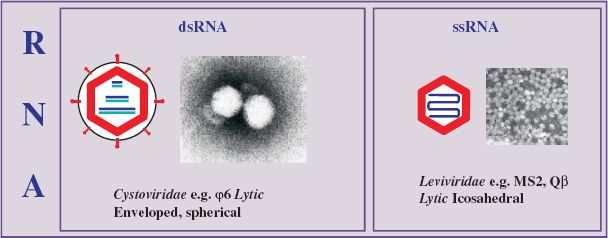
20.1 INTRODUCTION TO BACTERIAL VIRUSES (BACTERIOPHAGES)
Bacterial viruses, known as bacteriophages or phages (from the Greek phagein, “to eat”), were discovered independently by Frederick Twort (1915) and Felix d’Herelle (1917). A diversity of phages has subsequently been identified and grouped into a number of families. Phage diversity is reflected in both morphological and genetic characteristics. The genome may be DNA or RNA, single- or double-stranded, circular or linear, and is generally present as a single copy. Morphology varies from simple, icosahedral and filamentous phages to more complex tailed phages with an icosahedral head. The majority of phages are tailed.
Phages are common in most environments where bacteria are found and are important in regulating their abundance and distribution. The host controlled modification and restriction systems of bacteria are presumed to protect against phage infection: restriction is leveled against invading double-stranded phage DNA, whilst self-DNA is protected by the modification system. However, in response, certain phages have evolved anti-restriction mechanisms to avoid degradation of their DNA by restriction systems.
Broadly, phages can be classified as either virulent or temperate. A virulent phage subverts the cellular apparatus of its bacterial host for multiplication, typically culminating in cell lysis (for obligately lytic phages) and release of progeny virions. In rare cases, for example the filamentous ssDNA phage M13, progeny are continuously extruded from the host without cell lysis. Accordingly, M13 has been referred to as a “chronically infecting” phage. Temperate phages have alternative replication cycles: a productive, lytic infection or a reductive infection, in which the phage remains latent in the host, establishing lysogeny. The latter generally occurs when environmental conditions are poor, allowing survival as a prophage in the host (which is referred to as a lysogen). During lysogeny the phage genome is repressed for lytic functions and often integrates into the bacterial chromosome, as is the case for phage lambda (λ), but it can exist extrachromosomally: for example, phage P1. The prophage replicates along with the host and remains dormant until induction of the lytic cycle. This occurs under conditions that result in damage to the host DNA. The phage repressor is inactivated and the lytic process ensues. Such a mechanism allows propagation of phages when host survival is compromised. A resident prophage can protect the host from superinfection by the same or similar strains of phages by repressing the incoming phage genome (a phenomenon known as superinfection immunity).
Some temperate phages contribute “lysogenic conversion genes” (for example, diphtheria or cholera toxin genes) when they establish lysogeny, thereby converting the host to virulence. Phages can also mediate bacterial genome rearrangements and transfer non-viral genes horizontally by transduction. Tailed phages are the most efficient particles for horizontal (lateral) gene transfer, with the tail effectively guiding injection of DNA into the bacterial cell. Such phage activities generate variability and are a driving force for bacterial evolution.
Bacteriophages have had key roles in developments in molecular biology and biotechnology. They have been used as model systems for animal and plant viruses, and have provided tools for understanding aspects of DNA replication and recombination, transcription, translation, gene regulation, and so on. The first genomes to be sequenced were those of phages. Restriction enzymes were discovered following studies on phage infection of different hosts and laid the basis for the development of gene cloning. Phage-encoded enzymes and other products are exploited in molecular biology. Certain phages have been adapted for use as cloning and sequencing vectors and for phage display. Phages are utilized in the typing of bacteria, in diagnostic systems, as biological tracers, as pollution indicators, and in food and hospital sanitation (see also Section 1.2.2). There is also renewed interest in the therapeutic potential of phages, due largely to the rapid emergence of antibiotic-resistant bacteria and of new infectious diseases. However, realization of this potential will depend on a number of factors, including improved methods of large-scale production and purification of phages, appropriate protocols for administering phages, and modifications to enhance therapeutic properties, in order to remove phage-encoded toxins, avoid clearance of phages by the host defense system, and so on.
This chapter considers the biology of RNA and DNA phages. Properties and applications of a selection of phages that employ different strategies for phage development will be discussed, with emphasis on tailless single-stranded RNA and DNA phages.
