CHAPTER 39 Histocompatibility
HLA and other systems
The human major histocompatibility complex
History
What has become known as the major histocompatibility complex (MHC) was initially identified in the early 1900s, but it was not until the late 1930s that studies began to focus on graft acceptance (histocompatibility) and antigen response phenotypes (H-2) in different strains of mice.1,2 In the 1950s, Dausset detected the first histocompatibility antigens in humans, the MHC class I antigens, with antibodies from multiply transfused patients.3,4 These antibodies revealed in the human population differing patterns of binding to white blood cells (leukocytes) and each pattern of binding came to define a human leukocyte antigen (HLA) specificity.5,6 These HLA specificities were later determined to be encoded by three distinct polymorphic loci, HLA-A, HLA-B and HLA-C. The human MHC class II antigens were initially described via their ability to stimulate the proliferation of T-cells from one individual when mixed with lymphocytes from a second individual.7 Each pattern of T-cell reactivity (allorecognition) to a panel of homozygous typing cells (HTC) was assigned an HLA-D phenotype.8 It is now known that the HLA-D phenotypes are due to T-cell allorecognition of the products of the MHC class II loci, primarily HLA-DR. HLA-DQ and HLA-DP make minor contributions to these phenotypes. The genes specifying both class I and class II antigens are tightly clustered in a single chromosomal region, the MHC.
Genomic organization
The human MHC is a genetic region located on the short arm of chromosome 6 (6p21.3) extending approximately 4 megabases (Mb) (Fig. 39.1). The MHC encodes over 250 genes and pseudogenes of which at least 150 are expressed as proteins.9,10 This genetic complex is divided into three regions: (centromeric) class II, class III and class I (telomeric). Although the proteins encoded within the MHC participate in a variety of functions, approximately 40% are devoted to immune system functions.
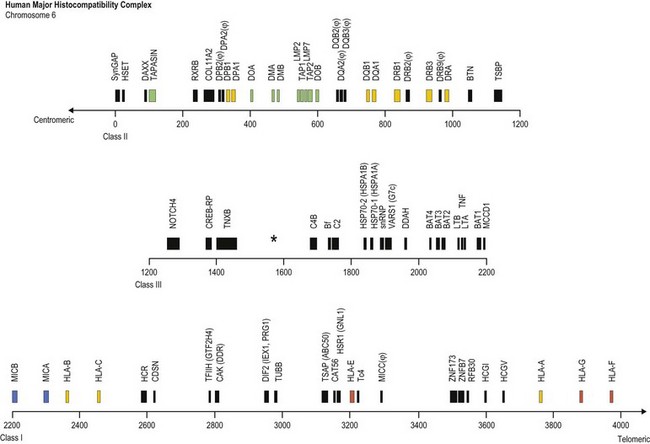
Fig. 39.1 Map of the human major histocompatibility complex (MHC) located on the short arm of chromosome 6. The map (drawn closely to scale) is divided into three regions (class II, class III and class I) and shows the relative positions of some of the MHC encoded genes and pseudogenes (ψ). The class II region encodes the expressed classical HLA class II molecules (yellow). The number of HLA-DR B (DRB) genes and pseudogenes differs for different haplotypes (DR52 haplotype shown; Fig. 39.2). Genes encoding protein products intimately involved in MHC class I and class II molecule assembly and in peptide processing and binding (green) also are shown. The class III region contains several immune system relevant genes and varies in length among individual chromosomes in the area encoding C4B (asterisk). The class I region encodes the classical HLA class I heavy chain proteins (yellow). This region also encodes the expressed nonclassical HLA class I genes (red) and MHC class I chain-related genes (blue).
(The figure was generated from data contained in references.9,13)
The class II region (~1.2 Mb) contains at least 34 expressed genes and 16 pseudogenes and spans from SynGAP (Ras-GTPase-activating protein, centromeric) to TSBP (testis-specific basic protein, telomeric).11 This region includes the genes that encode for the classical class II molecules (HLA-DR, -DQ and -DP). In addition, gene products involved in MHC class I antigen processing (LMP2 and LMP7, the large multifunctional proteosome genes), peptide transport (TAP1 and TAP2, the transporter associated with antigen processing genes) and complex assembly (tapasin) and gene products involved in MHC class II complex assembly (HLA-DM and HLA-DO) are encoded in this region.
The class III region (~1 Mb) extends from NOTCH4 (transmembrane receptor involved in cell differentiation and development, centromeric) to MCCD1 (mitochondrial coiled-coil domain protein 1, telomeric).12,13 On average, this region contains 1 gene every 10 kilobases (kb) and is the most gene dense region in the human genome with approximately 72% of it being transcribed. The class III region encodes at least 62 expressed genes including complement components (e.g., C2 and C4B), heat shock proteins (e.g., Hsp70-1 and Hsp70-2) and cytokines of the tumor necrosis factor family (e.g., TNF and LTA). Some individuals have duplications in the area encoding complement component C4B; thus, this area can vary in length.
The class I region (~1.85 Mb) from MICB (centromeric) to HLA-F (telomeric) encodes at least 118 genes; 57 expressed genes and 61 pseudogenes.14 In some instances, an additional ~0.95 Mb to TRIM27 (tripartite motif 27, a transcription factor, telomeric) is included and called the extended class I region.9 This region includes the classical class I genes (HLA-A, -B and -C) and the nonclassical class I genes (HLA-E, -F, and -G). This region also encodes the MHC class I chain-related (MIC) genes (MICA and MICB). The focus of this chapter is on the MHC encoded gene products involved in histocompatibility, primarily the classical human leukocyte antigens. Other MHC and nonMHC encoded genes that participate in histocompatibility are also covered.
