Cell Growth and Reproduction
LANGUAGE OF SCIENCE
 Before reading the chapter, say each of these terms out loud. This will help you avoid stumbling over them as you read.
Before reading the chapter, say each of these terms out loud. This will help you avoid stumbling over them as you read.
(app-o-TOH-sis or app-op-TOH-sis)
(kom-pleh-MEN-tah-ree PAIR-ing)
[comple- complete, -ment- process, -ary relating to]
[cyto- cell, -kinesis movement]
(dee-ok-see-rye-boh-nooklay-ik ASS-id)
[de- removed, –oxy- oxygen, -nucle- nucleus (kernel), -ic relating to, acid sour]
[different- difference, -iate act of]
[inter- between, -phase stage]
[mitos- thread, -osis condition]
(oh-BLIG-ah-tor-ee base PAIR-ing)
[prote- protein, -ome body (whole set)]
[splice- cut rope and join remaining ends, -som-body]
[trans- across, -script- write, -tion process]
LANGUAGE OF MEDICINE
[a- without, –trophy nourishment]
[dys- disordered, -plasia substance]
[hyper- excessive, -plasia shape]
[hyper- excessive, -troph-nourishment, -y state]
[malign bad, -ant state, tumor swelling]
[necro- death, -osis condition]
[neo- new, -plasm tissue or substance]
[sickle crescent, cell storeroom, an without, -emia blood condition]
PROTEIN SYNTHESIS
As stated in the previous chapter, the most important anabolic pathway for the student beginning the study of anatomy and physiology to understand is the process of protein synthesis. Protein synthesis is important for several reasons. First of all, protein synthesis is required for cell growth and maintenance. Protein synthesis begins with reading of the genetic “master code” in the cell’s DNA. The genetic code dictates the structure of each protein produced during the growth process of each cell. A basic understanding of how the genetic code is used by the cell is essential for understanding modern concepts of human biology, including the study of disease processes.
Protein synthesis is also an important process because it influences all cell structures and functions. Proteins synthesized by the cell either are structural elements themselves or are enzymes or other functional proteins that direct the synthesis of other structural and functional molecules such as carbohydrates, lipids, and nucleic acids. In short, protein synthesis is the central building process for cell growth and maintenance.
Deoxyribonucleic Acid (DNA)
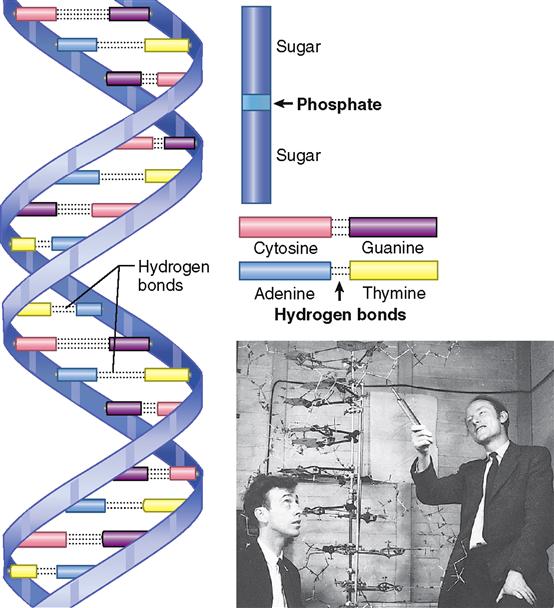
In 1953, American scientist James Watson, and three British scientists, Francis Crick, Maurice Wilkins, and Rosalind Franklin, won the race to solve the puzzle of DNA’s molecular structure (Figure 5-1). Nine years later, Watson, Crick, and Wilkins received the Nobel Prize for their brilliant and significant work—hailed as the greatest biological discovery of our time. (Franklin died before the Nobel Prize was awarded.)
Since the original discovery of DNA’s structure, we have seen a new branch of biology called molecular genetics emerge from our rapidly growing knowledge of DNA and how it works. Indeed, we have seen a revolution in human biology as we witness the continuing application of molecular genetics transform every single aspect of anatomy, physiology, and medicine. We begin our outline of protein synthesis with a discussion of DNA because it truly is, as Watson called it, “the most golden of all molecules.”