RNA PHAGES
20.2 SINGLE-STRANDED RNA PHAGES
Single-stranded RNA phages are small, icosahedral viruses of the family Leviviridae (from the Latin levis, “light”), discovered by Timothy Loeb and Norton Zinder in 1961. Phages in this family have high mutation rates and some of the smallest RNA genomes known. They are plus-strand viruses (with the genome acting as mRNA), containing only a few genes, and infect various Gram-negative bacteria, including E. coli, Pseudomonas spp., and Caulobacter spp. Those infecting the enterobacteria do so by way of the sex pilus. Representative ssRNA phages of the genus Levivirus serogroup I (e.g. MS2 and f2) and Allolevivirus serogroup III (e.g. Qbeta, Qβ) are considered here.
20.2.1 Virion structure of ssRNA phages
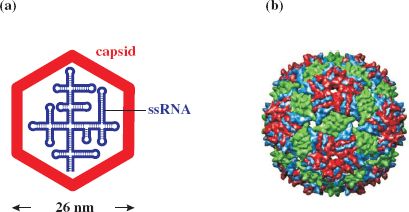
RNA phages typically comprise 180 molecules of major coat (capsid) protein (CP) per virion, one molecule of maturation (A) protein, required for infectivity and maturation, and a linear ssRNA genome of about 3500–4200 nucleotides that displays considerable (up to 80%) secondary structure (Figure 20.1).
Figure 20.1 Structure of ssRNA phage MS2. (a) Virion components. (b) Reconstruction of capsid showing subunit organization. The icosahedral capsid comprises about 180 copies of major coat protein (as dimers). There is also one copy of maturation protein (minor virion protein), for host infection by recognition of the sex pilus, and the ssRNA genome.
Source: (b) Image rendered by Chimera, from Virus Particle Explorer (VIPER) database (Shepherd C. M. et al. (2006) VIPERdb: a relational database for structural virology, Nucleic Acids Research, 34 (database issue), D386–D389).
20.2.2 Genome of ssRNA phages
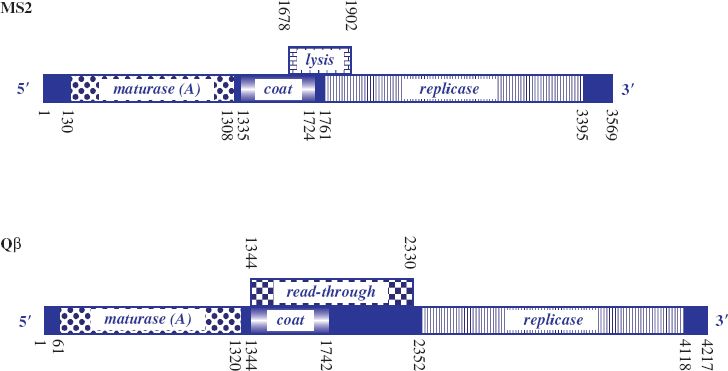
MS2 was the first virus identified that carried its genome as RNA and the genetic map is shown in Figure 20.2. The genome is 3569 nucleotides, with four open reading frames (ORFs) for major coat protein, maturation (A) protein, replicase (subunit II) and lysis protein, and is characterized by intergenic spaces. It was the first phage RNA genome to be completely sequenced.
Figure 20.2 Genetic maps of ssRNA phages MS2 and Qβ. Nucleotide coordinates are shown along the maps. The solid blue boxes are intergenic regions involved with ribosome binding and regulation of translation. MS2: genes for maturase (maturation protein); coat (capsid) protein; replicase protein for RNA-dependent RNA replication; and lysis protein (from overlapping coat and replicase genes). The Min Jou interaction involves nucleotides 1427–1433 and 1738–1744. Qβ: genes for maturase; coat protein; replicase protein; and read-through protein. The Qβ genome is larger than that of MS2, but there is no separate lysis gene. The maturation protein additionally mediates lysis.
Lysis protein is encoded by an overlapping ORF between the distal part of the coat protein gene, which appears to be required to regulate expression of the lysis gene, and the proximal part of the replicase gene, which encodes the essential residues for functioning of the lysis protein. Occasionally, ribosomes traversing the coat protein gene fail to maintain the correct reading frame so that once translation of coat protein terminates they can reinitiate at the start of the lysis protein ORF by shuffling a short distance. Efficiency of translation of the lysis protein ORF by such reinitiation is low. Thus only small amounts of lysis protein are synthesized, in turn guaranteeing that sufficient copies of coat protein will be available for assembly of virus particles before cell lysis occurs.
