2 Epidemiologic Data Measurements

I Frequency
A Incidence (Incident Cases)
Incidence is the frequency of occurrences of disease, injury, or death—that is, the number of transitions from well to ill, from uninjured to injured, or from alive to dead—in the study population during the time period of the study. The term incidence is sometimes used incorrectly to mean incidence rate (defined in a later section). Therefore, to avoid confusion, it may be better to use the term incident cases, rather than incidence. Figure 2-1 shows the annual number of incident cases of acquired immunodeficiency syndrome (AIDS) by year of report for the United States from 1981 to 1992, using the definition of AIDS in use at that time.
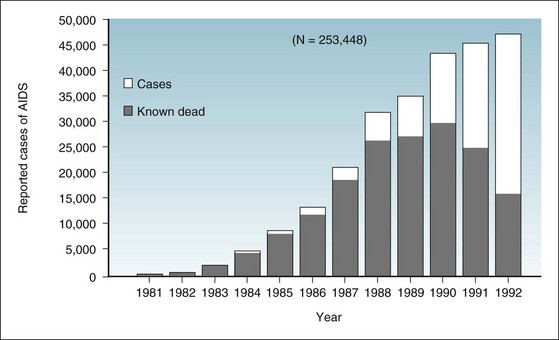
Figure 2-1 Incident cases of acquired immunodeficiency syndrome in United States, by year of report, 1981-1992.
The full height of a bar represents the number of incident cases of AIDS in a given year. The darkened portion of a bar represents the number of patients in whom AIDS was diagnosed in a given year, but who were known to be dead by the end of 1992. The clear portion represents the number of patients who had AIDS diagnosed in a given year and were still living at the end of 1992. Statistics include cases from Guam, Puerto Rico, the U.S. Pacific Islands, and the U.S. Virgin Islands.
(From Centers for Disease Control and Prevention: Summary of notifiable diseases—United States, 1992. MMWR 41:55, 1993.)
C Illustration of Morbidity Concepts
The concepts of incidence (incident cases), point prevalence (prevalent cases), and period prevalence are illustrated in Figure 2-2, based on a method devised in 1957.1 Figure 2-2 provides data concerning eight persons who have a given disease in a defined population in which there is no emigration or immigration. Each person is assigned a case number (case no. 1 through case no. 8). A line begins when a person becomes ill and ends when that person either recovers or dies. The symbol t1 signifies the beginning of the study period (e.g., a calendar year) and t2 signifies the end.
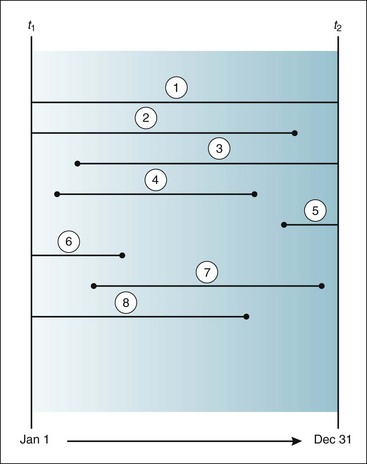
Figure 2-2 Illustration of several concepts in morbidity.
Lines indicate when eight persons became ill (start of a line) and when they recovered or died (end of a line) between the beginning of a year (t1) and the end of the same year (± t2). Each person is assigned a case number, which is circled in this figure. Point prevalence: t1 = 4 and t2 = 3; period prevalence = 8.
(Based on Dorn HF: A classification system for morbidity concepts. Public Health Rep 72:1043–1048, 1957.)
In case no. 1, the patient was already ill when the year began and was still alive and ill when it ended. In case nos. 2, 6, and 8, the patients were already ill when the year began, but recovered or died during the year. In case nos. 3 and 5, the patients became ill during the year and were still alive and ill when the year ended. In case nos. 4 and 7, the patients became ill during the year and either recovered or died during the year. On the basis of Figure 2-2, the following calculations can be made. There were four incident cases during the year (case nos. 3, 4, 5, and 7). The point prevalence at t1 was four (the prevalent cases were nos. 1, 2, 6, and 8). The point prevalence at t2 was three (case nos. 1, 3, and 5). The period prevalence is equal to the point prevalence at t1 plus the incidence between t1 and t2, or in this example, 4 + 4 = 8. Although a person can be an incident case only once, he or she could be considered a prevalent case at many points in time, including the beginning and end of the study period (as with case no. 1).
D Relationship between Incidence and Prevalence
Figure 2-1 provides data from the U.S. Centers for Disease Control and Prevention (CDC) to illustrate the complex relationship between incidence and prevalence. It uses the example of AIDS in the United States from 1981, when it was first recognized, through 1992, after which the definition of AIDS underwent a major change. Because AIDS is a clinical syndrome, the present discussion addresses the prevalence of AIDS, rather than the prevalence of its causal agent, human immunodeficiency virus (HIV) infection.
In Figure 2-1, the full height of each year’s bar shows the total number of new AIDS cases reported to the CDC for that year. The darkened part of each bar shows the number of people in whom AIDS was diagnosed in that year, and who were known to be dead by December 31, 1992. The clear space in each bar represents the number of people in whom AIDS was diagnosed in that year, and who presumably were still alive on December 31, 1992. The sum of the clear areas represents the prevalent cases of AIDS as of the last day of 1992. Of the people in whom AIDS was diagnosed between 1990 and 1992 and who had had the condition for a relatively short time, a fairly high proportion were still alive at the cutoff date. Their survival resulted from the recency of their infection and from improved treatment. However, almost all people in whom AIDS was diagnosed during the first 6 years of the epidemic had died by that date.
The total number of cases of an epidemic disease reported over time is its cumulative incidence. According to the CDC, the cumulative incidence of AIDS in the United States through December 31, 1991, was 206,392, and the number known to have died was 133,232.2 At the close of 1991, there were 73,160 prevalent cases of AIDS (206,392 − 133,232). If these people with AIDS died in subsequent years, they would be removed from the category of prevalent cases.
On January 1, 1993, the CDC made a major change in the criteria for defining AIDS. A backlog of patients whose disease manifestations met the new criteria was included in the counts for the first time in 1993, and this resulted in a sudden, huge spike in the number of reported AIDS cases (Fig. 2-3). Because of this change in criteria and reporting, the more recent AIDS data are not as satisfactory as the older data for illustrating the relationship between incidence and prevalence. Nevertheless, Figure 2-3 provides a vivid illustration of the importance of a consistent definition of a disease in making accurate comparisons of trends in rates over time.
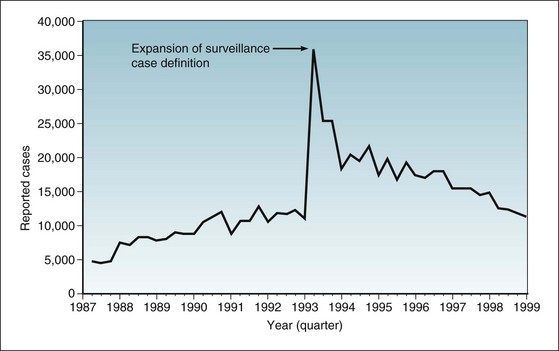
Figure 2-3 Incident cases of AIDS in United States, by quarter of report, 1987-1999.
Statistics include cases from Guam, Puerto Rico, the U.S. Pacific Islands, and the U.S. Virgin Islands. On January 1, 1993, the CDC changed the criteria for defining AIDS. The expansion of the surveillance case definition resulted in a huge spike in the number of reported cases.
(From Centers for Disease Control and Prevention: Summary of notifiable diseases—United States, 1998. MMWR 47:20, 1999.)
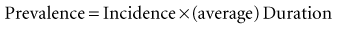
This conceptual formula works only if the incidence of the disease and its duration in individuals are stable for an extended time. The formula implies that the prevalence of a disease can increase as a result of an increase in the following:


