Chapter 7 The Human Genome
Humans, for example, have 700 times more DNA than Escherichia coli, but they have only six times more genes (Table 7.1). This disparity comes from the fact that 90% of E. coli DNA, but only 1.3% of human DNA, codes for proteins.
Chromatin consists of DNA and histones
Eukaryotic cells have five major types of histones (Table 7.2). With the exception of histone H1, whose structure varies in different species and even in different tissues of the same organism, the histones are well conserved throughout the phylogenetic tree. For example, histones H3 and H4 from pea seedlings and calf thymus differ in only four and two amino acid positions, respectively. Presumably, the histones were invented by the very first eukaryotes, perhaps as early as 2 billion years ago, and have served the same essential functions ever since.
Table 7.2 Five Types of Histones
| Type | Size (Amino Acids) | Location |
|---|---|---|
| H1 | 215 | Linker |
| H2A | 129 | Nucleosome core |
| H2B | 125 | Nucleosome core |
| H3 | 135 | Nucleosome core |
| H4 | 102 | Nucleosome core |
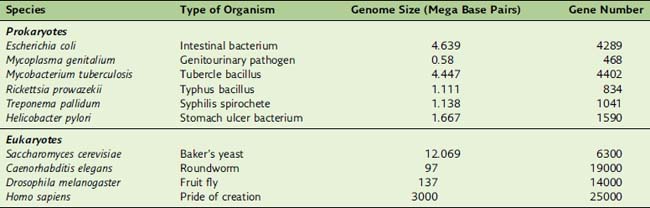
The nucleosome is the structural unit of chromatin
Under the electron microscope, euchromatin looks like beads on a string. The “string” is the DNA double helix, and the “beads” are nucleosomes, which are little disks formed from two copies each of histones H2A, H2B, H3, and H4. One hundred forty-six base pairs of DNA are wound around the histone core in a left-handed orientation. The DNA between the nucleosomes, typically 50 to 60 base pairs in length, can associate with a molecule of histone H1 (Fig. 7.1). This happens especially during the formation of higher-order chromatin structures.
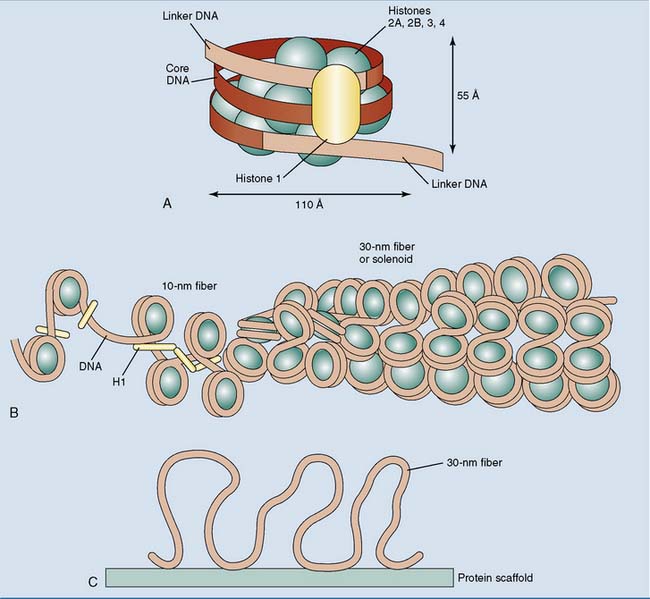
Beads on a string are typical for euchromatin, but transcriptionally silent heterochromatin is present mainly in the form of the 30-nm fiber (Fig. 7.1, B). The 30-nm fiber is about 40 times more compact than the stretched-out DNA double helix. Further compaction occurs during the formation of mitotic and meiotic chromosomes, when the 30-nm fiber attaches to chromosomal scaffold proteins, forming long loops (Fig. 7.1, C). Metaphase chromosomes are about 200 times more compact than the 30-nm fiber.
