertion mutations. The involvement of relatively short transposons (0.75–2.0 kbp long), known as insertion elements, produces the majority of insertion mutations. These insertion elements (also known as insertion sequence [IS] elements) carry only the genes for enzymes needed to promote their own transposition to another genetic locus but cannot replicate on their own. Almost all bacteria carry IS elements, with each species harboring its own characteristic IS elements. Related IS elements can sometimes be found in different bacteria, implying that at some point in evolution they have crossed species barriers. Plasmids also carry IS elements, which are important in the formation of high-frequency recombinant (Hfr) strains (see below). Complex transposons carry genes for specialized functions such as antibiotic resistance and are flanked by insertion sequences.
Transposons do not carry the genetic information required to encode their own replication, and therefore their propagation depends on their physical integration with a bacterial replicon. This association is fostered by enzymes that confer the ability of transposons to form copies of themselves; these enzymes may allow the transposons to integrate within the same replicon or an independent replicon. The specificity of sequence at the insertion site is generally low, so that transposons often seem to insert in a random pattern, but they tend to favor regions encoding tRNAs. Many plasmids are transferred among bacterial cells, and insertion of a transposon into such a plasmid is a vehicle that leads to the transposon’s dissemination throughout a bacterial population.
Viruses are capable of survival, but not growth, in the absence of a cell host. Replication of the viral genome depends on the metabolic energy and the macromolecular synthetic machinery of the host. Frequently, this form of genetic parasitism results in debilitation or death of the host cell. Therefore, successful propagation of the virus requires (1) a stable form that allows the virus to survive in the absence of its host, (2) a mechanism for invasion of a host cell, (3) genetic information required for replication of the viral components within the cell, and (4) additional information that may be required for packaging the viral components and liberating the resulting virus from the host cell.
Distinctions are frequently made between viruses associated with eukaryotes and viruses associated with prokaryotes, the latter being termed bacteriophage or phage. When viral DNA is integrated into the eukaryotic genome, it is called a provirus; when a phage is integrated into a bacterial genome or episome, it is called a prophage. With more than 5000 isolates of known morphology, phages constitute the largest of all viral groups. Much of our understanding of viruses—indeed, many fundamental concepts of molecular biology—has emerged from investigation of bacteriophages.
Bacteriophages occur in more than 140 bacterial genera and in many different habitats. The nucleic acid molecule of bacteriophages is surrounded by a protein coat. Considerable variability is found in the nucleic acid of phages. Many phages contain double-stranded DNA (dsDNA); others contain double-stranded RNA (dsRNA), ssRNA, or single-stranded DNA (ssDNA). Unusual bases such as hydroxymethylcytosine are sometimes found in the phage nucleic acid. Bacteriophages exhibit a wide variety of morphologies. Many phages contain specialized syringe-like structures (tails) that bind to receptors on the cell surface and inject the phage nucleic acid into a host cell (Figure 7-5).

Phages can be distinguished on the basis of their mode of propagation. Lytic phages produce many copies of themselves as they kill their host cell. The most thoroughly studied lytic phages, the T-even (eg, T2, T4) phages of E coli, demonstrate the need for precisely timed expression of viral genes to coordinate events associated with phage formation. Temperate phages are able to enter a nonlytic prophage state in which replication of their nucleic acid is linked to replication of host cell DNA. Bacteria carrying prophages are termed lysogenic because a physiologic signal can trigger a lytic cycle resulting in death of the host cell and liberation of many copies of the phage. The best characterized temperate phage is the E coli phage λ (lambda). Filamentous phages, exemplified by the well-studied E coli phage M13, are exceptional in several respects. Their filaments contain ssDNA complexed with protein and are extruded from their bacterial hosts, which are debilitated but not killed by the phage infection. Engineering of DNA into phage M13 has provided single strands that are valuable sources for DNA analysis and manipulation.
REPLICATION
dsDNA is synthesized by semiconservative replication. As the parental duplex unwinds, each strand serves as a template (ie, the source of sequence information) for DNA replication. New strands are synthesized with their bases in an order complementary to that in the preexisting strands. When synthesis is complete, each daughter molecule contains one parental strand and one newly synthesized strand.
The replication of bacterial DNA begins at one point and moves in both directions (ie, bidirectional replication). In the process, the two old strands of DNA are separated and used as templates to synthesize new strands (semiconservative replication). The structure where the two strands are separated and the new synthesis is occurring is referred to as the replication fork. Replication of the bacterial chromosome is tightly controlled, and the number of each chromosomes (when more than one is present) per growing cell falls between one and four. Some bacterial plasmids may have as many as 30 copies in one bacterial cell, and mutations causing relaxed control of plasmid replication can result in 10-fold higher copy numbers.