The genome of Qβ, which is about 4000 nucleotides, is larger than that of MS2. It encodes four proteins: coat protein, replicase, maturation (A2) protein, which also mediates cell lysis, and a minor coat protein (read-through protein, A1), which is generated as a result of reading through the coat protein gene into the intergenic region (Figure 20.2). Read-through is due to a leaky coat protein terminator (UGA). This allows a low level of misincorporation of tryptophan at the terminator signal and subsequent ribosome read-through. The read-through protein constitutes 3–7% of the virion protein and has a role in host infection. Such inefficient termination of translation is not found in the group I phages, where there are tandem stop codons (UAA, UAG) at the end of the coat protein gene and no read-through protein is produced.
Not only does the ssRNA genome encode the phage proteins, it also determines specific secondary and tertiary structure that regulates translation, replication, and other functions.
20.2.3 Replication cycle of ssRNA phages
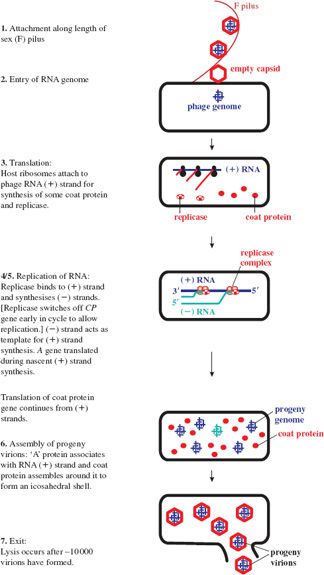
For coliphage MS2, infection involves attachment to pilin (the pilus subunit) along the length of a sex (F) pilus of a susceptible host via the A protein. Such binding of phages can block conjugation in E. coli.
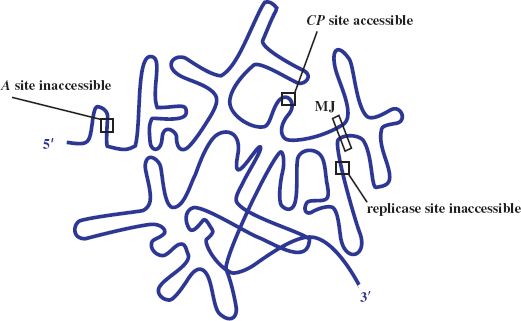
The plus-strand RNA genome directs protein synthesis immediately upon infection. It adopts a complex secondary structure that affects access of the ribosome binding sites (RBSs) to host ribosomes during translation. Control of gene expression involves transactions between the RNA secondary structure and the initiation of translation. Initially the RBS for the coat protein gene is accessible, occupying the loop position of a hairpin structure, whilst those for the maturation (A) and the replicase gene are not, being embedded in secondary structure (see Figure 20.3). The replicase gene is expressed only after the coat protein gene has been translated. Such translational coupling between coat protein and replicase genes involves the so-called Min Jou (MJ) interaction. This is a long-distance interaction (LDI), in which a sequence just upstream of the replicase gene RBS is base-paired to an internal sequence of the coat protein gene. The MJ interaction represses translation of the replicase gene. However, passage of ribosomes beyond the first half of the coat protein gene temporarily unfolds this LDI by breaking the MJ interaction. This opens up the RBS for translation of the replicase gene. The rate of refolding of the LDI in part determines the level of expression of replicase. Another LDI, called the van Duin (VD) interaction, which borders the MJ, also appears to contribute to the repression of replicase translation.
Figure 20.3 Gene expression in ssRNA phage. Diagrammatic representation of secondary structure of the genome with ribosome binding site of coat protein (CP) gene accessible and those of A and replicase genes blocked. MJ: Min Jou, long distance interaction between sequences upstream of the replicase ribosome binding site and sequences near the beginning of the CP gene.
After about 10 to 20 minutes, translation of the replicase gene stops, due to repression by coat protein, which binds to a RNA stem-loop containing the translation initiation region of replicase. This ensures that only a catalytic amount of replicase is translated. Too much replicase could poison the host. Such binding also appears to serve as an assembly initiation signal. The latter half of the infection cycle is devoted to synthesis of coat protein, which is required in large quantities for virion assembly. A small amount of lysis protein is synthesized during translation of the coat protein gene, due to an occasional reading frame error.