The human leukocyte antigens
Genomic organization
The heavy chains of the classical MHC class I (class Ia) molecules are encoded in the class I region of the MHC and associate with beta 2 microglobulin (encoded on chromosome 15) to form the mature class I molecule. The gene order within the MHC is shown in Fig. 39.1. Each of the classical MHC class I heavy chains is encoded by a single gene that is divided into 8 exons.15 Exon 1 encodes the 5′ untranslated region (UTR) and the hydrophobic signal sequence. The signal sequence directs insertion of the protein into the membrane at the cell surface and is cleaved from the mature protein. The extracellular portion of the class I heavy chain is encoded by exons 2–4. Exon 5 encodes the transmembrane region and exons 6 and 7 encode the intracellular cytoplasmic tail. The 3′ UTR and the polyadenylation (poly(A)) site are encoded by exon 8. The mRNA, which is translated into protein, includes all eight exons after removal by splicing of the intervening sequences (introns).
The class II region of the MHC contains three subregions (centromeric) HLA-DP, -DQ and -DR (telomeric). Each encodes at least one cell surface class II molecule (Fig. 39.1). The class II molecules are noncovalently associated heterodimers that consist of an α chain and a β chain.15,16 Each chain is encoded by a separate gene, an A gene for the α chain and a B gene for the β chain. The expressed HLA-DP heterodimer is encoded by the DPA1 and DPB1 genes. The HLA-DP subregion contains two DP pseudogenes, DPA2 and DPB2. The HLA-DQ subregion contains two A (DQA1 and DQA2) and three B (DQB1, DQB2 and DQB3) genes. The expressed HLA-DQ heterodimer is encoded by the DQA1 and DQB1 genes, while the remaining DQ genes are pseudogenes. Each individual has two copies of chromosome 6 and, thus, two copies of each of the expressed HLA-DP and HLA-DQ genes. These genes are polymorphic and, consequently, an individual can have two different expressed A genes and two different expressed B genes for HLA-DP and for HLA-DQ. While not all combinations form,17 the products of some of these genes can associate in several αβ combinations, regardless of chromosomal origin. Therefore, an individual could express up to four different HLA-DP and up to four different HLA-DQ molecules.
The HLA-DR subregion is more complex.18,19 A HLA-DR molecule composed of a conserved α chain encoded by the DRA gene and a polymorphic β chain encoded by the DRB1 gene is almost always present. This is the major class II molecule expressed on the cell surface. An additional eight DRB genes and pseudogenes have been identified in the HLA-DR subregion. The number of DRB genes present and the number of expressed DRB gene products is characteristic of each chromosome (haplotype) a person inherits (Fig. 39.2). For example, the DR1 haplotype carries two DRB genes, the expressed DRB1 gene and a DRB6 pseudogene. The DR8 haplotype carries only one DRB gene, the expressed DRB1 gene. Other DR subregion haplotypes can encode a second expressed HLA-DR molecule composed of the DRA gene product associated with a DRB3 gene product (DR52 molecule), a DRB4 gene product (DR53 molecule) or a DRB5 gene product (DR51 molecule) and can contain one to three DRB pseudogenes. The designations DR51, DR52 and DR53 are antibody (serologically) defined.
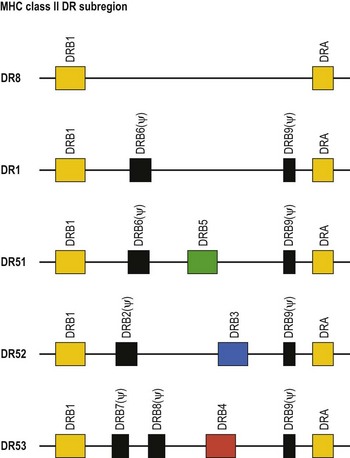
Fig. 39.2 Relative gene organization of the DR subregion of different DR haplotype groups. The protein products of the DRA and DRB1 genes (yellow) combine to form the primary expressed HLA-DR molecule. The protein products of the DRB5 (green), DRB3 (blue) and DRB4 (red) genes encoded by the DR51, DR52 and DR53 haplotype groups, respectively, also form expressed functional DR molecules in combination with the DRA polypeptide. The DRB pseudogenes (ψ) are shown in black. Table 39.4 lists the alleles associated with each haplotype.
The A genes, which encode the α chains of class II molecules, contain five exons.15,16 The 5′ UTR and hydrophobic signal sequence are encoded by exon 1, like the class I genes. Exons 2 and 3 encode the extracellular domains. Exon 4 encodes the connecting peptide, the transmembrane region, the intracellular cytoplasmic tail and a portion of the 3′ UTR. The remainder of the 3′ UTR and the poly(A) signal are encoded by exon 5. Each class II β chain is encoded by a B gene divided into six exons. Exons 1–3 are similar to that of the A genes. Exon 4 encodes the connecting peptide and transmembrane region, while exon 5 encodes the cytoplasmic tail. The 3′ UTR and poly(A) signal are encoded by exon 6. All exons and introns are transcribed into RNA for the class II A and B genes. Again, introns are removed by splicing to form the mRNA that is translated into protein.
Diversity
The nucleotide sequences of many of the HLA genes differ among individuals. These sequence variants are termed alleles; genes with many alleles are termed polymorphic. Alleles of a locus may differ by a single nucleotide to many nucleotides potentially resulting in changes in the amino acid sequence of the protein specified by that gene. The classical HLA class I and class II loci are the most polymorphic loci in humans. The HLA-B and HLA-DRB1 loci have over 1100 and 650 known alleles, respectively (Tables 39.1, 39.2).20,21 In contrast to non-HLA genes, the nucleotide differences found among HLA alleles are usually nonsynonymous (alter the amino acid sequence) and are focused in the exon(s) encoding the most functionally important region of the HLA molecule, the antigen binding site.18 It is thought that this diversity has been maintained to provide the human population with the capacity to recognize a diverse repertoire of pathogenic peptides.22–24 Unfortunately, the allelic differences in HLA molecules expressed on the cells of different individuals can be recognized as foreign when tissue is grafted from one individual to another.
