Chapter 2 Introduction to Protein Structure
Amino acids are zwitterions
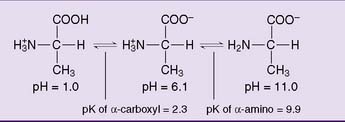
The pK of the α-carboxyl group is always close to 2.0, and the pK of the α-amino group is near 9 or 10. The protonation state varies with the pH (Fig. 2.1). At a pH below the pK of the carboxyl group, the amino acid is predominantly a cation; above the pK of the amino group, the amino acid is an anion; and between the two pK values, the amino acid is a zwitterion (from German zwitter meaning “hermaphrodite”), that is, a molecule carrying both a positive and a negative charge. The isoelectric point (pI) is defined as the pH value at which the number of positive charges equals the number of negative charges. For a simple amino acid such as alanine, the pI is halfway between the pK values of the two ionizable groups. Note that whereas the pK is the property of an individual ionizable group, the pI is a property of the whole molecule.
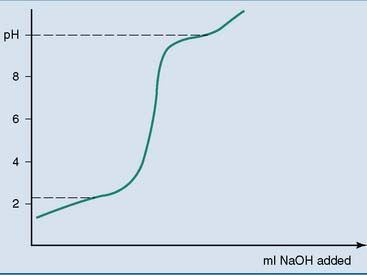
The pK values of the ionizable groups are revealed by treating an acidic solution of an amino acid with a strong base or by treating an alkaline solution with a strong acid. Any ionizable group stabilizes the pH at values close to its pK because it releases protons when the pH in its environment rises, and it absorbs protons when the pH falls. The titration curve shown in Figure 2.2 has two flat segments that indicate the pK values of the two ionizable groups. In the body, the ionizable groups of proteins and other biomolecules stabilize the pH of the body fluids.
The titration curves of amino acids that have an additional acidic or basic group in the side chain show three rather than two buffering areas. The pI of the acidic amino acids is halfway between the pK values of the two acidic groups, and the pI of the basic amino acids is halfway between the pK values of the two basic groups (Fig. 2.3).

Amino acid side chains form many noncovalent interactions
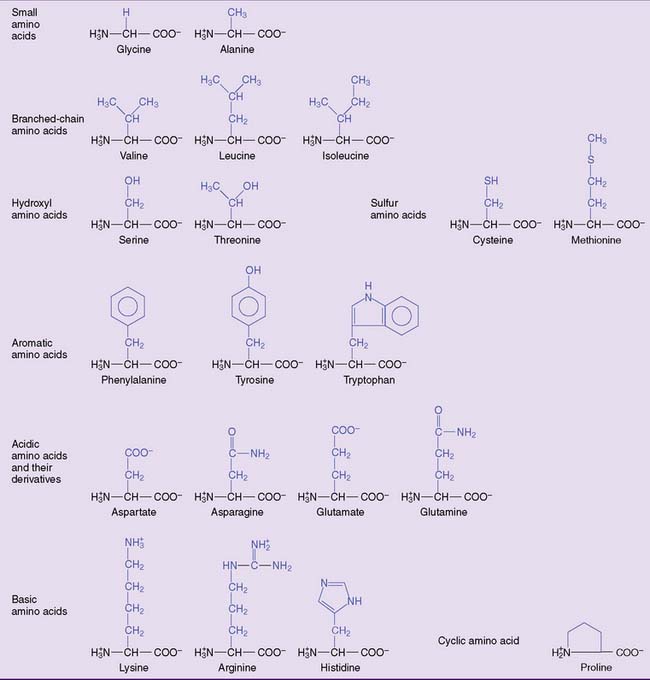
The 20 amino acids can be placed in a few major groups (Fig. 2.4). Their side chains form noncovalent interactions in the proteins, and some form covalent bonds:
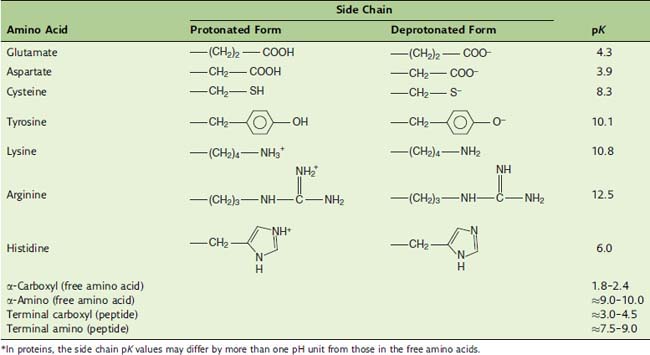
The pK values of the ionizable groups in amino acids and proteins are summarized in Table 2.1. Most negative charges in proteins are contributed by the side chains of glutamate and aspartate, and most positive charges are contributed by the side chains of lysine and arginine.
Peptide bonds and disulfide bonds form the primary structure of proteins
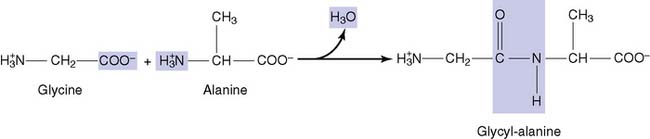
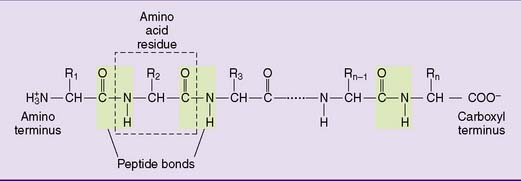
Adding more amino acids produces oligopeptides and finally polypeptides (Fig. 2.5). Each peptide has an amino terminus, conventionally written on the left side, and a carboxyl terminus, written on the right side. The peptide bond is not ionizable, but it can form hydrogen bonds. Therefore peptides and proteins tend to be water soluble.