The deoxyribonucleic acid molecule is a giant among molecules. Its size and the complexity of its shape exceed those of most molecules. The importance of its function—in a word, information—surpasses that of any other molecule in the world. To visualize the shape of the DNA molecule, picture an extremely long, narrow ladder made of a pliable material (see Figure 5-1). Now see it twisting round and round on its axis and taking on the shape of a steep spiral staircase millions of turns long. This is the shape of the DNA molecule—a double spiral or double helix.
The DNA molecule is a polymer, which means that it is a large molecule made up of many smaller molecules joined together in sequence. DNA is a polymer of millions of pairs of nucleotides. A nucleotide is a compound formed by combining phosphoric acid with a sugar and a nitrogenous base. The DNA molecule has four different kinds of nucleotides. Each consists of a phosphate group that attaches to the sugar deoxyribose, which attaches to one of four bases. Nucleotides differ, therefore, in their nitrogenous base component—containing either adenine or guanine (purine bases) or cytosine or thymine (pyrimidine bases). (Deoxyribose is a sugar that is not sweet and one whose molecules contain only five carbon atoms.) Notice what the name deoxyribonucleic acid tells you—that this compound contains deoxyribose, that it occurs in the nucleus, and that it is an acid.
Figure 5-1 reveals additional and highly significant facts about DNA’s molecular structure. First, observe which compounds form the sides of the DNA spiral staircase—a long line of phosphate and deoxyribose units joined alternately one after the other. Look next at the stair steps. Notice two facts about them: two bases join (loosely bound by hydrogen bonds) to form each step, and only two combinations of bases occur. The same two bases invariably pair off with each other in a DNA molecule. Adenine always goes with thymine (or vice versa, thymine with adenine), and guanine always goes with cytosine (or vice versa). This aspect of DNA molecular structure is called obligatory base pairing. Pay particular attention to it, for it is the key to understanding how a DNA molecule is able to duplicate itself. DNA duplication, or replication as it is usually called, is one of the most important of all biological phenomena because it is an essential and crucial part of the mechanism of genetics.
Another aspect of DNA’s molecular structure that has great functional importance is the sequence of its base pairs. Although the kinds of base pairs possible in all DNA molecules are the same, the sequence of these base pairs is not the same in all DNA molecules. For instance, the sequence of the base pairs composing the seventh, eighth, and ninth steps of one DNA molecule might be cytosine-guanine, adenine-thymine, and thymine-adenine. Such a sequence of three bases forms a code word or “triplet” called a codon. In another DNA molecule the coding sequence of the base pairs making up these same steps might be entirely different, perhaps thymine-adenine, guanine-cytosine, and cytosine-guanine. Perhaps these seem to be minor details, but nothing could be further from the truth, because it is the sequence of the base pairs in the nucleotides that make up the DNA molecules that identifies each gene. Therefore, it is the sequence of base pairs that determines all hereditary traits.
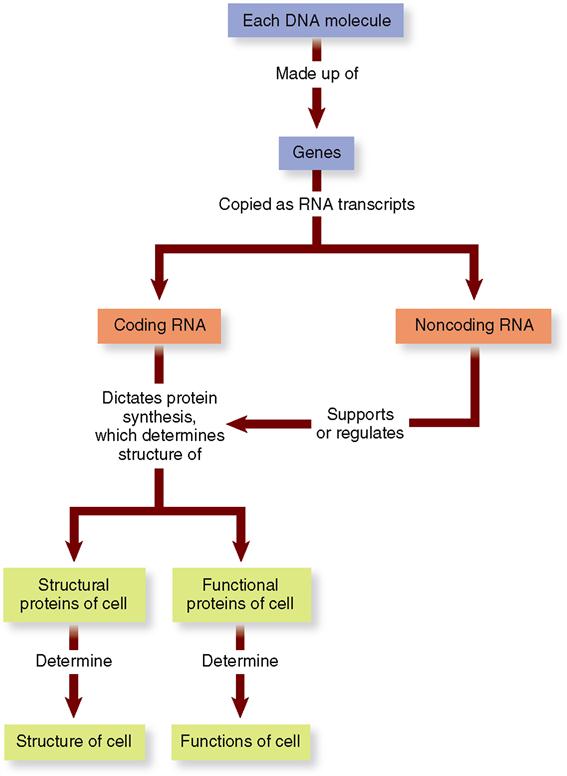
A human gene is a segment of a DNA molecule. One gene consists of a chain of approximately 1000 pairs of nucleotides joined one after the other in a precise sequence. Each gene in DNA is a code. As Figure 5-2 shows, a gene is the code for building a short strand of RNA (ribonucleic acid).