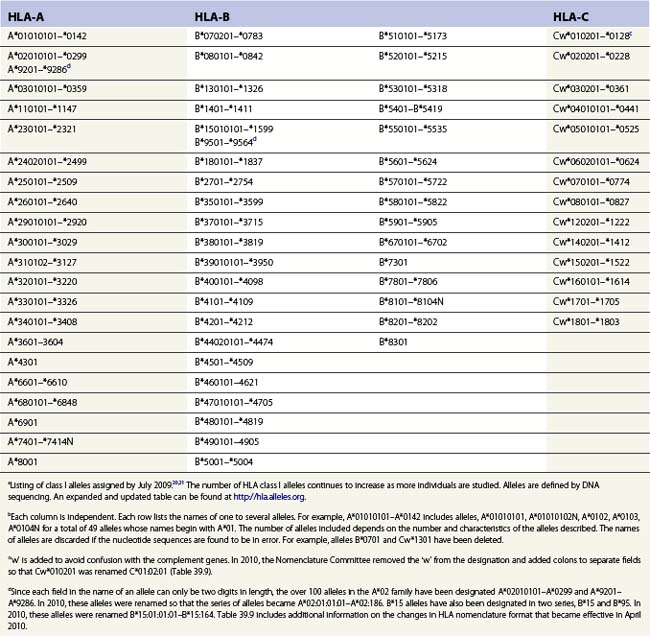
Table 39.2 HLA class II allelesa,b
| DR | DQ | DP |
|---|---|---|
| DRA*0101–*010202c | DQA1*010101–0107h | DPA1*010301–*0110j |
| DRB1*010101–*0122d | DQA1*0201 | DPA1*020101–*0204 |
| DRB1*03010101–*0348 | DQA1*030101–*0303 | DPA1*0301–*0303 |
| DRB1*040101–*0478 | DQA1*040101–*0404 | DPA1*0401 |
| DRB1*07010101–*0717 | DQA1*050101–*0509 | DPB1*010101–*9901k |
| DRB1*080101–*0836 | DQA1*060101–*0602 | |
| DRB1*090102–*0908 | DQB1*020101–*0205i | |
| DRB1*100101–*1003 | DQB1*030101–*0325 | |
| DRB1*110101–*1181 | DQB1*0401–*0403 | |
| DRB1*120101–*1219 | DQB1*050101–*0505 | |
| DRB1*130101–*1392 | DQB1*060101–*0635 | |
| DRB1*140101–*1490 | ||
| DRB1*15010101–*1533 | ||
| DRB1*160101–*1613N | ||
| DRB3*01010201–*0113e | ||
| DRB3*0201–*0224 | ||
| DRB3*030101–*0303 | ||
| DRB4*01010101–*0107f | ||
| DRB4*0201N | ||
| DRB4*0301N | ||
| DRB5*010101–*0113g | ||
| DRB5*0202–*0205 |
a Listing of class II alleles assigned by July 2009.20,21 The number of HLA class II alleles continues to increase as more individuals are studied. Alleles are defined by DNA sequencing. An expanded and updated table can be found at http://hla.alleles.org. A description of the nomenclature in this table can be found in Table 39.9.
c Alleles of the DRA locus. The differences among these DR alpha chain alleles are not considered important for transplantation matching.
d Alleles of the DRB1 locus. Most haplotypes contain a DRB1 locus.
e Alleles of the DRB3 locus, the second expressed DR molecule in haplotypes carrying DRB1*03, *11, *12, *13, *14 alleles.
f Alleles of the DRB4 locus, the second expressed DR molecule in haplotypes carrying DRB1*04, *07, *09 alleles.
g Alleles of the DRB5 locus, the second expressed DR molecule in haplotypes carrying DRB1*15, *16 alleles.
h Alleles of the DQA1 locus. DQA1 allelic products pair with DQB1 allelic products to form the DQ molecule.
j Alleles of the DPA1 locus. DPA1 allelic products pair with DPB1 allelic products to form the DP molecule.
k Alleles of the DPB1 locus. The approach to naming DPB1 alleles was slightly different than that used for other loci because of the lack of serologic information.20
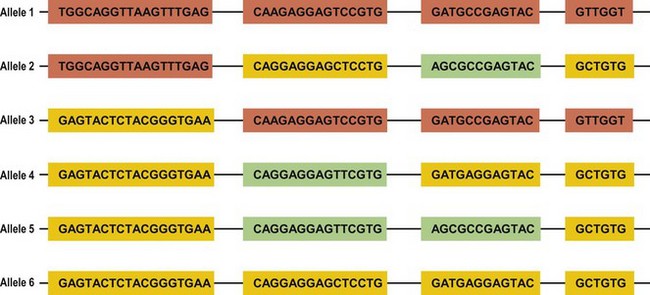
Several mechanisms are hypothesized to have generated this HLA diversity over evolutionary time. The majority of the polymorphism is hypothesized to have arisen by the non-reciprocal exchange of short polymorphic regions or cassettes among alleles, a process referred to as gene conversion. As a result, the HLA alleles are patchworks of polymorphic cassettes, each cassette shared by some of the other alleles at the locus, embedded in a conserved framework (Fig. 39.3). Exchange of cassettes among alleles at different loci, reciprocal recombination involving the exchange of entire exons, and mutation also have contributed to HLA diversity.18,25
Each individual inherits two copies of the chromosome carrying the MHC, one from each parent, and thus has two copies of each gene in the MHC. Individuals who carry two identical alleles at a locus are homozygous; individuals with two different alleles at a locus are heterozygous. Because the HLA genes are located within a small genetic distance, they are usually inherited as a block unless separated by recombination. The block, a specific set of alleles at the multiple HLA loci inherited together from a parent, is termed a HLA haplotype. Fig. 39.4 illustrates the inheritance of HLA-A, -B, and -DRB1 alleles within a family. By convention, the paternal haplotypes are generally designated a and b and the maternal haplotypes, c and d. Thus, there are four possible MHC genotypes in the offspring: ac, ad, bc, and bd. Because the chances of inheriting a given genotype are random, the probability of occurrence of any one of the four genotypes is one in four in a mating. In a family with five children, at least two of the children will be MHC identical unless recombination has occurred.
