Figure 1 Structural features of an influenza A virion. Two glycoprotein spikes, haemagglutinin (HA) and neuraminidase (NA) and the M2 protein are embedded in a lipid bilayer derived from the host plasma membrane. The ribonucleoprotein complex (RNP) consists of viral RNA, associated with the nucleoprotein (NP) and three polymerase proteins (PA, PB1 and PB2). NS2(NEP) is associated with RNP, while the M1 protein is associated with both RNP and the viral envelope. Thus, NS1 is the only nonstructural protein of influenza A virus.
Influenza virus particles are pleomorphic with spherical or filamentous morphology, or both. Among clinical isolates that have undergone a limited number of passages in eggs or cell culture, filamentous particles outnumber the spherical particles, whereas extensively passaged laboratory strains consist almost exclusively of spherical virions (80–120nm in diameter). The morphology of influenza virions appears to be primarily determined by the M gene, although the HA, and NA genes may contribute. The HA and NA molecules that stud the surface of influenza A and B viruses range from 10 to 12nm in length (mean ratio of numbers of HA to NA spikes, ∼5:1). The HA spikes are rod-shaped, whereas the NA spikes resemble mushrooms with slender stalks (Figure 1). The HEF glycoproteins (8–10nm in length) on influenza C virions are organised on the surface as hexagonal arrays of lattice-like structures.
Complexes of viral RNA, NP and three polymerase proteins, PA, PB1 and PB2, within the lipid envelope are termed ribonucleoprotein (RNP) (Figure 1). Isolated RNP forms rod-shaped, right-handed helices that vary in length from 50 to 150nm. These RNP helices appear to be arranged in a highly ordered structure within virions, with a peripheral ring-like structure that surrounds one RNP helix in the center (Noda et al., 2006). The 5′- and 3′-terminal ends of the viral RNA, which are complementary to each other, form the viral promoter for replication and transcription, with which the polymerase complex is associated.
The M1 protein of influenza A virus is the primary determinant of virus budding and may execute a role similar to that of retroviral gag proteins or matrix proteins of other negative-strand RNA viruses. Cryoelectron microscopic studies suggest that M1 can modify the lipid bilayer, causing thickening of the viral envelope.
Genome
Influenza A and B viruses possess eight single-stranded RNA segments, each encoding at least one protein, whereas influenza C viruses contain only seven segments. Genome lengths differ widely among the three types of influenza virus, with some variation also found among strains of the same type. Type B viruses have the longest genome (∼14600 nucleotides), followed by A (∼13600 nucleotides) and then C (∼12900 nucleotides). Within each type, the lengths of genes other than those encoding HA and NA (for A and B viruses), and the HEF (for C viruses), are highly conserved. The viral genome constitutes 2% of the mass of the virion.
In each of the eight RNA segments of all influenza A viruses, the first 12 nucleotides at the 3′-end and the last 13 at the 5′-end are highly conserved and form a so-called corkscrew conformation (characterised by intra-strand base pairing between the 5′- and 3′-terminal nucleotides) that contains promoter activity. Similar structures have been identified in the RNA segments of influenza C and Thogoto viruses.
The majority of viral genes encode a single protein (Table 1). Exceptions include the M and NS genes of all influenza viruses, the PB1 gene of the majority of influenza A viruses and the NA gene of type B virus, which encode two proteins each. The NS gene of type A virus encodes both a 26-kDa (NS1) protein from translation of unspliced mRNA and a 14-kDa (NS2) protein from translation of spliced mRNA (Figure 2a), which share the same AUG initiation codon and nine subsequent codons. A similar protein coding strategy is employed by the type B and C influenza viruses.