Ribonucleic Acid (RNA)
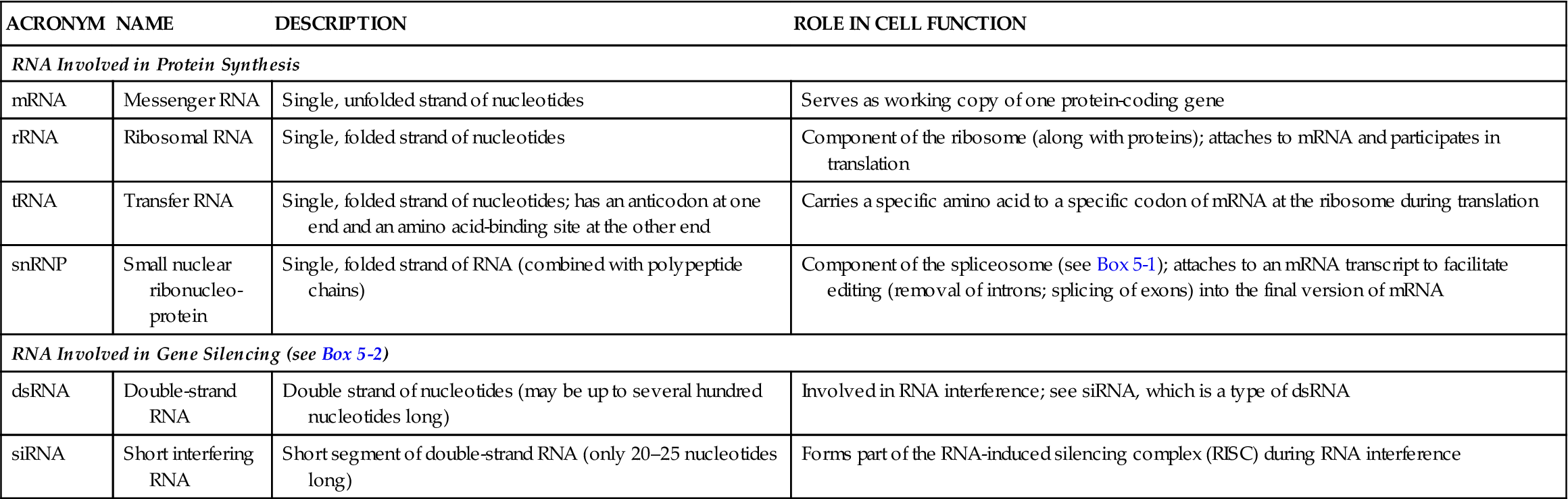
To make a protein, the gene code in DNA is first copied to a messenger ribonucleic acid (mRNA) molecule, or transcript. Each mRNA transcript of a gene may then be translated by the cell and used to build one polypeptide chain. Because it is a copy of a gene’s code, we call mRNA coding RNA. A few RNA transcripts are instead used to support or regulate polypeptide production. We call such RNA molecules noncoding RNAs. Examples of noncoding RNAs are rRNA (ribosomal RNA) and tRNA (transfer RNA). Table 5-1 summarizes the major types of RNA.