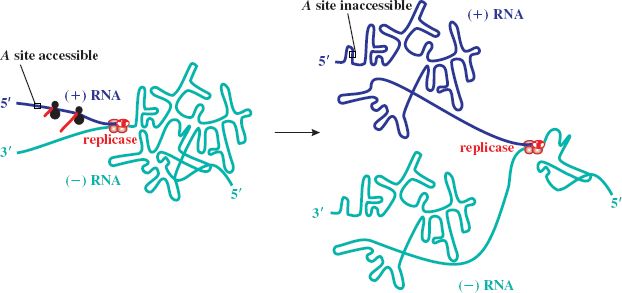
Once replicase is synthesized, replication of the genome can occur; the genome thus switches from a template for translation to a template for replication. There would be a topological problem if replication and translation occurred simultaneously, since they proceed in opposite directions along the template (3′ → 5′ and 5′ → 3′ respectively). However, it appears that translation of coat protein is repressed by replicase, which may block the coat protein ribosome entry site, and then recommences when sufficient (–) RNA has been synthesized. The replicase associates with a number of host proteins to form a phage RNA-specific polymerase (Figure 20.4), which makes both (+) and (–) strands of RNA. Replication occurs in two stages and involves replicative intermediates (RIs) composed of multiple, nascent RNA strands synthesized from a single template, and replicase: RI-1 with (+) RNA as template, and RI-2 with (–) RNA as template. Thus minus strands act as templates for synthesis of plus strands for use as mRNA. Secondary structure, which forms as each new strand is synthesized from the template strand, serves to keep the two strands apart, in turn preventing formation of a double-stranded intermediate. It is noteworthy that the error rate for such RNA replication is quite high compared with that for DNA replication. Replicase is error prone and the lack of a double-stranded intermediate means there is no template for error correction.
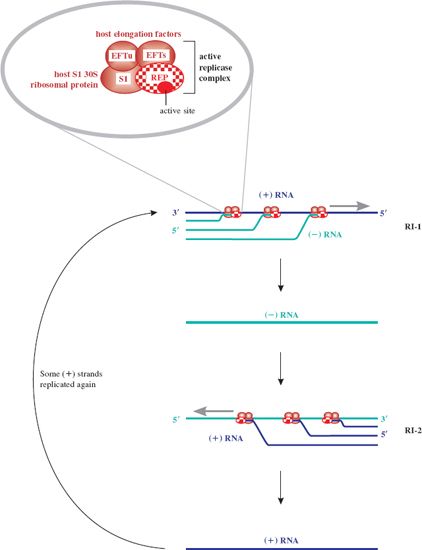
Figure 20.4 Replication of ssRNA phage genome. Replication of the single-stranded phage genome occurs through production of two replicative intermediates, RI-1 and RI-2. First, the (–) strand RNA is synthesized 5′ to 3′ antiparallel and complementary to the (+) sense template strand by replicase, in a multi-branched structure. The (–) strand RNA then serves as template for formation of new (+) strand genomic RNA. This is the only role for the (–) strands. Newly replicated (+) strands can be recycled in replication, translated to yield the capsid proteins, or encapsidated in the formation of progeny phages. The inset shows the activation of the replicase protein (REP) by associating with host proteins: for MS2 two elongation factors (EFTs and EFTu) and the ribosomal S1 protein. Replicase is an RNA-templated RNA polymerase, synthesizing both plus (+) and minus (–) strands of phage RNA 5′ to 3′ through specificity of the replicase for the 3′ end of both template strands. S1 protein is not required for new (+) strand synthesis.
Expression of the A gene occurs independently of the others and is limited to periods of nascent plus strand synthesis. The RBS of the A gene is masked by folding of the RNA genome through an LDI in which the Shine–Dalgarno sequence of A pairs with a complementary sequence upstream in the 5′ untranslated leader region. The initiator site of A becomes exposed transiently when plus strand synthesis begins, due to a delay in folding of the newly synthesized strand. This allows ribosomes to translate the A gene until the RBS is sequestered (Figure 20.5). The number of molecules of A protein is thus maintained in line with the number of new RNA plus strands. There appears to be upregulation of the A protein in Qβ, consistent with its role in cell lysis as well as infectivity. The LDI is further downstream than in MS2, so that the RBS is exposed for longer, resulting in higher levels of A gene expression.