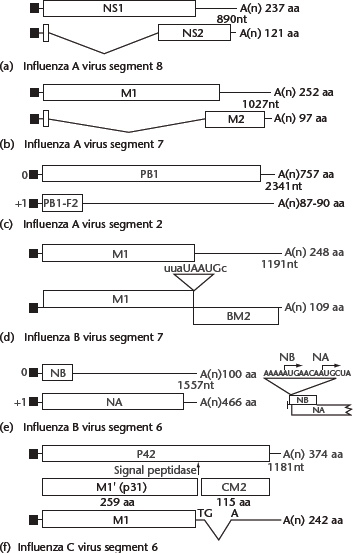
Figure 2 Coding strategies of influenza virus genes. (a) Influenza A virus NS1 and NS2 mRNAs and their coding regions. NS1 and NS2 share 10 N-terminal residues, including the initiating methionine. The reading frame of NS2 mRNA (nucleotide positions 529–861) differs from that of NS1. (b) Influenza A virus M1, M2 mRNAs and mRNA3 and their coding regions. M1 and M2 share nine N-terminal residues, including the initiating methionine; however, the reading frame of M2 mRNA (nucleotide positions 740–1004) differs from that of M1. A translation product of mRNA3 has not been found in cells. (c) Coding regions of the influenza A virus PB1 segment. Based on Kozak’s rule, PB1 translation initiation may be inefficient, thereby allowing translation initiation of the PB1-F2 open reading frame by ribosomal scanning. (d) Influenza B virus RNA segment 7 open reading frames and the organisation of the open reading frames used to translate the M1 and BM2 proteins. The stop–start pentanucleotide is also illustrated. (e) Open reading frames in influenza B virus RNA segment 6, illustrating the overlapping reading frames of NB and neuraminidase (NA). The nucleotide sequence surrounding the two AUG initiation codons, in mRNA sense, is shown to the right. (f) Influenza C virus mRNAs derived from RNA segment 6. The unspliced and spliced mRNAs encode P42 and M1, respectively. Cleavage of P42 by a signal peptidase yields M1′ and CM2. For (a)–(f), thin lines at the 5′ and 3′ termini of the mRNAs represent untranslated regions. The shaded or hatched areas represent different coding regions. Introns in the mRNAs are shown by V-shaped lines; filled rectangles at the 5′ ends of mRNAs represent heterogeneous nucleotides derived from cellular RNAs that are covalently linked to viral sequences. Numbers to the right indicate the number of amino acids (aa) encoded by each open reading frame. From Cox NJ, Neumann G, Donis RO and Kawaoka Y (2005) Orthomyxoviruses: influenza. In: Collier L, Balows A and Sussman M (eds) Topley & Wilson’s Microbiology and Microbial Infections, pp. 634–698. London: Arnold.
Copyright Edward Arnold Publisher Ltd. Reproduced with permission of Edward Arnold.
Table 1 Influenza A virus genome RNA and protein coding assignments

By contrast, mechanisms for the expression of M gene products differ among influenza virus types. The M gene of type A viruses generates an unspliced transcript encoding the M1 protein, as well as two other alternatively spliced RNAs, designated M2 and mRNA3, which differ in their use of 5′ splice sites (Figure 2b). A translation product of mRNA3 has not been found in cells. The M gene of influenza B viruses also encodes two proteins, M1 and BM2, that are synthesised by a termination–reinitiation scheme of tandem cistron translation; a pentanucleotide sequence, UAAUG, contains the termination codon for M1 and the initiation codon for BM2 (Figure d). Finally, in contrast to the scheme employed by influenza A viruses, type C viruses rely on spliced transcripts to produce M1 protein (Figure 2f). A splicing event introduces a translational termination codon into the primary transcript, resulting in the synthesis of the M1 protein of 242 amino acids. The unspliced mRNA is translated into a protein of 374 amino acids (P42), which is proteolytically cleaved into the CM2 and M1 proteins; the former has biochemical properties similar to those of the influenza A virus M2 protein.
Still another mechanism of viral protein synthesis is represented by the influenza B virus NA gene, which gives rise to a bicistronic mRNA containing two initiating AUG codons that are separated by four nucleotides (Figure 2e). The 100-amino acid NB protein is the result of translational initiation at the 5′ AUG codon, while the 466 amino acid NA protein is the result of translational initiation at the second AUG codon. Even though the NA initiation codon is positioned downstream of the NB initiation site, greater amounts of NA protein (NA:NB ratio of 1.0:0.6) accumulate in cells.
