9 Describing Variation in Data

 Describe the patterns of variation in single variables, as discussed in this chapter.
Describe the patterns of variation in single variables, as discussed in this chapter.
 Determine when observed differences are likely to be real differences, as discussed in Chapters 10 and 11.
Determine when observed differences are likely to be real differences, as discussed in Chapters 10 and 11.
 Determine the patterns and strength of association between variables, as discussed in Chapters 11 and 13.
Determine the patterns and strength of association between variables, as discussed in Chapters 11 and 13.
I Sources of Variation in Medicine
Some variation is caused by measurement error. Two different BP cuffs of the same size may give different measurements in the same patient because of defective performance by one of the cuffs. Different laboratory instruments or methods may produce different readings from the same sample. Different x-ray machines may produce films of varying quality. When two clinicians examine the same patient or the same specimen (e.g., x-ray film), they may report different results1 (see Chapter 7). One radiologist may read a mammogram as abnormal and recommend further tests, such as a biopsy, whereas another radiologist may read the same mammogram as normal and not recommend further workup.2 One clinician may detect a problem such as a retinal hemorrhage or a heart murmur, and another may fail to detect it. Two clinicians may detect a heart murmur in the same patient but disagree on its characteristics. If two clinicians are asked to characterize a dark skin lesion, one may call it a “nevus,” whereas the other may say it is “suspicious for malignant melanoma.” A pathologic specimen would be used to resolve the difference, but that, too, is subject to interpretation, and two pathologists might differ.
II Statistics and Variables
B Types of Variables
Variables can be classified as nominal variables, dichotomous (binary) variables, ordinal (ranked) variables, continuous (dimensional) variables, ratio variables, and risks and proportions (Table 9-1).
Table 9-1 Examples of the Different Types of Data
| Information Content | Variable Type | Examples |
|---|---|---|
| Higher | Ratio | Temperature (Kelvin); blood pressure* |
| Continuous (dimensional) | Temperature (Fahrenheit)* | |
| Ordinal (ranked) | Edema = 3+ out of 5 Perceived quality of care = good/fair/poor | |
| Binary (dichotomous) | Gender; heart murmur = present/absent | |
| Nominal | Blood type; color = cyanotic or jaundiced; taste = bitter or sweet | |
| Lower |
Note: Variables with higher information content may be collapsed into variables with less information content. For example, hypertension could be described as “165/95 mm Hg” (continuous data), “absent/mild/moderate/severe” (ordinal data), or “present/absent” (binary data). One cannot move in the other direction, however. Also, knowing the type of variables being analyzed is crucial for deciding which statistical test to use (see Table 11-1).
*For most types of data analysis, the distinction between continuous data and ratio data is unimportant. Risks and proportions sometimes are analyzed using the statistical methods for continuous variables, and sometimes observed counts are analyzed in tables, using nonparametric methods (see Chapter 11).
2 Dichotomous (Binary) Variables
Dichotomous variables, although common and important, often are inadequate by themselves to describe something fully. When analyzing cancer therapy, it is important to know not only whether the patient survives or dies (a dichotomous variable), but also how long the patient survives (time forms a continuous variable). A survival analysis or life table analysis, as described in Chapter 11, may be done. It is important to know the quality of patients’ lives while they are receiving the therapy; this might be measured with an ordinal variable, discussed next. Similarly, for a study of heart murmurs, various types of data may be needed, such as dichotomous data concerning a murmur’s timing (e.g., systolic or diastolic), nominal data on its location (e.g., aortic valve area) and character (e.g., rough), and ordinal data on its loudness (e.g., grade III). Dichotomous variables and nominal variables sometimes are called discrete variables because the different categories are completely separate from each other.
3 Ordinal (Ranked) Variables
Ordinal variables are not measured on an exact measurement scale, but more information is contained in them than in nominal variables. It is possible to see the relationship between two ordinal categories and know whether one category is more desirable than another. Because they contain more information than nominal variables, ordinal variables enable more informative conclusions to be drawn. As described in Chapter 11, ordinal variables often require special techniques of analysis.
4 Continuous (Dimensional) Variables
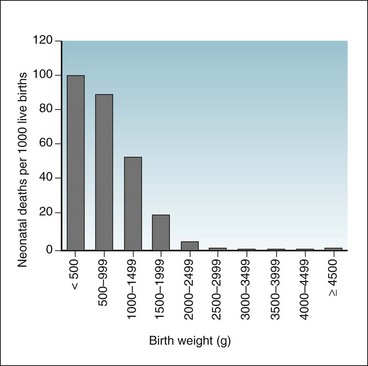
Relationships between continuous variables are not always linear (in a straight line). The relationship between the birth weight and the probability of survival of newborns is not linear.3 As shown in Figure 9-1, infants weighing less than 3000 g and infants weighing more than 4500 g are historically at greater risk for neonatal death than are infants weighing 3000 to 4500 g (~6.6-9.9 lb).