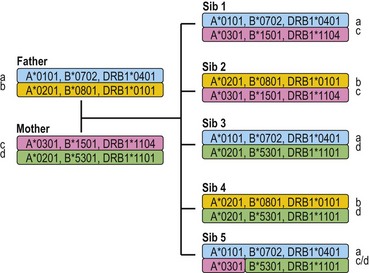
Fig. 39.4 The inheritance of HLA alleles and haplotypes within a family. Paternal haplotypes are labeled a,b; maternal haplotypes, c,d. Sibling 5 inherits a recombinant chromosome from the mother. Not all HLA genes are shown. The HLA nomenclature used in the figure is described in Table 39.9.
The alleles in the MHC complex can be reshuffled by crossing over between homologous chromosomes during the generation of sperm or eggs. The frequency of recombination across the MHC from HLA-A to HLA-DPB1 can range from 0.7 to 4.3%.26 Studies in humans suggest that there are several sites at which recombination preferentially occurs within the MHC, particularly between HLA-B and HLA-DRB1 and between HLA-DQB1 and HLA-DPB1.26,27 Studies comparing MHC-identical sib pairs versus haplotype mismatched sib pairs and unrelated individuals show that recombination rates can vary up to sixfold between individuals with different MHC haplotypes and suggest a genetic influence within the MHC on recombination rates.26 On average, the frequency of recombination between HLA-A and HLA-B is 0.7%, between HLA-B and HLA-DRB1 is 1.0%, and between DQB1 and DPB1 is 0.8%. Recombinations between DQA1 and DRB1 loci and between B and C loci are very rare.
The HLA alleles and haplotypes found in individuals depend on their racial and ethnic backgrounds.28,29 For example, the allele DRB1*0302 is found in African Americans, but is only rarely observed in individuals of northern European or Asian descent. Likewise, the frequency of a combination of alleles on a single copy of chromosome 6 can differ among population groups. Table 39.3 lists the ten most common haplotypes identified in the African American population compared to the ranking of these haplotypes in several other US populations.29 For example, the most common haplotype in African Americans is A*3001, Cw*1701, B*4201, DRB1*0302 found at a frequency of 1.5%. This haplotype was ranked 37th in Hispanic Americans but was not observed in this sampling of European Americans and Asian Americans.
Table 39.3 The ten most common African American haplotypes and their ranking in individuals of other ethnicities from a US registrya,b
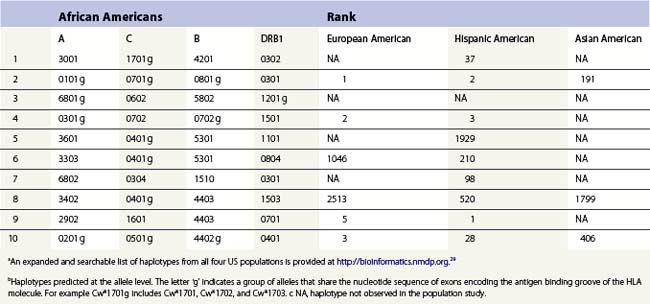
There are, however, some alleles and haplotypes that are found in many populations. For example, the allele A*0201 is a common allele in many US populations, being found in 29.6% of European Americans, 12.5% of African Americans, 9.5% of Asian Americans and 19.4% of Hispanic Americans.29 The most common haplotype in European Americans, A*0101, Cw*0701, B*0801, DRB1*0301, is the second most frequent haplotype in African Americans and Hispanic Americans but is the 191st most frequent haplotype in Asian Americans.
When large databases of HLA typed individuals are analyzed, only a small percent of potential HLA phenotypes are found. Using serologic assignments from an unrelated donor registry, of the predicted 19 536 660 HLA-A,-B,-DR phenotypes, only 1.6% were observed.30 This suggests that not all HLA allele combinations will be found. Indeed, some HLA haplotypes appear more frequently than expected. Linkage disequilibrium measures the degree of non-random association between alleles of separate loci. Apparently high disequilibrium across the DR-DQ subregion coupled with a lack of recombination have resulted in specific associations between DQA1 and DQB1 alleles and between DRB1 and DQ alleles although a single allele such as DQB1 may be associated with one of several partner alleles. For example, DQB1*0602 is found on the same chromosome as the DQA1 alleles DQA1*0102, or *0103 or *0104, but has not been observed with DQA1*0201, *0301, *0401, or *0501.31,32 These associations may differ among individuals of different racial/ethnic backgrounds. For example, DRB1*0901 is associated with DQB1*0201 in African Americans but with DQB1*0303 in individuals of northern European descent. Within the DR subregion, specific allele combinations at the several DRB loci are associated with families of DR haplotypes (Fig. 39.2). For example, the DRB3 locus is found in haplotypes carrying specific DRB1 alleles including DRB1*0301, *1101, *1201, *1301, and *1401 alleles (Table 39.4). In the class I region, associations between HLA-B and -C alleles have also been noted.29
| DR molecules encoded | Expressed DR loci included in haplotype | DRB1 alleles associated with haplotype |
|---|---|---|
| DR, DR51 | DRA, DRB1, DRB5 | DRB1*15, *16 |
| DR, DR52 | DRA, DRB1, DRB3 | DRB1*03, *11, *12, *13, *14 |
| DR, DR53 | DRA, DRB1, DRB4 | DRB1*04, *07, *09 |
| DR | DRA, DRB1 | DRB1*01, *08, *10 |
a It should be noted that there are exceptions to these associations. For examples, DRB1*15 haplotypes have been observed that lack a DRB5 locus and some DRB5 positive haplotypes lack a DRB1 locus. In addition, some DRB1*01 haplotypes carry a DRB5 locus.
