Single Nucleotide Polymorphisms
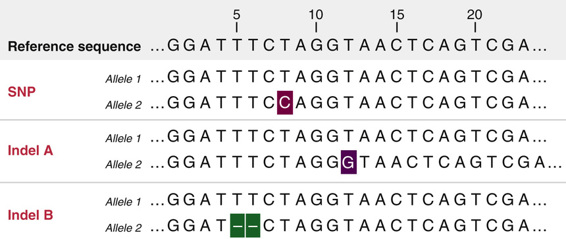
The simplest and most common of all polymorphisms are single nucleotide polymorphisms (SNPs). A locus characterized by a SNP usually has only two alleles, corresponding to the two different bases occupying that particular location in the genome (see Fig. 4-1). As mentioned previously, SNPs are common and are observed on average once every 1000 bp in the genome. However, the distribution of SNPs is uneven around the genome; many more SNPs are found in noncoding parts of the genome, in introns and in sequences that are some distance from known genes. Nonetheless, there is still a significant number of SNPs that do occur in genes and other known functional elements in the genome. For the set of protein-coding genes, over 100,000 exonic SNPs have been documented to date. Approximately half of these do not alter the predicted amino acid sequence of the encoded protein and are thus termed synonymous, whereas the other half do alter the amino acid sequence and are said to be nonsynonymous. Other SNPs introduce or change a stop codon (see Table 3-1), and yet others alter a known splice site; such SNPs are candidates to have significant functional consequences.
The significance for health of the vast majority of SNPs is unknown and is the subject of ongoing research. The fact that SNPs are common does not mean that they are without effect on health or longevity. What it does mean is that any effect of common SNPs is likely to involve a relatively subtle altering of disease susceptibility rather than a direct cause of serious illness.
Insertion-Deletion Polymorphisms
A second class of polymorphism is the result of variations caused by insertion or deletion (in/dels or simply indels) of anywhere from a single base pair up to approximately 1000 bp, although larger indels have been documented as well. Over a million indels have been described, numbering in the hundreds of thousands in any one individual’s genome. Approximately half of all indels are referred to as “simple” because they have only two alleles—that is, the presence or absence of the inserted or deleted segment (see Fig. 4-1).
Microsatellite Polymorphisms
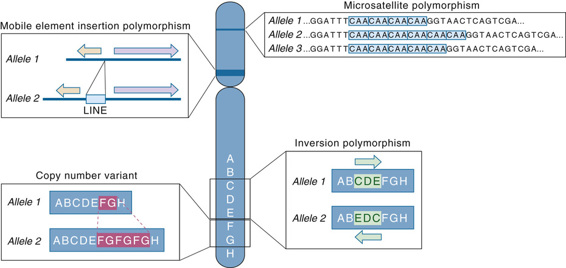
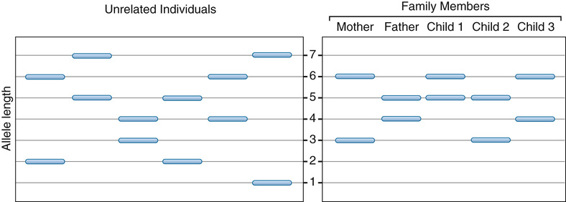
Other indels, however, are multiallelic due to variable numbers of the segment of DNA that is inserted in tandem at a particular location, thereby constituting what is referred to as a microsatellite. They consist of stretches of DNA composed of units of two, three, or four nucleotides, such as TGTGTG, CAACAACAA, or AAATAAATAAAT, repeated between one and a few dozen times at a particular site in the genome (see Fig. 4-2). The different alleles in a microsatellite polymorphism are the result of differing numbers of repeated nucleotide units contained within any one microsatellite and are therefore sometimes also referred to as short tandem repeat (STR) polymorphisms. A microsatellite locus often has many alleles (repeat lengths) that can be rapidly evaluated by standard laboratory procedures to distinguish different individuals and to infer familial relationships (Fig. 4-3). Many tens of thousands of microsatellite polymorphic loci are known throughout the human genome.
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