Covalent histone modifications regulate DNA replication and transcription
DNA methylation silences genes
About 3% of the cytosine in human DNA is methylated:
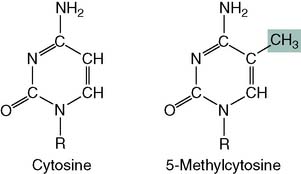
DNA methylation has several functions:
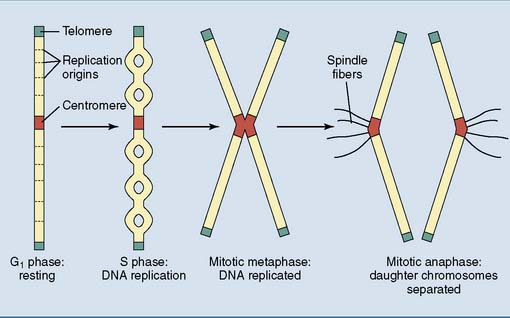
All eukaryotic chromosomes have a centromere, telomeres, and replication origins
Chromosomes need specialized structures to ensure their structural integrity, replication, and transmission during mitosis (Fig. 7.2).
Telomerase is required (but not sufficient) for immortality
Replication of linear DNA in eukaryotic chromosomes poses a special problem. At the end of the chromosome, the leading strand can be extended to the very end of the template. The lagging strand, however, is synthesized in the opposite direction from small RNA primers. Even in the unlikely case that the last primer is at the very end of the template strand, its removal would leave a gap that cannot be filled by DNA polymerase (Fig. 7.3, A).
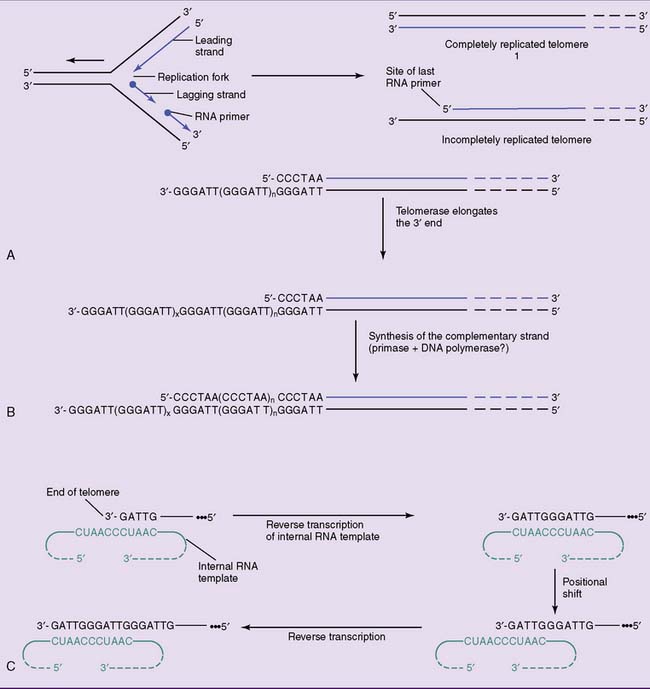
The enzyme telomerase solves this problem by adding the telomeric TTAGGG sequence to the overhanging 3′ end. No DNA template is available for this reaction; therefore, telomerase contains an RNA template. One section of this 150-nucleotide RNA is complementary to the telomeric repeat sequence. By base pairing with the DNA, it serves as a template for the elongation of the overhanging 3′ terminus. This extended 3′ end is then used as a template for the extension of the opposite strand (see Fig. 7.3, B and C). Telomerase qualifies as a reverse transcriptase, which is an enzyme that uses an RNA template for the synthesis of a complementary DNA.