Extension of linkage disequilibrium across longer regions of the MHC has resulted in associations between specific class I and class II alleles. The associations of multiple alleles result in extended haplotypes.33,34 The most well known extended haplotype is A*0101, Cw*0701, B*0801, DRB1*0301 which is common in northern Europe, appearing at a frequency of approximately 5–15%.28 It has been hypothesized that these associations may have been maintained in the population by selection, that is, associations between DR and DQ as well as associations within an extended haplotype might represent optimal combinations of immune response molecules. It is also likely that features of the genome structure limiting recombination or changes in the structure of the population, such as through admixture of different ethnic groups, have caused the linkage disequilibrium. Because alleles at various HLA loci are non-randomly associated, these associations enhance the frequency with which individuals share alleles across multiple HLA loci facilitating the selection of HLA identical individuals as tissue donors.
Expression
Classical MHC class I proteins are expressed by most nucleated cells, but the level of expression on the cell surface varies for different cell types. Cis-acting sequence blocks (enhancer A, interferon-stimulated response element (ISRE), W/S box, X box (previously known as site α) and Y box (previously known as enhancer B)) in the regulatory (promoter) region upstream of each class I gene control gene expression (Fig. 39.5A).35 Each promoter sequence block binds numerous proteins (transcription factors) that regulate the level of transcription of the gene and ultimately the amount of protein at the cell surface. For example, enhancer A binds stimulating protein 1 (Sp1) and various members of the NF-κB/rel family of transcription factors. Collectively, the complex is termed NF-κB. Normal class I gene expression requires the coordinated action of each of these regulatory elements; however, disruption of any one sequence block reduces, but does not appear to ablate, MHC class I expression.
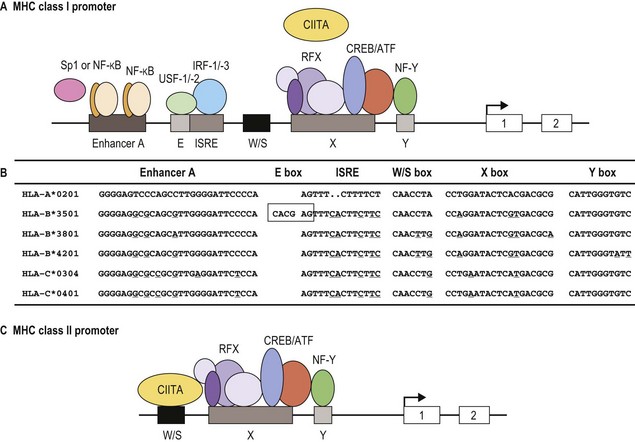
The amounts of HLA-A, -B and -C molecules expressed at the surface of a cell are not equal.36 HLA-A and -B are abundant with HLA-A expressed at somewhat higher levels than HLA-B, in many instances. HLA-C is expressed at very low levels in comparison accounting for about 10% of cell surface class I molecules. This is due to sequence variations in the regulatory blocks of each class I locus (Fig. 39.5B) which alter the type and affinity of transcription factor binding. For example, only NF-κB/rel family members bind to enhancer A in the HLA-A promoter, while enhancer A in the HLA-B promoter binds SP1 in addition to NF-κB/rel family members. The inclusion of SP1 binding may lead to less efficient expression of the HLA-B gene. There are also allele specific differences in the nucleotide sequence of these regulatory elements such that, for example, different HLA-B alleles are expressed at different levels. Additionally, some HLA-B allele promoter regions encode an E box regulatory element that binds the transcription factors upstream stimulatory factor 1 (USF-1) and USF-2. The presence of the E box correlates with reduced basal expression levels of these HLA-B alleles.35
MHC class I gene expression can be up-regulated by various cytokines.35,36 Interferon-γ (IFN-γ) performs a fundamental role in enhancing MHC class I expression by inducing increased gene transcription via transactivation of the ISRE. Again, locus and allele specific sequence differences in the ISRE result in different levels of transcriptional enhancement for each of the class I genes. Additionally, IFN-γ up-regulates expression of the class II transactivator (CIITA) further enhancing MHC class I gene expression. Other cytokines, such as tumor necrosis factor (TNF), can enhance the stimulatory effect of INF-γ on MHC class I gene expression via up-regulation of NF-κB that acts through enhancer A.
MHC class II protein expression is more limited than that of MHC class I. Cell surface HLA-DR, -DQ and -DP molecules are found primarily on professional antigen presenting cells (APC) and on other immune system cells such as T-lymphocytes.36,37 Professional APC are bone marrow derived cells dedicated to the task of peptide presentation by MHC molecules and include B-lymphocytes, macrophages, dendritic cells, thymic epithelial cells and Kupffer cells. IFN-γ can induce class II expression in other cell types. Like the class I genes, the promoter regions of the class II genes contain the cis-acting sequence blocks W/S box, X box and Y box (termed the SXY module) that regulate gene expression (Fig. 39.5C). This is a conserved regulatory module present in the promoters of a wide range of genes involved in antigen presentation which functions as a single regulatory block. The X and Y boxes bind several ubiquitous transcription factors, such as regulatory factor X (RFX) and nuclear factor Y (NF-Y), respectively, in a complex termed the enhanceosome.38,39
Occupancy of the class II gene regulatory elements by the enhanceosome is absolutely required, but not adequate for expression and IFN-γ induction of the A and B genes of HLA-DR, -DQ and -DP. CIITA also is required for class II gene expression.35,38 Cell type specific and IFN-γ induction of class II expression is the direct result of CIITA expression patterns. Constitutive expression of CIITA is confined to professional APC and other immune system cells and can be induced by IFN-γ in other cell types, paralleling expression of MHC class II. CIITA is recruited to the enhanceosome of the class II promoter by the S box. This is not the case for class I gene expression for which the S box apparently plays no role. All of the other transcription factors that regulate class II gene transcription are ubiquitously expressed and constitutively occupy the regulatory sequence blocks in the MHC class II gene promoters. Of interest, patients with bare lymphocyte syndrome (MHC class II deficiency) can have a defect in any one of a number of the transcription factors that bind to the SXY module or in CIITA. These patients still express MHC class I albeit at reduced levels.