II Risk
B Limitations of the Concept of Risk
Expressing the risk of death from an infectious disease, although seemingly simple, is quite complex. This is because such a risk is the product of many different proportions, as can be seen in Figure 2-4. Numerous subsets of the population must be considered. People who die of an infectious disease are a subset of people who are ill from the disease, who are a subset of the people who are infected by the disease agent, who are a subset of the people who are exposed to the infection, who are a subset of the people who are susceptible to the infection, who are a subset of the total population.
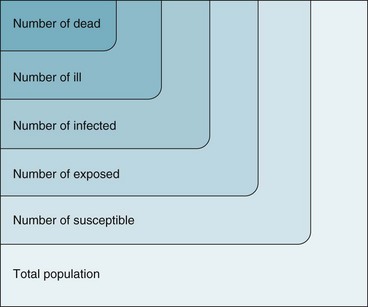
Figure 2-4 Graphic representation of why the death rate from an infectious disease is the product of many proportions.
The formula may be viewed as follows:
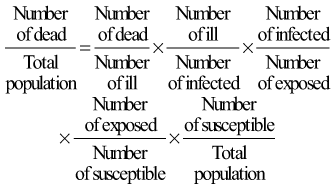
The proportion of clinically ill persons who die is the case fatality ratio; the higher this ratio, the more virulent the infection. The proportion of infected persons who are clinically ill is often called the pathogenicity of the organism. The proportion of exposed persons who become infected is sometimes called the infectiousness of the organism, but infectiousness is also influenced by the conditions of exposure. A full understanding of the epidemiology of an infectious disease would require knowledge of all the ratios shown in Figure 2-4. Analogous characterizations may be applied to noninfectious disease.
III Rates
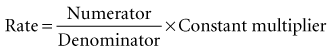
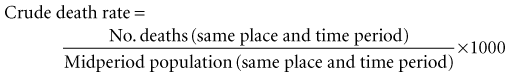
B Relationship between Risk and Rate
In an example presented in section II.B, populations A, B, and C were similar in size, and each had a 10% overall risk of death in the same year, but their patterns of death differed greatly. Figure 2-5 shows the three different patterns and illustrates how, in this example, the concept of rate is superior to the concept of risk in showing differences in the force of mortality.
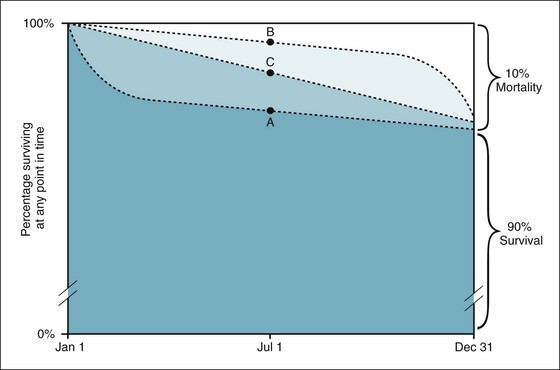
Figure 2-5 Circumstances under which the concept of rate is superior to the concept of risk.
Assume that populations A, B, and C are three different populations of the same size; that 10% of each population died in a given year; and that most of the deaths in population A occurred early in the year, most of the deaths in population B occurred late in the year, and the deaths in population C were evenly distributed throughout the year. In all three populations, the risk of death would be the same—10%—even though the patterns of death differed greatly. The rate of death, which is calculated using the midyear population as the denominator, would be the highest in population A, the lowest in population B, and intermediate in population C, reflecting the relative magnitude of the force of mortality in the three populations.
Rates are often used to estimate risk. A rate is a good approximation of risk if the:



Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