The replication of circular double-stranded bacterial DNA begins at the ori locus and involves interactions with several proteins. In E coli, chromosome replication terminates in a region called ter. The origin (ori) and termination sites (ter) for replication are located at opposite points on the circular DNA chromosome. The two daughter chromosomes are separated, or resolved, before cell division, so that each progeny cell gets one of the daughter DNAs. This is accomplished with the aid of topoisomerases, enzymes that alter the supercoiling of dsDNA. The topoisomerases act by transiently cutting one or both strands of the DNA to relax the coil and extend the DNA molecule. Because bacterial topoisomerases are essential and unique, they are targets of antibiotics (eg, quinolones). Similar processes used in the replication of bacterial chromosomes are used in the replication of plasmid DNA, except that, in some cases, replication is unidirectional.
Bacteriophages exhibit considerable diversity in the nature of their nucleic acid, and this diversity is reflected in different modes of replication. Fundamentally different propagation strategies are exhibited by lytic and temperate phages. Lytic phages produce many copies of themselves in a single burst of growth. Temperate phages establish themselves as prophages either by becoming part of an established replicon (chromosome or plasmid) or by forming an independent replicon.
The dsDNA of many lytic phages is linear, and the first stage in their replication is the formation of circular DNA. This process depends upon cohesive ends, complementary single-stranded tails of DNA that hybridize. Ligation, formation of a phosphodiester bond between the 5′ and 3′ DNA ends, gives rise to covalently closed circular DNA that may undergo replication in a manner similar to that used for other replicons. Cleavage of the circles produces linear DNA that is packaged inside protein coats to form daughter phages.
The ssDNA of filamentous phages is converted to a circular double-stranded replicative form. One strand of the replicative form is used as a template in a continuous process that produces ssDNA. The template is a rolling circle, and the ssDNA it produces is cleaved and packaged with protein for extracellular extrusion.
The ssRNA phages are among the smallest extracellular particles containing information that allows for their own replication. The RNA of phage MS2, for example, contains (in fewer than 4000 nucleotides) three genes that can act as mRNA following infection. One gene encodes the coat protein, and another encodes an RNA polymerase that forms a dsRNA replicative form. ssRNA produced from the replicative form is the core of new infective particles.
The temperate bacteriophage E coli phage P1 genome, when undergoing a lysogenic cycle, exists as an autonomous plasmid in the bacterium. The dsDNA of other temperate bacteriophages is established as a prophage by its insertion into the bacterial host chromosome. The site of insertion may be quite specific, as typified by integration of E coli phage λ at a single int locus on the bacterial chromosome. The specificity of integration is determined by identity of the shared DNA sequence by the int chromosomal locus and a corresponding region of the phage genome. Other temperate phages, such as E coli phage Mu, integrate in any of a wide range of chromosomal sites and in this aspect resemble transposons.
Prophages contain genes required for lytic replication (also called vegetative replication), and expression of these genes is repressed during maintenance of the prophage state. A manifestation of repression is that an established prophage frequently confers cellular immunity against lytic infection by similar phage. A cascade of molecular interactions triggers derepression (release from repression), so that a prophage undergoes vegetative replication, leading to formation of a burst of infectious particles. Stimuli such as ultraviolet (UV) light may cause derepression of the prophage. The switch between lysogeny—propagation of the phage genome with the host—and vegetative phage growth at the expense of the cell may be determined in part by the cell’s physiologic state. A nonreplicating bacterium will not support vegetative growth of phage, but a vigorously growing cell contains sufficient energy and building blocks to support rapid phage replication.
TRANSFER OF DNA
The haploid nature of the bacterial genome might be presumed to limit the genomic plasticity of a bacterium. However, the ubiquity of diverse bacteria in a complex microbiome provides a fertile gene pool that contributes to their remarkable genetic diversity through mechanisms of genetic exchange. Bacterial genetic exchange is typified by transfer of a relatively small fragment of a donor genome to a recipient cell followed by genetic recombination. Bacterial genetic recombination is quite unlike the fusion of gametes observed with eukaryotes; it demands that this donor DNA be replicated in the recombinant organism. Replication can be achieved either by integration of the donor DNA into the recipient’s chromosome or by establishment of donor DNA as an independent episome.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