HLA-DR, -DQ and -DP are not expressed at the same levels on cell surfaces, similar to expression of the different MHC class I molecules. HLA-DR is the most abundant MHC class II molecule expressed by cells. DRB1 is expressed at a higher level compared to DRB3 and DRB4.40,41 HLA-DQ is expressed at reduced levels and HLA-DP is the least abundant cell surface class II molecule. Like the regulatory elements in the promoters of class I genes, there are both locus and allele specific sequence differences in the regulatory elements of the class II genes.36 These sequence differences account for the dissimilar levels of class II molecule expression in two ways: 1) alter the binding affinity of the transcription factors and 2) allow binding of proteins that repress gene transcription of specific class II loci. For example, the X box in the HLA-DPA1 gene promoter region specifically binds the X box repressor protein which diminishes transcription of the HLA-DPA1 gene and reduces the overall level of HLA-DP on the cell surface.
Some pathogenic micoorganisms and many malignant cells down-regulate HLA gene expression to avoid recognition by the immune system.42–44 For example, human cytomegalovirus (CMV) interferes with IFN-γ induction of MHC class I and class II gene expression.45 To avoid detection by T-cells, many carcinomas and lymphomas lack cell surface HLA-A and HLA-B molecules due to defects in the expression or the binding of specific transcription factors to the promoter regulatory blocks of these genes. In many instances, expression of HLA-C in these malignant cells is unaffected, allowing the cell to avoid recognition by natural killer (NK) cells. In fact, alterations in MHC class I expression is very common (reported to be 70% or greater) in a variety of tumor types such as cervical, breast and colorectal cancers.42
Structure of class I and class II molecules
The classical class I molecules (HLA-A, -B and -C) are expressed on cell surfaces as a trimolecular complex. This complex is composed of the HLA class I polypeptide (heavy chain), beta 2 microglobulin (β2m) and a peptide. The MHC encoded class I heavy chains are glycosylated transmembrane proteins of approximately 340 amino acids (~44 kilodaltons (kD)) that belong to the immunoglobulin (Ig) superfamily of proteins.15,46 The extracellular portion of the class I heavy chain is composed of the amino-terminal 275 amino acids. The following 40 amino acids make up the hydrophobic transmembrane region and the carboxy-terminal 25 amino acids comprise the intracellular cytoplasmic tail. As an aside, soluble isoforms of the classical HLA molecules are produced and may have immunoregulatory roles.47
The extracellular portion of the class I heavy chain is divided into three domains, termed α1, α2 and α3 (Fig. 39.6A). Each domain is encoded by a separate exon (exons 2–4, respectively) and is approximately 90 amino acids long. The 3D structures of the extracellular portion of several class I molecules were resolved by X-ray crystallography.48,49 The α1 and α2 domains fold together to form a groove (termed the antigen binding groove) distal to the cell membrane that consists of a floor of eight antiparallel beta strands topped by two alpha helices fashioned into the walls. The membrane proximal α3 domain folds into a structure which is similar to that of the constant region domains of immunoglobulins (antibodies). This domain is composed of two antiparallel beta sheets, one with four strands and one with three strands. The sheets are linked by a disulfide bond. β2m (~12 kD) is non-covalently associated with the α3 domain of the class I heavy chain and is required for cell surface expression. Its 3D structure is identical to that of the α3 domain of the heavy chain.
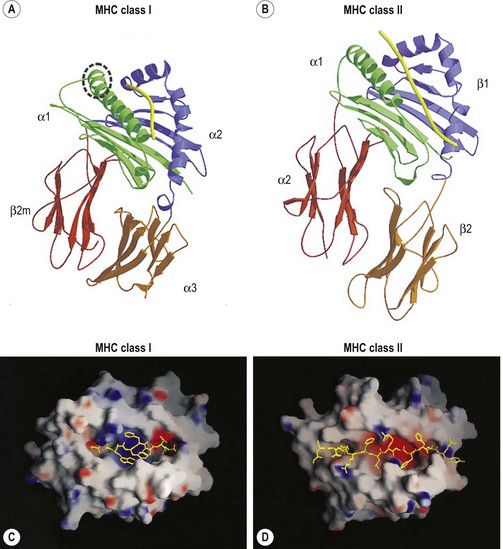
The peptide, the third component of the trimolecular complex, is generally 8–10 amino acids in length and non-covalently bound to the class I heavy chain.48,49 It lies in the groove formed by the α1 and α2 domains (Fig. 39.6C). The peptide is anchored at its amino- and carboxy-terminal ends by non-covalent bonds to amino acid residues in the class I heavy chain. There are pockets along the groove which accommodate amino acid side chains at various positions along the peptide. The pockets are unique for each class I molecule because polymorphic residues from the α1 and α2 domains participate in their formation. Each pocket has specific physical and chemical characteristics that are determined by the conserved and polymorphic class I residues that form the pocket. These characteristics, in turn, dictate which amino acid side chains are accommodated at the corresponding peptide position. This defines the peptide binding motif of each class I molecule and defines the overall character of the set of peptides bound (Table 39.5).50,51 For example, the protein encoded by A*1101 will accommodate a variety of ‘small’ amino acids at peptide postions 2, 3 and 6 and prefers basic amino acids at peptide position 9. However, each pocket does not make an equal contribution to peptide binding. Certain pockets, specific to each class I molecule, play a more predominant role and the corresponding peptide position is termed an anchor position. The preferred amino acids at an anchor position are termed anchor residues. Using the protein encoded by A*1101 again as an example, although peptide positions 2, 3 and 6 contribute to peptide binding, it is peptide position 9 that is the anchor position. Lysine and arginine are the anchor residues at this position with lysine preferred over arginine. It is of note that not all peptides that bind to an HLA molecule fully adhere to the defined peptide binding motif and that amino acids other than anchor residues can be found at anchor positions in these peptides. In the end, each class I molecule does bind a unique, large set of peptides and the peptide set shares particular sequence characteristics which are dictated by the amino acid residues that make up the groove of the HLA class I heavy chain.