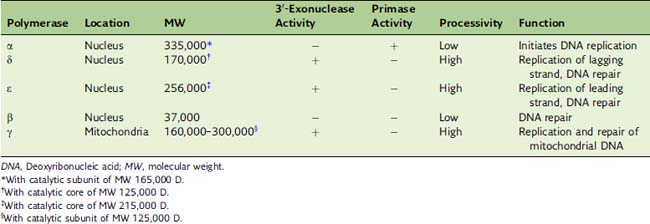
Eukaryotic DNA replication requires three DNA polymerases
In lagging strand synthesis, the primase is associated with DNA polymerase α. This composite enzyme synthesizes about 10 nucleotides of RNA primer followed by about 20 nucleotides of DNA, before relinquishing its product to DNA polymerase δ. Like its bacterial counterpart polymerase III, polymerase δ owes its high processivity to its association with a clamp protein that holds it on the DNA template (Fig. 7.4). The eukaryotic clamp protein is known as proliferating cell nuclear antigen (PCNA) because it was first identified in proliferating but not quiescent cells.
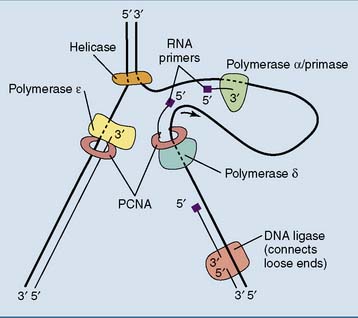
Eukaryotic Okazaki fragments are only 100 to 200 nucleotides long. When polymerase δ runs into the RNA primer of the preceding Okazaki fragment, the RNA primer is displaced from the DNA and removed by a nuclease, most commonly the flap endonuclease FEN1. Polymerase α has no proofreading 3′-exonuclease activity (Table 7.3), and its errors are most likely corrected by polymerase δ.
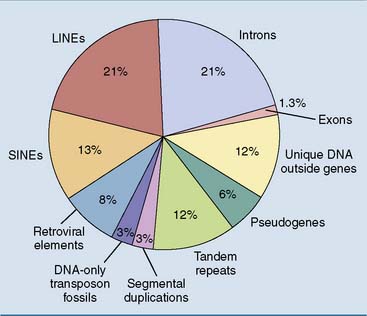
Most human DNA does not code for proteins
Human genes have between 1 and 178 exons, with an average of 8.8 exons and 7.8 introns. The average exon is about 145 base pairs long and codes for 48 amino acids, and the average polypeptide has a length of 440 amino acids. Introns are generally far longer than exons, and more than 90% of the DNA within genes belongs to introns (see Fig. 7.12 for an example).
However, the intron-exon structure of human genes is important for evolution. Different structural and functional domains of a polypeptide are often encoded by separate exons. For example, the immunoglobulin chains consist of several globular domains with similar amino acid sequence and tertiary structure, each encoded by its own exon (see Chapter 15). Immunoglobulin genes most likely arose by repeated exon duplication from a single-exon gene.
Figure 7.5 shows an overview of the composition of the human genome. One commentator wrote about the human genome: “In some ways it may resemble your garage/bedroom/refrigerator/life: highly individualistic, but unkempt; little evidence of organization; much accumulated clutter (referred to by the uninitiated as ‘junk’); virtually nothing ever discarded; and the few patently valuable items indiscriminately, apparently carelessly, scattered throughout.”
Gene families originate by gene duplication
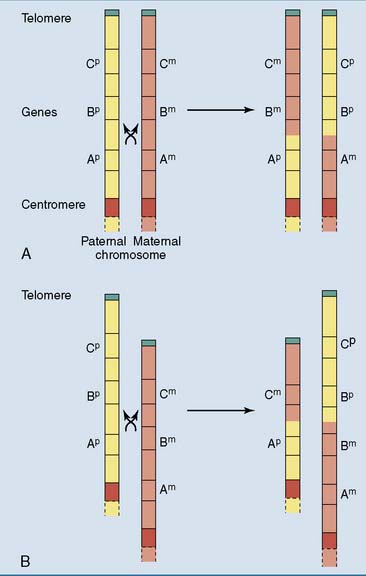
Gene families consist of two or more similar but not identical genes that, in most cases, are positioned close together on the chromosome. They arise during evolution by repeated gene duplications, mostly during crossing over in prophase of meiosis I when homologous chromosomes align in parallel and exchange DNA by homologous recombination. Normal crossing over is a strictly reciprocal process in which the chromosome neither gains nor loses genes. However, if the chromosomes are mispaired during crossing over, one chromosome acquires a deletion and the other a duplication (Fig. 7.6). Through new mutations, a duplicated gene can acquire new biological properties and functions.