Figure 20.5 Expression of A gene of ssRNA phage. A gene expression occurs when plus (+) strand RNA is newly synthesized. The start site for A is then exposed, but only transiently, until the ribosome binding site is sequestered by folding of the (+) strand through the long-distance interaction involving the Shine–Dalgarno sequence and its upstream complement.
Phage assembly involves spontaneous aggregation, in which the (+) RNA associates with the A protein and is encapsidated through specific recognition of the phage RNA by coat protein dimers. Progeny virions are normally released by cell lysis (see Figure 20.6 for a summary of the replication cycle), with a burst size of about 104, compared with a few hundred for DNA phages.
Thus the minimalist genome of the ssRNA phages is utilized very efficiently. Coding capacity is expanded through the use of overlapping genes. Host proteins are utilized to activate phage proteins and some phage proteins have multiple functions. The phage genome serves as a model system for investigating such mechanisms as translational coupling, translational repression, and the role of secondary structure of mRNA in the control of gene expression.
20.3 DOUBLE-STRANDED RNA PHAGES
Phages in the family Cystoviridae (from the Greek kystis, “bladder, sack”) contain a dsRNA genome, which is segmented and packaged in a polyhedral inner core with a lipid-containing envelope. Phi6 (φ6) was the first member of the family to be isolated and has been extensively studied. The genome comprises three linear segments: RNA L (large) of about 6400 nucleotides, RNA M (medium) of about 4000 nucleotides, and RNA S (small) of about 3000 nucleotides.
Transcription of the double-stranded genome (for synthesis of new plus strands) involves a phage RNA-dependent RNA polymerase. The plus-strand transcripts serve as replication templates and mRNAs. Translation of the L segment produces the early proteins that assemble to form the polymerase complex; the M segment produces structural proteins for membranes and spikes in particular, and the S segment produces structural proteins for the capsid, membrane assembly, lysis and entry, and a non-structural protein for envelopment of the capsid.
Phage φ6 infects its host, Pseudomonas syringae (pv. phaseolicola), by way of the pilus, which retracts to bring the virion into contact with the cell, and the nucleocapsid enters. Uncoating occurs inside the cell and the polymerase is released. Transcription of the genome is temporally controlled and virions assemble in the cytoplasm, with their envelope deriving from the host. Packaging of the plus-strands occurs in the order S—M—L. These single-stranded precursors are then replicated into mature double-stranded genomes inside the capsid. About 100 virions are released following cell lysis.
DNA PHAGES
20.4 SINGLE-STRANDED DNA PHAGES
There are two groups of ssDNA phages: icosahedral and filamentous. Representative icosahedral phages, φX174 and S-13, were amongst the first studied. Later, in the 1960s, filamentous phages were isolated by Don Marvin and Hartmut Hoffmann-Berling, and by Norton Zinder and co-workers.
20.4.1 Icosahedral ssDNA phages
Icosahedral ssDNA phages belong to the family Microviridae (from the Greek micros, “small”). Such phages provided the first evidence for overlapping genes and revealed the economy of genetic coding, which is a feature of several small viruses, including hepatitis B virus (Section 19.6) and the ssRNA phages (Section 20.2). Studies on replication of these phages led to the discovery of rolling circle replication and to the identity of various genes encoding proteins for host DNA replication. φX174 has been most extensively studied.
20.4.1.a Virion structure of phage φX174
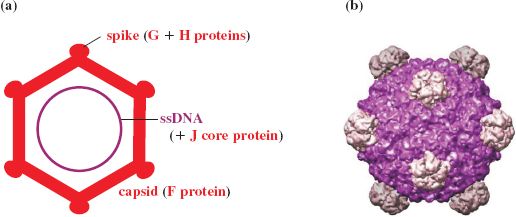
The virion of φX174 contains proteins F, G, H, and J; F forms the main shell and the spike protein G protrudes on the icosahedral five-fold axes. A molecule of H is found on each spike and acts as a pilot protein. Part of H may lie outside the shell and part within, spanning the capsid through the channels formed by the G proteins. The projections are involved in attachment to the host and delivery of the genome into the host cell. Highly positively charged DNA binding protein J is associated with the ssDNA genome (Figure 20.7).