The majority of influenza A viruses express a second polypeptide, termed PB1-F2, from the +1 reading frame of the PB1 gene (Figure 2c; Chen et al., 2001). The 87 amino acid peptide localises to the mitochondria where it induces apoptosis. However, the PB1-F2 reading frame is missing from some animal (particularly swine) virus isolates, leaving in question its biological significance.
Structural and nonstructural proteins
Influenza A virus contains genes for nine structural and one nonstructural protein (and the majority of influenza A isolates express an additional polypeptide from their PB1 gene) (Table 1), compared with nine structural and two nonstructural proteins for influenza B, and six structural and three nonstructural proteins for influenza C.
Polymerase proteins
An acidic (PA) and two basic (PB1 and PB2) proteins, encoded by the three largest RNA segments, form the polymerase complex. These three proteins are highly conserved in influenza A viruses. PB1 forms the structural backbone by interacting with both PB2 and PA. In vitro, PB1–PB2 or PB1–PA complexes have transcriptase or replicase activity, respectively; however, all three subunits are likely required for efficient replication and transcription in virus-infected cells.
PB1
This protein is required for the initiation and elongation of newly synthesised viral RNA. Binding of PB1 to the viral promoter structure activates the capped-mRNA endonuclease activity of the PB1 protein. PB1 contains two discontinuous regions, both of which are essential for nuclear localisation.
PB2
PB2 recognises and binds to type I cap structures of cellular mRNAs. It is essential for viral mRNA synthesis, whereas its role in replication remains under investigation. Two signals mediate nuclear localisation of influenza A PB2 protein; one of them is involved in PB2 perinuclear binding. PB2 also plays a role in host range restriction, exemplified by the significance of amino acid 627 of 1997 H5N1 Hong Kong viruses for virulence in mice: glutamic acid at this position (found in avian isolates) was nonpathogenic for mice, whereas lysine (found in human isolates) was highly pathogenic (Hatta et al., 2001). Notably, the same amino acid replacement was found in an H7N7 influenza virus isolated from a Dutch veterinarian who succumbed to influenza virus infection in 2003 (Fouchier et al., 2004) and in H5N1 viruses isolated from Vietnamese influenza virus victims in 2004 (Li et al., 2004; Puthavathana et al., 2005). Interestingly, the 2009 pandemic H1N1 viruses possess the avian-type amino acid (that is, glutamic acid) at position PB2-627 (Dawood et al., 2009). Recent findings demonstrated that a compensatory mutation in PB2 allows efficient replication of 2009 pandemic H1N1 viruses in mammalian cells, even though these viruses possess the avian-type amino acid at PB2-627 (Mehle and Doudna, 2009; Yamada et al., 2010).
PA
The PA protein is an essential component of the viral polymerase complex. It is required for viral RNA replication and may be involved in transcription. Expression of PA itself does not result in complete nuclear accumulation which can only be achieved after coexpression of PB1 or NS1.
HA
Accounting for about 25% of viral protein, the HA is distributed evenly on the surface of virions and is responsible for the attachment and subsequent penetration of viruses into cells. The HA spikes, approximately 14nm×4nm, protrude from the virion surface. The HA homotrimer is synthesised as a single polypeptide chain (HA0) with cotranslational glycosylation and removal of an N-terminal signal sequence and subsequently undergoes posttranslational cleavage by cellular proteases. The resulting HA1 and HA2 subunits (molecular weights of 36000 and 27000) are covalently attached by a disulfide bond, whereas the ‘tow-chain’ monomers are associated noncovalently to form trimers. An N-terminal signal sequence is removed. HA cleavage is required for infectivity because of the hydrophobic N-terminus of HA2, which mediates fusion between the viral envelope and the endosomal membrane. The C-terminus of HA2 and the uncleaved HA0 contain a transmembrane domain and short cytoplasmic domain.