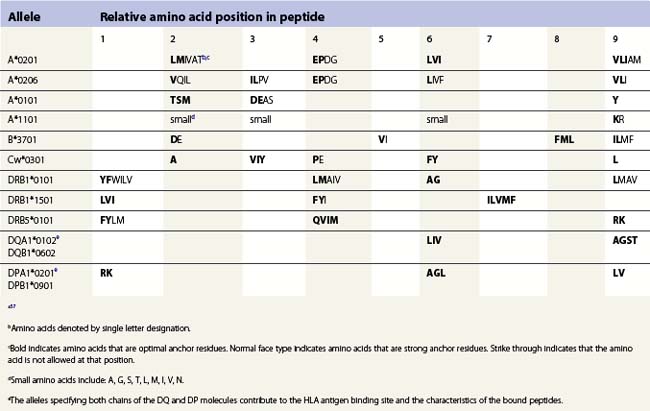
There are benefits to determining the peptide binding motif for HLA molecules. For example, these motifs can be used to identify antigenic peptides from pathogen proteins as candidates for use in peptide based vaccines. As another example, expression of specific HLA allelic products is associated with an increased risk of developing many autoimmune diseases.52,53 In most cases, this is thought to be the result of the differential binding capacity of HLA molecules for particular peptides. Thus, knowing the binding motif for a HLA molecule aids in the identification of the culprit peptide and allows for the design of synthetic peptides that mimic disease associated peptides for use in blocking autoimmune responses. Because the number of HLA allelic products is so large, algorithms have been developed for prediction of peptide binding to HLA molecules.54–57
The class II molecules are expressed on cell surfaces as a trimolecular complex, structurally analogous to the class I molecules, and consist of the class II α chain, the class II β chain and a peptide. Both the class II α (34 kD) and β (28 kD) chains are transmembrane glycoproteins and are Ig superfamily members, comparable to the class I heavy chain.15,16 The extracellular portion of the α and β chains are divided into two domains, the membrane distal α1 and β1 domains and the membrane proximal α2 and β2 domains. Similar to the class I heavy chains, each domain is encoded by a separate exon (exons 2 and 3, respectively) and is about 90 amino acids in length. Three additional regions complete each chain of the class II molecule; a connecting peptide of 12 amino acids which is highly hydrophilic and links the membrane proximal domain to the transmembrane region, a 23 amino acid hydrophobic transmembrane region and an intracellular cytoplasmic tail that consists of the carboxy terminal 8–15 amino acids.
The 3D structures of the extracellular portion of several class II molecules have been determined by X-ray crystallography.48,49,58 These structures are strikingly similar to that of class I molecules. The α1 and β1 domains fold together to form a peptide binding groove like the groove formed by the class I heavy chain α1 and α2 domains (Fig. 39.6B). The α2 and β2 domains of the class II chains fold to form Ig constant region domain like structures similar to that of the class I α3 domain and β2m.
The peptides that bind to class II molecules are anchored to the class II antigen binding groove by non-covalent bonds to the peptide backbone and by binding of peptide amino acid side chains into pockets along the groove (Fig. 39.6D), similar to the class I molecules.49,58,59 Because of the polymorphic nature of the MHC class II proteins, each class II molecule, like each class I molecule, also binds a large set of peptides which share a peptide binding motif specific to that class II molecule (Table 39.5). The peptides that bind to class II molecules are heterogenous in length and generally 13–25 amino acids long. The low and open ends of the class II groove allow peptides of varying lengths to bind in an extended conformation with the ends of the peptide overhanging the ends of the groove. This is in contrast to the class I molecules which bind peptides of 8–10 amino acids. The ends of the class I groove are high and closed; thus, MHC class I molecules optimally accommodate shorter peptides whose ends are tucked into the groove (compare Fig. 39.6C and 39.6D).
Function
Peptide processing and binding
Mature cell surface class I molecules are formed in the endoplasmic reticulum (ER) with the aid of several resident ER proteins including tapasin, calnexin and calreticulin.60,61 Initially, the class I heavy chain and β2m fold and associate facilitated by calnexin and calreticulin (Fig. 39.7). This complex then transiently associates with the transporter associated with antigen processing (TAP) where a peptide is loaded into the groove of the class I heavy chain. Finally, the trimolecular complex is dispatched to the cell surface.