Figure 20.7 Structure of phage φX174. (a) Virion components. (b) Reconstruction of capsid showing subunit organization. The virion contains 60 molecules of major coat protein F (48.4 kD). The spike at each vertex of the icosahedron, composed of five molecules of G protein (19.0 kD) and one molecule of H protein (35.8 kD), has a role in host recognition and attachment. Protein J (4.0 kD) binds to the phage genome for condensation of DNA during packaging. This protein subsequently binds to the internal surface of the capsid to displace the internal scaffolding protein B (13.8 kD).
Source: (b) Image rendered by Chimera, from Virus Particle Explorer (VIPER) database (Shepherd C. M. et al. (2006) VIPERdb: a relational database for structural virology, Nucleic Acids Research, 34 (database issue), D386–D389).
20.4.1.b Genome of phage φX174
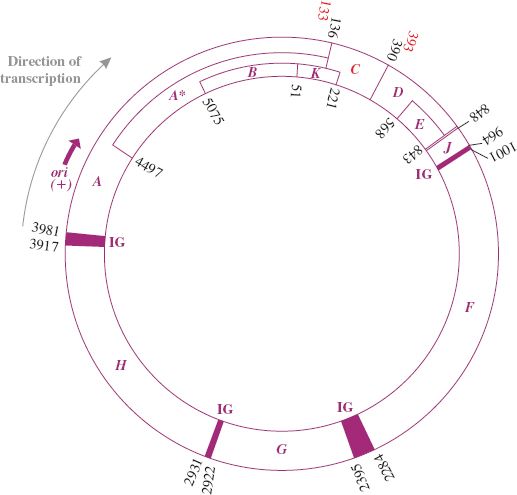
The genome is a circular ssDNA molecule of 5386 nucleotides, coding for eleven proteins. It was the first entire DNA genome to be sequenced (Section 2.9.1). The genes are tightly clustered with little non-coding sequence. The length of the genome is smaller than its coding capacity. However, the different proteins are generated through extensive use of overlapping genes translated in alternative reading frames or employing different start codons. Gene A contains an internal translation initiation site to encode protein A∗, which corresponds to the C-terminal region of protein A; B is encoded within A in a different reading frame; K is at the end of gene A and extends into gene C and is translated in a different frame to A and C; E is totally within D, but in a different reading frame; the termination codon for D overlaps initiation codon for J (see Figure 20.8). All genes are transcribed in the same direction.
Figure 20.8 Genetic organization of phage φX174. The numbers are coordinates of the genes. The direction of transcription and approximate location of origin (ori) of replication for viral (+) strand are shown. Functions of the gene products (with coordinates of the genes including termination codons) are as follows:
gene A (3981–136) protein, viral strand synthesis and RF replication;
gene A∗ (4497–136) protein, shutting down host DNA synthesis;
gene B (5075–51) protein, capsid morphogenesis;
gene C (133–393) protein, DNA maturation;
gene D (390–848) protein, capsid morphogenesis;
gene E (568–843) protein, host cell lysis;
gene F (1001–2284) protein, capsid morphogenesis—major coat protein;
gene G (2395–2922) protein, capsid morphogenesis—major spike protein;
gene H (2931–3917) protein, capsid morphogenesis—minor spike protein;
gene J (848–964) protein, capsid morphogenesis—core protein (DNA condensing protein);
gene K (51–221) protein, function not clear; appears to enhance phage yield (burst size).
IG: intergenic region at borders of genes A, J, F, G, H contains a ribosome binding site and other features.
20.4.1.c Replication cycle of phage φX174
Phage φX174 recognizes the receptor lipopolysaccharide in the outer membrane of rough strains of Enterobacteriaceae, such as E. coli and Salmonella typhimurium, by way of protein H. This protein then acts as a pilot involved with delivery of the phage DNA into the host cell for replication.
Like M13 (Section 20.4.2.c), replication of the genome of φX174 occurs in three stages and involves a double-stranded intermediate, the replicative form (RF). The viral plus strand is first converted to the RF by host enzymes. However, this process is more complex than for M13, involving the formation of a primosome that includes a number of proteins to open a hairpin found at the origin (ori) of replication of φX174 and to load the replication apparatus on to the DNA. The minus-strand is transcribed for synthesis of the phage-encoded proteins. Replication of the RF involves rolling circle replication and requires phage-encoded protein A to synthesize new plus-strands. These then serve as templates for minus-strand synthesis to generate the new RFs. The third stage is asymmetric replication of progeny ssDNA plus strands. RF synthesis continues until sufficient structural proteins have been synthesized and assembled into empty precursor particles. This is mediated by scaffolding proteins (D and B), which associate transiently with the coat proteins and induce conformational switches to drive the assembly process. A procapsid forms, with D forming the external shell and B occupying an internal location. Viral DNA plus-strands are then captured, before they can be used as templates for further minus-strands, and are packaged with basic protein J (which neutralizes the negatively charged genome). J protein binds both to the DNA and to the internal surface of the capsid, displacing the B protein, to generate the provirion. Subsequent shedding of the D protein yields the mature infectious virion. Virions accumulate in the cytoplasm and are released by cell lysis, which requires expression of the E gene for endolysin production.