6 Risks and Proportions as Variables
As discussed in Chapter 2, a risk is the conditional probability of an event (e.g., death or disease) in a defined population in a defined period. Risks and proportions, which are two important types of measurement in medicine, share some characteristics of a discrete variable and some characteristics of a continuous variable. It makes no conceptual sense to say that a “fraction” of a death occurred or that a “fraction” of a person experienced an event. It does make sense, however, to say that a discrete event (e.g., death) or a discrete characteristic (e.g., presence of a murmur) occurred in a fraction of a population. Risks and proportions are variables created by the ratio of counts in the numerator to counts in the denominator. Risks and proportions sometimes are analyzed using the statistical methods for continuous variables (see Chapter 10), and sometimes observed counts are analyzed in tables, using statistical methods for analyzing discrete data (see Chapter 11).
C Counts and Units of Observation
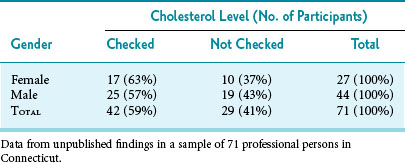
The unit of observation is the person or thing from which the data originated. Common examples of units of observation in medical research are persons, animals, and cells. Units of observation may be arranged in a frequency table, with one characteristic on the x-axis, another characteristic on the y-axis, and the appropriate counts in the cells of the table. Table 9-2, which provides an example of this type of 2 × 2 table, shows that among 71 young professional persons studied, 63% of women and 57% of men previously had their cholesterol levels checked. Using these data and the chi-square test described in Chapter 11, one can determine whether or not the difference in the percentage of women and men with cholesterol checks was likely a result of chance variation (in this case the answer is “yes”).
D Combining Data
A continuous variable may be converted to an ordinal variable by grouping units with similar values together. For example, the individual birth weights of infants (a continuous variable) can be converted to ranges of birth weights (an ordinal variable), as shown in Figure 9-1. When the data are presented as categories or ranges (e.g., <500, 500-999, 1000-1499 g), information is lost because the individual weights of infants are no longer apparent. An infant weighing 501 g is in the same category as an infant weighing 999 g, but the infant weighing 999 g is in a different category from an infant weighing 1000 g, just 1 g more. The advantage is that now percentages can be created, and the relationship of birth weight to mortality is easier to show.
III Frequency Distributions
A Frequency Distributions of Continuous Variables
Observations on one variable may be shown visually by putting the variable’s values on one axis (usually the horizontal axis or x-axis) and putting the frequency with which that value appears on the other axis (usually the vertical axis or y-axis). This is known as a frequency distribution. Table 9-3 and Figure 9-2 show the distribution of the levels of total cholesterol among 71 professional persons. The figure is shown in addition to the table because the data are easier to interpret from the figure.
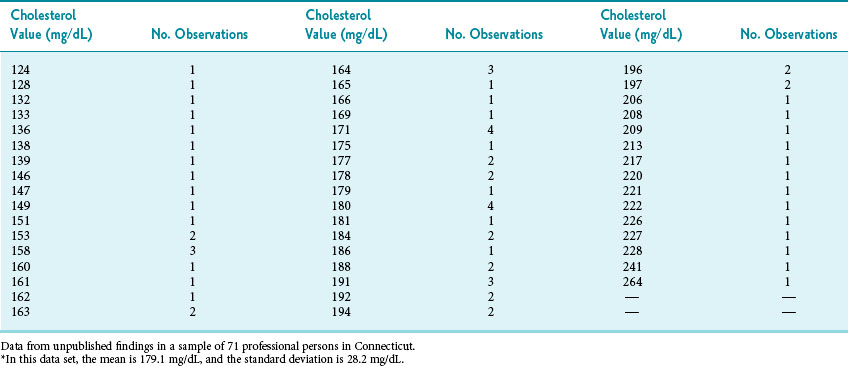
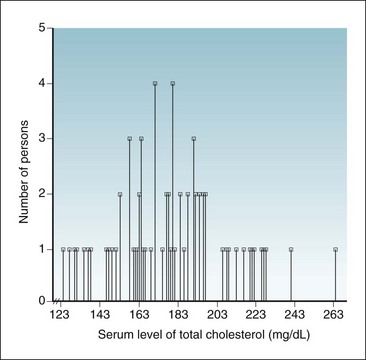
Figure 9-2 Histogram showing frequency distribution of serum levels of total cholesterol.
As reported in a sample of 71 participants; data shown here are same data listed in Table 9-3; see also Figures 9-4 and 9-5.
(Data from unpublished findings in a sample of 71 professional persons in Connecticut.)
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