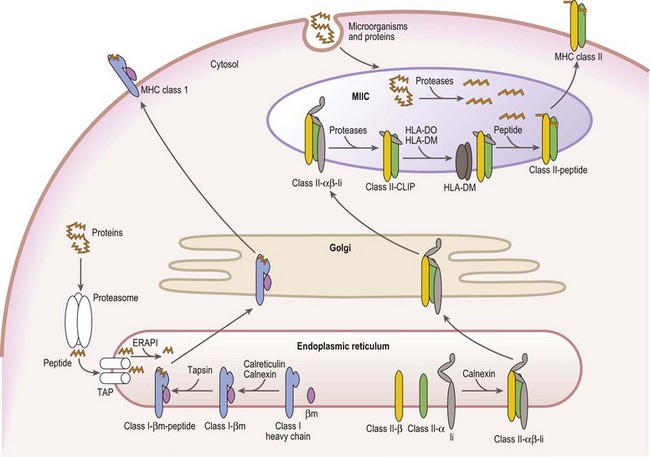
Peptides, derived from both self (normal cellular) proteins (potential autoantigens) or foreign proteins (antigens), are generated in the cytosol by the proteosome.60,61 The proteosome is a macromolecular structure that proteolytically cleaves proteins into peptides (a process termed antigen processing) and consists of members of the large multifunctional proteosome (LMP) family and other protein subunits. Two LMP family members (LMP2 and LMP7) are encoded in the class II region of the MHC. The proteosome is tightly associated with the TAP molecule which shuttles the peptides into the lumen of the ER.60,61 TAP is formed by the association of the products of the TAP1 and TAP2 genes also encoded in the MHC class II region. Another MHC encoded gene product, tapasin, stabilizes the TAP heterodimers, links the class I heavy chain to TAP for peptide loading and facilitates loading of peptides onto the class I molecule. An endoplasmic reticulum aminopeptidase plays a dual function in class I antigen presentation. It trims longer peptides that are more readily shuttled by TAP to the optimal length (8–9 amino acids) enhancing binding to class I molecules, but also destroys many peptides limiting the pool available for binding to class I.62,63
The class II α and β chains fold and associate in the ER with the assistance of resident ER chaperones such as calnexin (Fig. 39.7),64 similar to class I molecules. Unlike class I, full maturation of the class II molecule does not take place in the ER. Instead, class II heterodimers are directed primarily to specialized endosomal compartments (MHC class II compartments, MIIC), or, in some instance, first traffic to the cell surface and then to the MIIC.65 Once in the MIIC, peptides are loaded into the antigen binding groove and mature class II molecules are dispatched to the cell surface.
MHC class II molecules bind peptides derived from endocytosed microorganisms and from self and foreign proteins degraded by proteases in the endocytic pathway.66 This is in contrast, yet complementary, to the peptides bound by MHC class I molecules. In general, class II molecules bind peptides from cell surface and extracellular sources, while class I molecules bind peptides from intracellular sources. Thus, proteins from the whole environment of a cell can be surveyed by the immune system. Invariant chain (Ii), a nonMHC encoded glycoprotein, plays a key role in facilitating this division of function.
Ii performs several functions in assuring proper antigen presentation by class II molecules. Ii chain serves as a chaperone in the folding and assembly of class II αβ heterodimers and protects the class II peptide binding groove from binding peptide in the ER via a 25 residue internal peptide segment termed CLIP (class II associated invariant chain peptide).65,66 Ii also provides the intracellular targeting signals that direct the complex to the MIIC. Under the acidic conditions of the MIIC, Ii is proteolytically cleaved and dissociates from the class II molecule, while CLIP remains bound to the class II antigen binding groove. CLIP is exchanged for antigenic peptides in a reaction catalyzed by HLA-DM, a resident MIIC protein that tightly associates with the class II heterodimer.67–69 HLA-DM is a critical component in shaping the repertoire of peptides bound to class II molecules as it retains the class II molecules in the MIIC until a stable, high affinity complex between the class II molecule and a peptide is formed. In certain APC types, B-cells and thymic epithelial cells, another resident MIIC protein, HLA-DO, negatively regulates the actions of HLA-DM.67,68
Analogous to the MHC class II molecules, both HLA-DM and HLA-DO are class II related Ig superfamily members expressed as heterodimers that consist of an α chain and a β chain.67–69 The HLA-DM and HLA-DO α and β chains are encoded by A and B genes, respectively, in the MHC class II region and regulation of these genes is similar to that of the MHC class II genes.69 The 3D structure of HLA-DM resembles that of the MHC class II molecules except that its peptide binding groove is almost entirely obscured.48
Components of the peptide processing and binding pathways of MHC class I and class II molecules are a favorite target of disruption by many pathogens and malignant cells to avoid detection by the immune system.42–44 For example, two proteins (US3 and US6) encoded by human CMV block cell surface expression of MHC class I molecules and thus, detection of the infected cell by cytotoxic T-cells. US3 binds to MHC class I molecules and retains them in the ER and US6 inhibits peptide transport into the ER by TAP. Lack of cell surface MHC class I, however, renders the CMV infected cell susceptible to lysis by NK cells. To circumvent NK cell recognition, CMV encodes a class I like decoy termed UL18 which is recognized by NK cells and inhibits their function.45 Other pathogens and malignant cells employ a variety of unique strategies to block MHC expression.
T lymphocyte recognition of HLA molecules
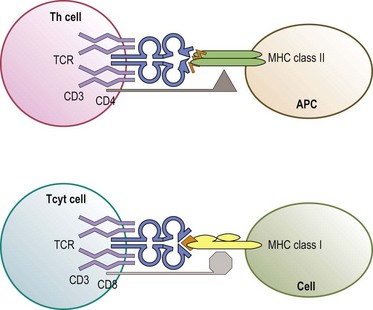
The predominant function of classical MHC class I and class II molecules is to bind peptides from the cell’s environment and present these peptides on the surface of the cell for inspection by the immune system. The archetypical receptor involved in the inspection process is the T-cell receptor (TCR) on T lymphocytes (Fig. 39.8). There are two types of TCR (αβ and γδ) both of which are multipolypeptide complexes that consist of a TCR α chain covalently paired with a TCR β chain or of a TCR γ chain covalently paired with a TCR δ chain tightly, but noncovalently, associated with several chains of the CD3 family (α, δ, ε, ζ, η).70,71 The TCR chains are involved in the direct recognition of the HLA molecule and of the peptide bound to the HLA molecule.71,72 CD3 is involved in the signaling process which activates the T-cell after recognition of the ligand by the TCR chains.70
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