Three-dimensional structure
The HA ectodomain is folded into two structurally distinct domains, a globular head and a fibrous stalk. Influenza A virus HAs show subtype-specificity and are thought to possess five antigenic sites in the three-dimensional structure. The globular head, composed entirely of HA1 residues, includes an eight-stranded antiparallel β sheet. This framework supports the receptor-binding site, which is surrounded by highly variable antigenic loop structures. The fibrous stalk region, more proximal to the viral membrane, consists of residues from both HA1 and HA2. The cleavage site between HA1 and HA2 resides in the middle of the stalk. The C-terminus of HA1 is exposed on the trimer surface. The hydrophobic N-terminus of the HA2 (fusion peptide) is buried in the trimeric structure, which is principally stabilised by the fibrous stem regions.
Folding, assembly and intracellular transport
During its synthesis in the endoplasmic reticulum, HA interacts transiently with the BiP/GRP78 protein and calnexin before forming trimers, a prerequisite for its transport out of the endoplasmic reticulum. Disulfide bonds are formed cotranslationally. In the Golgi apparatus, the oligosaccharide of the HA is further processed to the complex type. The HAs of virulent avian H5 and H7 viruses are cleaved in the trans-Golgi or trans-Golgi network by ubiquitous proteases. In polarised cells, the final step of HA maturation is transport of the molecule to the apical cell surface (transport from the trans-Golgi network is energy-dependent). This transport relies on MAL, a nonglycosylated integral membrane protein that is a component of the apical transport machinery. However, viruses containing a mutant, basolateral sorting signal in their HA bud almost exclusively from the apical surface, indicating that factors other than the HA contribute to virus budding. HA associates with rafts, i.e. sphingomyelin- and cholesterol-enriched microdomains in the cellular membrane. This raft association is believed to increase the local concentration of HA. The transmembrane domain contains signals for specific incorporation of the HA into virions.
HA cleavage
HA cleavability is clearly linked to virulence in avian influenza A viruses (Garten and Klenk, 1999; Horimoto and Kawaoka, 2001). The HAs of virulent H5 and H7 avian viruses contain multiple basic amino acids at the cleavage site, which are cleaved intracellularly by endogenous proteases. By contrast, in avirulent avian as well as nonavian influenza A viruses, with the exception of H7N7 equine viruses, the HAs lack a series of basic residues and are not subject to cleavage by such proteases. Thus, the tissue tropism of viruses may be determined by the availability of proteases responsible for the cleavage of different HAs, leading to differences in virulence.
Two groups of proteases appear to be responsible for HA cleavage. One includes enzymes that recognise a single arginine and are able to cleave ‘avirulent’-type HAs, such as plasmin, blood-clotting factor X-like protease, tryptase Clara and bacterial proteases. The second group comprises ubiquitous intracellular subtilisin-related proteases – furin and PC6 – which cleave virulent-type HAs with multiple basic residues at the cleavage site. The number of basic amino acids at the cleavage site and the presence or absence of a nearby carbohydrate affects HA cleavability by intracellular proteases in an interrelated manner. The proposed sequence requirement for HA cleavage by intracellular proteases, in the absence of a nearby carbohydrate (at residue 11 in the H5 numbering system) is Q-R/K-X-R/K-R (X=nonbasic residue). If the carbohydrate moiety is present, virulence is maintained only if two amino acids are inserted (Q-X-X-R/K-X-R/K-R). Although the majority of HAs in influenza A and B viruses contain Arg at the C-terminus of the HA1, the H14 subtype and some human H1 viruses contain Lys at this position.
Oligosaccharide side chains
The location and number of asparaginyl-glycosylation sites (N-X-S/T, X=residue other than P) are not conserved among the HAs of different strains and subtypes. The HAs of individual virus strains contain from 5 to 11 sites. Approximately 17–20% of the total protein surface of the H3HA could be covered by carbohydrate. The presence or absence of oligosaccharide side-chains in the HA affects antibody and CD4 T-cell recognition of the molecule, receptor specificity, virulence, replication, host range, fusion activity and calnexin/calreticulin binding. Growth restriction due to the lack of HA glycosylation site(s) can be partially overcome by the introduction of mutations in NA, suggesting that a functional balance between HA and NA is critical for efficient virus propagation. Particular oligosaccharide side-chains are not required for folding, intracellular transport or function of the molecule; however, at least two or three oligosaccharide chains (depending on the viral strain) must be present to ensure transport of the molecule to the cell surface.