The genome contains many tandem repeats
The length of tandem repeats is prone to change through mutation. Because most tandem repeats have no biological function (but see Clinical Example 7.2), the resulting length variations are innocuous and therefore are not removed by natural selection. They become part of normal genetic diversity and can be used for DNA fingerprinting and paternity testing.
Some DNA sequences are copies of functional RNAs
As the degenerate offspring of duplicated genes, pseudogenes still have the intron-exon structure of the functional gene from which they were derived. Processed pseudogenes are a different type of gene derivative. Processed pseudogenes consist only of exon sequences, with an oligo-A tract of 10 to 50 nucleotides at the 3′ end. This structure is framed by direct repeats of between 9 and 14 base pairs (Fig. 7.7).
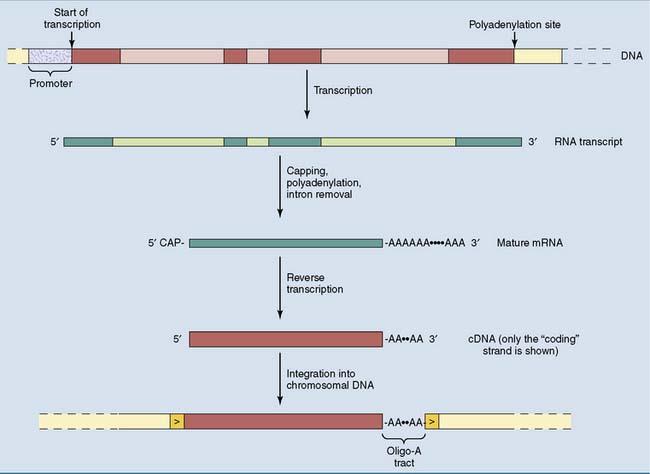
 , Exons;
, Exons;  , introns.
, introns.Processed pseudogenes arise during evolution by the reverse transcription of a cellular mRNA. The key enzyme in this process is reverse transcriptase, which transcribes the RNA into a complementary DNA (cDNA). The cDNA is then inserted into the genome by an integrase enzyme, which splices the cDNA into the genomic DNA. Enzymes with reverse transcriptase and integrase activities are encoded by retrotransposons in the human genome. These enzymes can also be introduced by infecting retroviruses (see Chapter 10).
Many repetitive DNA sequences are (or were) mobile
About 45% of the human genome consists of repetitive sequences with lengths of a few hundred to several thousand base pairs. They are not aligned in tandem but are scattered throughout the genome as interspersed elements (Table 7.5). These elements are repetitive because they can insert copies of themselves into new genomic locations. These mobile elements can be understood as molecular parasites that infest the human genome.
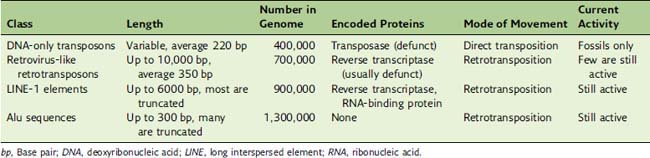
DNA transposons contain a gene for a transposase enzyme that is flanked by inverted repeats. The transposase catalyzes the duplication of the transposon and the insertion of a copy in a new genomic location (see Chapter 10). DNA transposons were active in the genomes of early primates, but in the human lineage they mutated into nonfunctionality approximately 30 million years ago. Only their molecular fossils can still be inspected.