TABLE 5-1
| ACRONYM | NAME | DESCRIPTION | ROLE IN CELL FUNCTION |
| RNA Involved in Protein Synthesis | |||
| mRNA | Messenger RNA | Single, unfolded strand of nucleotides | Serves as working copy of one protein-coding gene |
| rRNA | Ribosomal RNA | Single, folded strand of nucleotides | Component of the ribosome (along with proteins); attaches to mRNA and participates in translation |
| tRNA | Transfer RNA | Single, folded strand of nucleotides; has an anticodon at one end and an amino acid-binding site at the other end | Carries a specific amino acid to a specific codon of mRNA at the ribosome during translation |
| snRNP | Small nuclear ribonucleo-protein | Single, folded strand of RNA (combined with polypeptide chains) | Component of the spliceosome (see Box 5-1); attaches to an mRNA transcript to facilitate editing (removal of introns; splicing of exons) into the final version of mRNA |
| RNA Involved in Gene Silencing (see Box 5-2) | |||
| dsRNA | Double-strand RNA | Double strand of nucleotides (may be up to several hundred nucleotides long) | Involved in RNA interference; see siRNA, which is a type of dsRNA |
| siRNA | Short interfering RNA | Short segment of double-strand RNA (only 20–25 nucleotides long) | Forms part of the RNA-induced silencing complex (RISC) during RNA interference |
One or more polypeptides made using RNA are used by the cell to make up each of a cell’s structural proteins and the many functional proteins that regulate cellular processes. Therefore, as Figure 5-2 shows, the nearly 24,000 protein-coding genes that make up a cell’s genome (DNA set) determine the cell’s structure and its functions.
Transcription
Protein synthesis begins when a single strand of RNA (ribonucleic acid) forms along a segment of one strand of a DNA molecule. Figure 5-3 summarizes how this process happens. Recall from Chapter 2 that RNA differs from DNA in certain respects (see Table 2-6, p. 37). Its molecules are smaller than those of DNA, and RNA contains ribose instead of deoxyribose. In addition, one of the four bases in RNA is uracil instead of thymine. As a strand of RNA is forming along a strand of DNA, uracil attaches to adenine, and guanine attaches to cytosine. The process is known as complementary pairing. Thus a single-strand molecule of messenger RNA (mRNA) is formed.
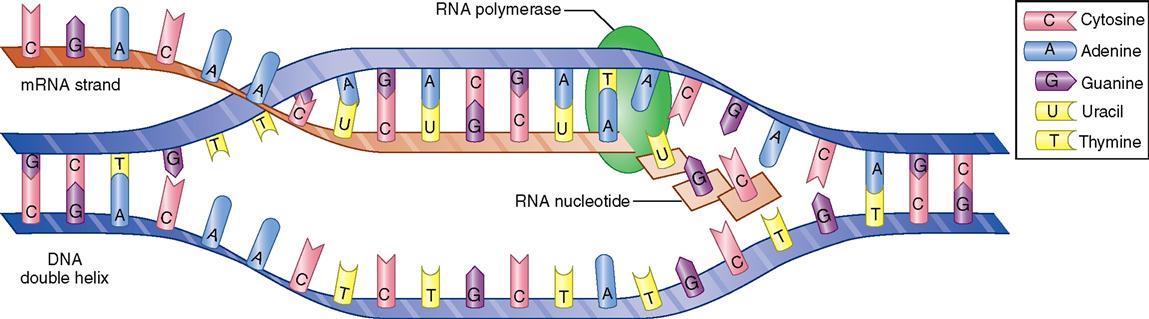
The name “messenger RNA” describes its function. As soon as it is formed, it separates from the DNA strand, is edited, moves out of the nucleus, and carries a “message” to a ribosome in the cell’s cytoplasm to direct the synthesis of a specific polypeptide. Synthesis of any RNA molecule is often called transcription because it actually copies or “transcribes” a portion of the DNA code—just like you “transcribe” your class notes when you make a copy of them.
Editing The Transcript
After the preliminary version of the mRNA molecule is formed, its message is “edited” into a final version before it reaches a ribosome (Figure 5-4). Just as you may edit your class notes by rearranging them for clarity after you transcribe them, the editing process allows the cell to arrange the code so that it will work in making a specific, needed polypeptide.