Acylation
The three cysteine residues in the C-terminal region of the HA2 are acylated with palmitic acid by a thioester linkage. The lack of HA acylation affects HAs differently, depending on the subtype.
Receptor binding
Influenza A and B virus HAs bind to oligosaccharide-containing terminal sialic acids, including NeuAc α2,6Gal β1, 4GlcNAc and NeuAc α2,3Gal β1, 4Glc. Topologically, the binding site is a depression. The amino acid residues in HA1 that contact the terminal sialic acids are highly conserved among the different HA subtypes.
The receptor specificity of HA differs among influenza A viruses. Most avian and equine influenza viruses bind preferentially to the NeuAc α2,3Gal linkage, whereas human and classic H1N1 swine influenza viruses preferentially bind to the NeuAc α2,6Gal linkage on cell surface sialyloligosaccharides (Rogers and Paulson, 1983). Epithelial cells in the human trachea were thought to contain SA α2,6Gal but not SA α2,3Gal sialyloligosaccharides on the cell surface, resulting in efficient binding of viruses with NeuAc α2,6Gal specificity but not of those with NeuAc α2,3Gal specificity. However, findings with cultures of differentiated human airway epithelium cells indicate that NeuAc α2,6Gal sialyloligosaccharides are expressed on nonciliated epithelial cells, whereas ciliated cells express NeuAc α2,3Gal (Matrosovich et al., 2004). Correspondingly, human viruses infected preferentially nonciliated cells, whereas avian viruses infected ciliated cells. Additional studies demonstrated avian-type receptors on human alveolar epithelial cells, but human-type receptors on human epithelial cells in the bronchi, trachea, pharynx, paranasal sinuses and nasal mucosa (Shinya et al., 2006; van Riel et al., 2006). Epithelial cells in duck intestine (the replication site of avian influenza viruses) and those in horse trachea contain SA α2,3Gal but not SA α2,6Gal sialyloligosaccharides. Interestingly, epithelial cells in pig trachea contain both types of sialyloligosaccharides, which explains why both human and avian viruses replicate efficiently in pigs. Thus, the receptor specificities of the viruses correspond to the presence of the receptor at the replication site of the virus. The HAs of influenza B viruses also preferentially recognise NeuAc α2,6Gal linkages.
Fusion
The fusion of influenza viruses to the endosomal membrane is mediated through the HA. Under conditions of neutral pH, the fusion peptide, which forms a small part of the N-terminus of the HA2, is located in the fibrous stem of the molecule (∼3.5nm away from the viral membrane; hence, 10nm from the target endosomal membrane), and is well integrated into the subunit interface by a network of hydrogen bonds. When the pH is approximately 5 (late endosomal pH), the tertiary structure of the HA is altered. Soon after, the fusion peptide and other sequences buried in the stem become exposed, followed by the aggregation of several of the trimers and formation of a fusion pore within the interior of the aggregate. The transmembrane regions of the HA appear to have an important, though still undefined, role in the fusion process, as glycosylphosphatidylinositol-anchored HAs promote only hemifusion (a state in which lipids, but not the contents of the fusion compartments, mix).
Fusion is initiated by major refolding of the secondary and tertiary structures of the HA molecule. The loop preceding the buttressing helix of the neutral pH form becomes part of the coiled coil, extending the N-terminus of HA2. Such alteration could be expected to transport the fusion peptide 15nm or more, bringing it into close contact with the endosomal membrane.