20.4.2 Filamentous ssDNA phages
Filamentous ssDNA phages are in the family Inoviridae (the Greek ina, “fiber, filament”). The F-specific filamentous (Ff) phages, notably M13, fd, and f1, have been most extensively studied. They are plus-strand phages and are “male-specific,” infecting E. coli strains containing the conjugative plasmid F, by adsorbing to the tip of the F pilus (encoded by the plasmid). Unlike many other DNA phages, filamentous ssDNA phages do not inject their DNA into the host cell; rather, entire phage particles are ingested. Furthermore, these phages do not lyse infected cells, but progeny are continuously extruded through the cell membrane. Despite this, plaque-like zones are formed in a lawn of sensitive bacteria, since infected cells grow more slowly than uninfected cells.
20.4.2.a Genome of Ff phages
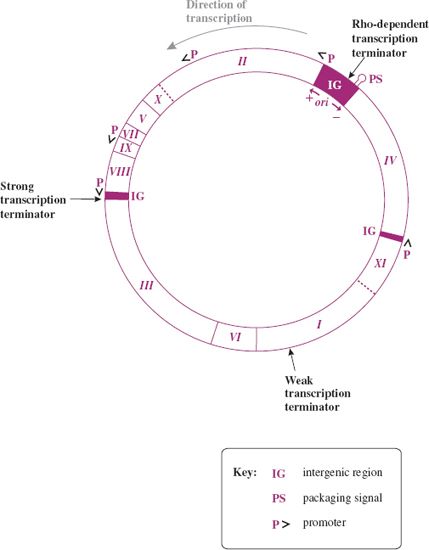
The genome of the Ff phages is a circular ssDNA molecule of about 6400 nucleotides. M13, fd, and f1 are 98% identical and generally no distinction will be made between them here. The genes are tightly packed on the genome, with a number of intergenic (IG) regions (Figure 20.9). The major IG region of 507 nucleotides (between genes IV and II) contains a number of regulatory regions: the origin of replication for (+) and (–) DNA synthesis, a strong rho-dependent transcription terminator, after gene IV, and a 78-nucleotide hairpin region, which is the packaging signal (PS) for efficient phage assembly. There is also a strong rho-independent terminator, after gene VIII, and a weaker rho-dependent terminator within gene I.
Figure 20.9 Genetic map of F-specific filamentous phage M13. The main promoters and terminators are shown. ori: origin of replication for viral (+) and complementary (–) DNA strands in main intergenic region. The direction of transcription from promoters (P) is indicated by arrowheads (>). Gene product, approximate molecular size, number of copies, and function are as follows:
pI, 35–40 kD, few copies per cell, membrane protein for assembly;
pII, 46 kD, 103 copies per cell, endonuclease/topoisomerase for replication of RF, viral strand synthesis;
pIII, 42 kD, ~5 copies per virion, minor capsid protein for morphogenesis and adhesion;
pIV, 44 kD, few copies per cell, membrane protein for assembly;
pV, 10 kD, 105 copies per cell, ssDNA binding protein controls switch from RF to viral (+) strand synthesis;
pVI, 12 kD, ~5 copies per virion, minor capsid protein for morphogenesis and attachment;
pVII, 3.5 kD, ~5 copies per virion, minor capsid protein for morphogenesis;
pVIII, 5 kD, 2700–3000 copies per virion, major capsid protein for morphogenesis;
pIX, 3.5 kD, ~5 copies per virion, minor capsid protein for morphogenesis;
pX, 12 kD, 500 copies per cell, replication of RF, viral strand synthesis;
pXI, 12 kD, few copies per cell, membrane protein for assembly.
Source: Modified from Webster (2001) In Phage Display. A Laboratory Manual, Cold Spring Harbor.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