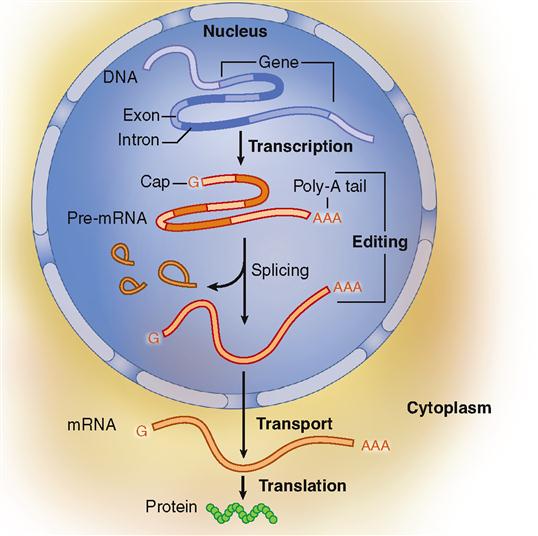
To begin editing, a modified guanine (G) nucleotide caps one end of the mRNA strand. At about the same time, a string of 50 to 200 adenine (A) nucleotides attaches to the opposite end of the mRNA strand. This string of A nucleotides is sometimes called the poly A tail. The cap and poly A tail both assist in the next step of mRNA editing. The cap and poly A tail also eventually help transport the mRNA strand out of the nucleus and assist in starting and stopping the translation process described in the next section.
Some segments of the RNA transcript represent noncoding parts of DNA called introns. These intron segments are removed by a complicated process involving small nuclear structures called spliceosomes (Box 5-1). This leaves behind segments that are copies of the DNA’s exons. Many of these exons encode the functional domains within protein molecules. Only these exon copies will be used in the final recipe for the protein. All the RNA segments representing exons are then spliced (joined) together by enzymes to form the final edited form of mRNA. It is this edited version of RNA that leaves the nucleus and participates in the next step of protein synthesis.
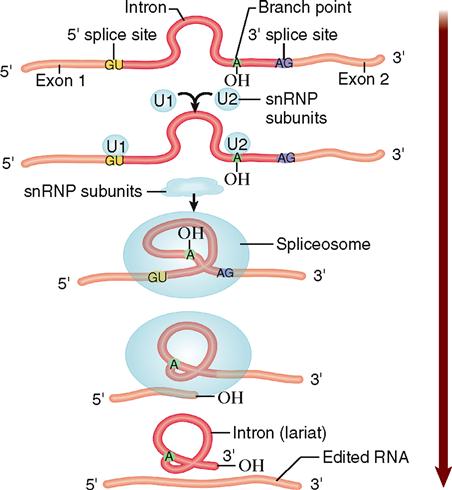
Box 5-1
The noncoding intron segments of the mRNA initially transcribed from a DNA gene are removed by a complicated process involving small structures called spliceosomes. Found inside the nucleus, spliceosomes are about the size of a ribosome. Spliceosomes are made up of subunits consisting of small nuclear ribonucleoprotein particles (snRNPs, pronounced “snurps”).
During mRNA editing, a snRNP subunit will attach at the beginning of an intron and another snRNP will attach at a spot in the intron called the “branch point.” Eventually, several different subunits will all assemble on the intron in this manner to form a complete spliceosome. As the Figure shows, the assembled spliceosome then breaks the strand as it bends the intron into a loop called a lariat. The intron lariat breaks completely away from the strand, and the spliceosome splices the ends of the remaining coding exon segments together. Only the spliced exons remain in the final, edited version of mRNA, which is later translated into the polypeptide encoded by the gene.
The intron may later break down into individual nucleotides, which are then recycled by the cell and used again for transcription. The intron may instead be processed to form a noncoding RNA strand with regulatory functions (see Box 5-2). After splicing is accomplished, the snRNP subunits of the spliceosome are free to reassemble on another intron and repeat the process.