NP
NP, the most abundant component of RNP, is a type-specific antigen associated with viral RNA. It covers 20–24 nucleotides, exposing the bases to the outside. Thus, vRNA may be wrapped around the NP scaffold (Figure 1). By electron microscopy, purified NP has a rod-like shape with dimensions of 6.2nm×3.5nm; most of these proteins exist in polymeric forms that resemble viral RNP. However, the formation of helical structures similar in conformation and density to intact viral RNP requires both vRNA and M1 protein. The NP possesses several signals that regulate its nuclear import early in infection, but cytoplasmic accumulation late in infection. These transport processes are regulated by phosphorylation. NP likely migrates to the cytoplasm as a component of RNP complexes; however, free NP is needed for vRNA synthesis.
As a major antigen recognised by cytotoxic T lymphocytes, the NP possesses several T cell-specific epitopes that are conserved among human influenza A viruses. The transfer of cytotoxic T lymphocytes specific to NP protects mice from lethal influenza challenge.
NA
The tetrameric NA protein of influenza A viruses, a type II glycoprotein with its N-terminus inside the cell and its C-terminus outside, is one of two major glycoproteins on the virus surface. It has an uncleaved N-terminal signal/anchor domain and a six-amino acid tail that presumably is exposed to the cytoplasm. Its head is box-shaped (10nm×10nm×6nm), comprising four coplanar and roughly spherical subunits and contains the enzyme-active centre and major antigenic sites. The stalk is centrally attached to the head by a hydrophobic region, by which the stalk is embedded in the viral membrane (Figure 1). The stalk region varies in length and sequence. In contrast to the remainder of the NA, the six-amino acid cytoplasmic tail is highly conserved among all NA subtypes of influenza A virus. This region affects incorporation of the NA into virions but is not essential for virus replication. A mutant lacking the tail contains more filamentous than spherical particles.
The NA plays a role in host range restriction. The NA of A/WSN/33 (H1N1) binds and sequesters plasminogen, allowing plasmin-mediated HA cleavage, leading to systemic infection of animals with influenza A virus.
Three-dimensional structure
The three-dimensional structure has been solved in both type A and B viruses. Despite the 28% homology between these two types of viruses, the overall folding patterns of their NAs are almost identical. The tetrameric NA protein has circular 4-fold symmetry stabilised by calcium. The polypeptide chain folds into six topologically identical four-stranded antiparallel β sheets arranged like propeller blades. The product of catalysis, sialic acid, is bound in a large pocket on the distal surface, flanked and surrounded by nine acidic residues, each of which is strictly conserved in all known influenza viral NA sequences. Knowledge of three-dimensional structure of the NA led to the synthesis of a potent sialidase inhibitor, 4-guanidino-2, 4,-dideoxy-2, 3-dehydro-N-acetylneuraminic acid, which inhibits the NA activity of both type A and B viruses (inhibition constants, 10−9−10−10molL−1).
Sialidase activity
The NA catalyses the cleavage of the α-ketosidic linkage between a terminal sialic acid and an adjacent sugar residue. The pH optimum of the enzyme ranges from 5.8 to 6.6, with an apparent Km of 0.4mmolL−1 with use of N-acetylneuraminyl lactose. Removal of sialic acid residues by the NA promotes both entry and release of virus from infected cells. The majority of NAs of type A and B viruses cleave NeuAc α2,3Gal in preference to NeuAc α2,6Gal. The NA has little activity against 4-0-Ac-Neu. The preference of the linkage specificity of the human influenza A NA has shifted over the years, from NeuAc α2,3Gal to NeuAc α2,6Gal linkages, presumably corresponding to the preferential recognition of the latter linkages by the HA molecule.
HA activity
All avian virus NAs possess HA activity. The N9 HA activity can be transferred to the NAs of other NA subtypes by altering amino acid residues that are located apart from the NA active site, indicating discrete HA and NA active sites in these NA molecules. The biological significance of the HA activity in the avian virus NAs remains unknown.
NB
The dimeric, integral membrane protein NB, a protein unique to type B viruses and containing polygalactosaminoglycan, has an N-terminal portion that is exposed on the cell surface. NB contains structural features similar to those of the M2 protein and was therefore thought to function as an ion channel. However, reverse genetics studies revealed that it is dispensable for virus replication in vitro. The role of this protein in viral replication therefore remains obscure.
M1
The most abundant virion protein and a type-specific antigen of influenza viruses, the M1 has long been thought to be located underneath and to add rigidity to the lipid bilayer, although direct evidence for such a role is lacking. Cryoelectron microscopic studies suggest that the M1 can modify the lipid bilayer, causing the viral envelope to thicken. M1 is the major determinant of virus budding. Furthermore, it determines the morphology of influenza virions, although other viral proteins likely contribute. Located in both the nucleus and the cytoplasm, this protein contains a karyophilic signal (residues 101-RKLKR-105) and multiple lipid-binding regions. Replacement of amino acids 100–104 with a ‘late domain’ motif yielded replicating virus, suggesting that this region of M1 may have a function similar to the ‘late domains’ of retroviral gag or Ebola virus matrix proteins. M1 is critical for nuclear export of vRNP complexes and may execute this function by tethering the viral nuclear export factor NS2 (NEP) to components of the vRNP complex. In the cytoplasm, M1 is associated with the membrane fraction. It also contains RNA-binding domains, which have been mapped between residues 90–109 and 129–164. The M1 proteins of influenza A and B viruses have a zinc-finger motif and purified virions contain zinc; however, the amount of zinc is not correlated with the RNA-binding activity of the protein, suggesting that zinc binding and RNA binding are independent activities. The M1 proteins of influenza A and B viruses are phosphorylated. M1 also inhibits RNP transcription activity, and thus is considered to serve as a molecular switch that initiates the final step of virus assembly.
One of the M gene products, most likely M1, contributes to the dominance phenotype shown by attenuated, cold-adapted A/Ann Arbor/6/60 (H2N2) in coinfection studies with other strains, both in vitro and in vivo. The M1 protein has also been linked to rapid virus growth.
M2
The integral homotetrameric M2 membrane protein, although abundantly expressed at the surface of virus-infected cells, is nonetheless a relatively minor component of virions. Sharing eight N-terminal residues with M1 (Figure 2b), the M2 protein consists of 97 amino acids: 24 as the ecto-, 19 as the transmembrane and 54 as the cytoplasmic domain. M2 proteins are palmitylated at Cys50, with the exception of those of H3N8 equine viruses; however, palmitylation is not essential for virus replication. The protein is also phosphorylated, mainly at Ser64. M2 proteins are thought to function as pH-activated ion channels that permit protons to enter the virion during uncoating, thereby modulating the pH of intracellular compartments. This function is essential for the prevention of acid-induced conformational changes of intracellularly cleaved HAs (H5 and H7 HA subtypes of virulent avian influenza A virus) in the trans-Golgi network. The activity of the M2 ion channel is blocked by the anti-influenza A drug amantadine hydrochloride. The M2-associated ion channel activity resides in the transmembrane region, the primary site of mutations (residues 27, 30, 31 and 34) in amantadine-resistant mutants. The M2 protein forms a homotetramer by noncovalent association of M2 dimers disulfide-linked at Cys17 and/or Cys19. None of the cysteine residues in the M2 are essential for viral replication.
M gene products of influenza B or C viruses
BM2, encoded by the M gene of influenza B viruses, is critical for the viral life cycle. It is an oligomeric, integral membrane protein that possesses ion channel activity; hence, it is considered to be the equivalent of the influenza A virus M2 protein.
CM2 is generated by proteolytical cleavage of a precursor protein translated from unspliced transcripts of the M gene. Biochemical findings suggest its role as an ion channel protein but direct experimental evidence for this function is missing.