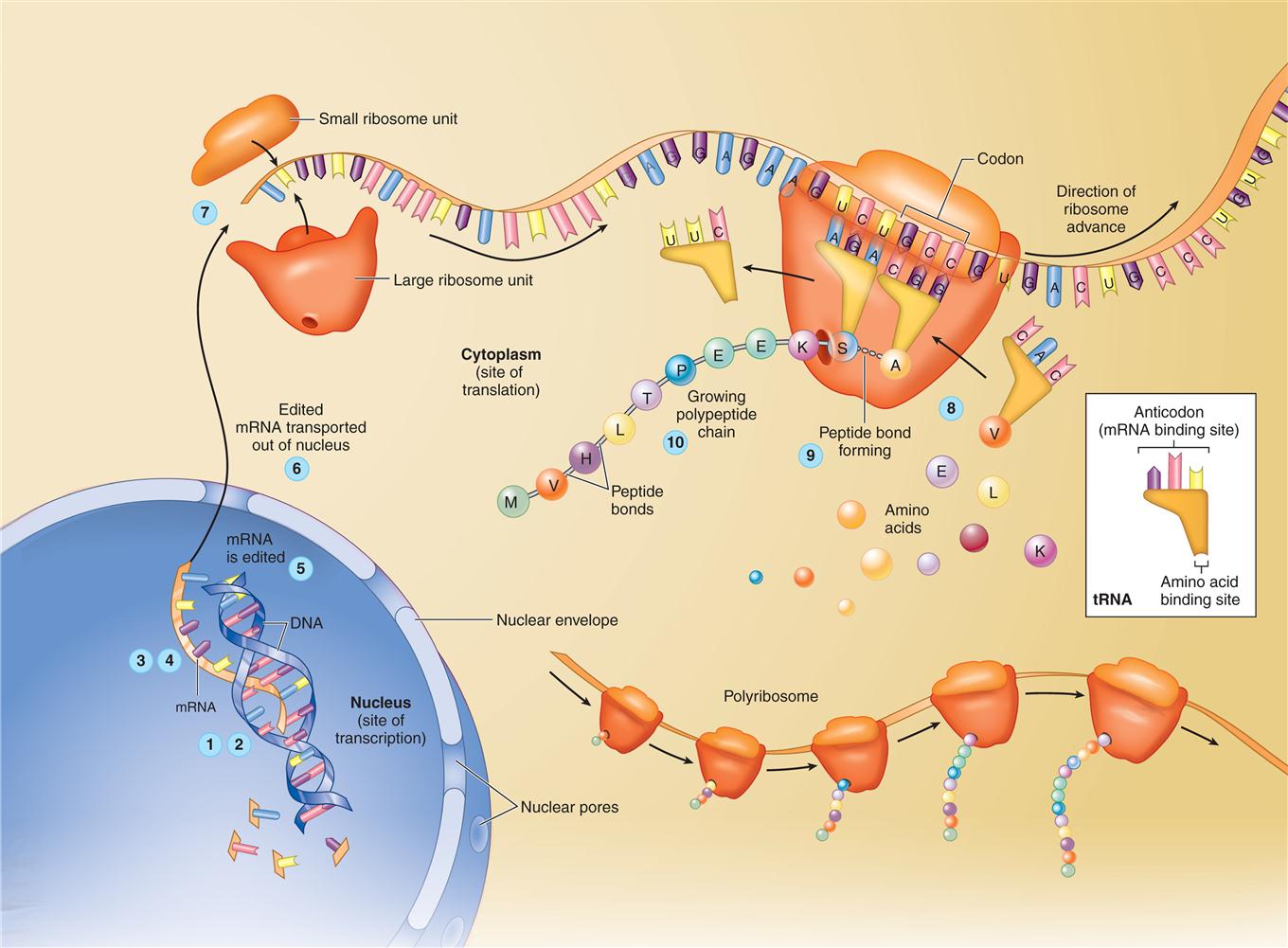
Translation
In the cytoplasm, the edited mRNA molecule attracts first a small ribosome subunit and then a large subunit (see Figure 3-6). As the subunits come together, they form an “mRNA sandwich” with the mRNA molecule in the middle. Recall that the two subunits of the now-complete ribosome are composed largely of ribosomal RNA (rRNA). The cell is now ready to interpret or “translate” the genetic code and form a specific sequence of amino acids in a process called translation.
In translation, yet another type of RNA—transfer RNA (tRNA)—becomes involved in protein synthesis (Figure 5-5). As the name implies, tRNA molecules carry or “transfer” amino acids to the ribosome for placement in the prescribed sequence. This function is determined by a unique molecular structure: a binding site for a specific amino acid at one end and a binding site for a specific mRNA codon (base triplet) at the other end (see Figure 2-32 on p. 58). Because tRNA’s binding site for mRNA contains the three bases that exactly complement one mRNA codon, this binding site is often called the anticodon.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