NS1
The only nonstructural protein of influenza A virus, NS1 is produced in abundance during early infection. Encoded by a colinear mRNA (Figure 2a), it consists of 124–238 amino acids, depending on the virus strain, is phosphorylated and contains two karyophilic signals. It binds to double-stranded RNA, preventing the activation of interferon-induced protein kinase R, transcription factors, and the 2′–5′ oligo (A) synthetase/RNase L pathway (Min and Krug, 2006), hence suggesting a role of this protein in the prevention of interferon-mediated antiviral responses. It also inhibits mRNA splicing and the nuclear export of cellular and viral mRNA, maximising the availability of substrate for capped primers and thereby promoting viral mRNA synthesis. Two functional domains have been identified for NS1. The N-terminal 73 amino acids encompass the RNA-binding domain and are sufficient for dimerisation, whereas amino acids 134–161 form the so-called effector domain that is required for the inhibition of nuclear export of polyA-containing cellular mRNAs. However, the entire C-terminal half of the protein may be required for efficient inhibition of nuclear export of cellular mRNAs. Despite its several functions, an NS1-knockout virus was viable even in ordinary cells (although it grew less efficiently in these cells than in interferon-negative cells), suggesting regulatory or modulatory, rather than essential functions, for NS1. Several amino acids have now been identified in NS1 that contribute to viral pathogenicity, such as the amino acid at position 92 (Seo et al., 2002) or the PDZ domain motif located at the C-terminus of NS1 (Obenauer et al., 2006; Jackson et al., 2008).
NS2(NEP)
Encoded by a spliced mRNA (Figure 2a), the NS2(NEP) protein contains 121 amino acids, undergoes phosphorylation, is located in the nucleus and cytoplasm of infected cells and is also found in virions. NS2 contains a classic nuclear export signal (NES) and interacts with the cellular nuclear export factor CRM1, which mediates nuclear export of proteins containing NESs. NS2(NEP) likely functions as the viral nuclear export protein by connecting the cellular export machinery with vRNPs through M1 (Figure 1).
HEF
The HEF protein of influenza C virus resides on the virion surface as a discrete projection. It is synthesised as a single polypeptide with subsequent trimer formation and then cleaved into two disulfide-linked subunits, HEF1 and HEF2. HEF facilitates the binding of virus to its cell surface receptor, an oligosaccharide containing a terminal 9-α-acetyl-N-acetylneuraminic acid. The 9-α-acetyl group is critical for the binding of HEF, which does not recognise N-acetyl or N-glycolyl sialic acid. The receptor-destroying enzyme (esterase) of influenza C virus resides in the HEF protein, at a site distinct from that responsible for receptor binding. This activity does not catalyse the cleavage of the α-ketosidic linkage between terminal sialic acid and an adjacent sugar residue, but instead catalyses the cleavage of the 9-α-acetyl group of 9-α-acetyl-N-acetylneuraminic acid. The protein also possesses fusion activity, which requires a low pH optimum (between 5.0 and 5.7). HEF is acylated, but with stearic acid, instead of palmitic acid, as in the HAs of influenza A and B viruses.
Replication
The replication cycle of influenza viruses has been studied most extensively with type A strains; hence, unless otherwise noted, the processes described below refer to those viruses (Figure 3).
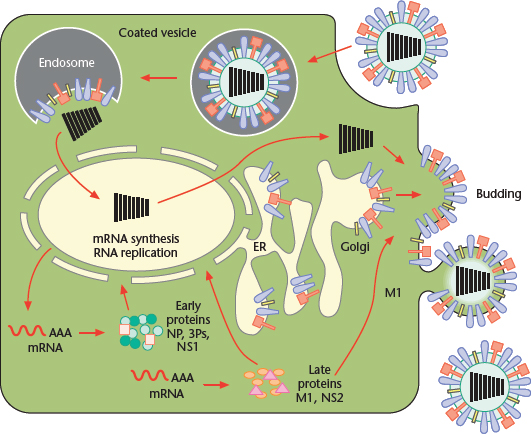
Figure 3 Replication cycle of Influenza A virus, from binding of the virus to the host cell surface to its exit from the plasma membrane. Modified from Lamb RA, Holsinger LJ and Pinto LH (1994) The influenza A virus M2 ion channel protein and its role in the influenza virus life cycle. In: Wimmer E (ed.) Cellular Receptors for Animal Viruses, pp. 303–321. Cold Spring Harbor: Cold Spring Harbor Laboratory Press.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