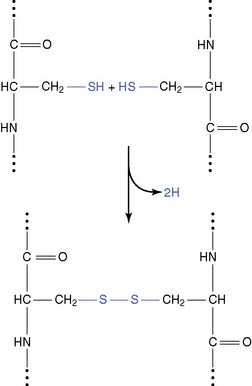
The enzymatic degradation of disulfide-containing proteins yields the amino acid cystine:
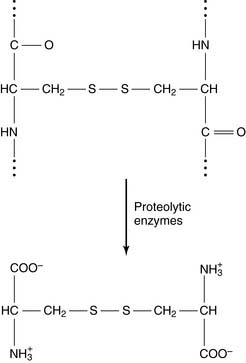
Proteins can fold themselves into many different shapes
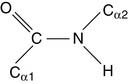
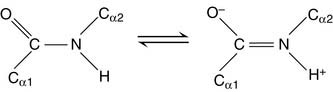
Its “real” structure is between these two extremes. One consequence is that, like C=C double bonds (see Chapters 12 and 23), the peptide bond does not rotate. Its four substituents are fixed in the same plane. The two α-carbons are in trans configuration, opposite each other.
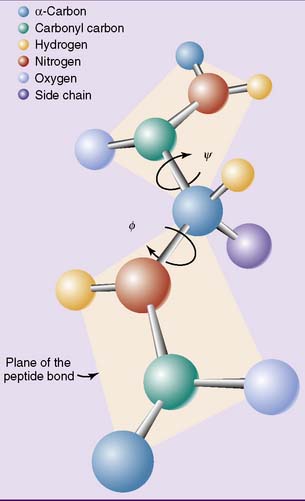
The other two bonds in the polypeptide backbone, those involving the α-carbon, are “pure” single bonds with the expected rotational freedom. Rotation around the nitrogen—α-carbon bond is measured as the Φ (phi) angle, and rotation around the peptide bond carbon—α-carbon bond as the ψ (psi) angle (Fig. 2.6). This rotational freedom turns the polypeptide into a contortionist that can bend and twist itself into many shapes.
Globular proteins have compact shapes. Most are water soluble, but some are embedded in cellular membranes or form supramolecular aggregates, such as the ribosomes. Hemoglobin and myoglobin (see Chapter 3), enzymes (see Chapter 4), membrane proteins (see Chapter 12), and plasma proteins (see Chapter 15) are globular proteins. Fibrous proteins are long and threadlike, and most serve structural functions. The keratins of hair, skin, and fingernails are fibrous proteins (see Chapter 13), as are the collagen and elastin of the extracellular matrix (see Chapter 14).
α-Helix and β-pleated sheet are the most common secondary structures in proteins
In the α-helix (Fig. 2.7), the polypeptide backbone forms a right-handed corkscrew. “Right-handed” refers to the direction of the turn: When the thumb of the right hand pushes along the helix axis, the flexed fingers describe the twist of the polypeptide. The threads of screws and bolts are right-handed, too. The α-helix is very compact. Each full turn has 3.6 amino acid residues, and each amino acid is advanced 1.5 angstrom units (Å) along the helix axis (1 Å = 10–1 nm = 10–4 μm = 10–7 mm). Therefore a complete turn advances by 3.6 × 1.5 = 5.4 Å, or 0.54 nm.

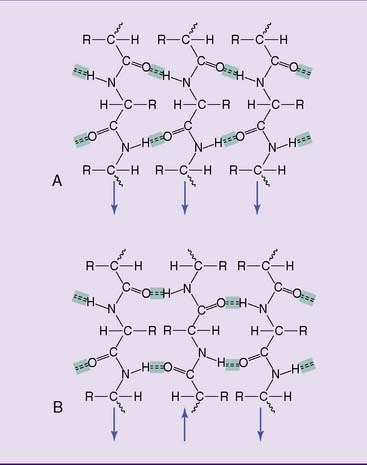
The β-pleated sheet (Fig. 2.8) is far more extended than the α helix, with each amino acid advancing by 3.5 Å. In this stretched-out structure, hydrogen bonds are formed between the peptide bond C—O and N—H groups of polypeptides that lie side by side. The interacting chains can be aligned either parallel or antiparallel, and they can belong either to different polypeptides or to different sections of the same polypeptide. Blanketlike structures are formed when more than two polypeptides participate. The α-helix and β-pleated sheet occur in both fibrous and globular proteins.
Globular proteins have a hydrophobic core
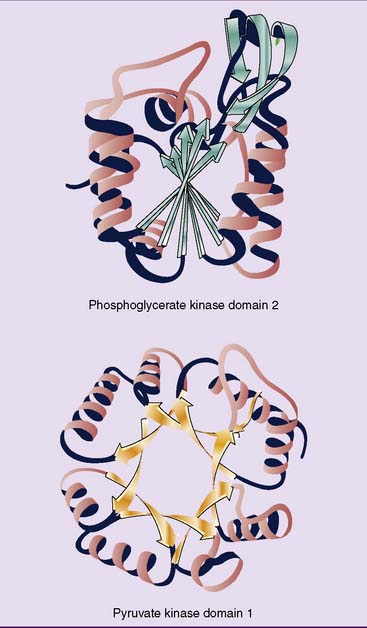
Many fibrous proteins contain long threads of α-helix or β-pleated sheets, but globular proteins fold themselves into a compact tertiary structure. Sections of secondary structure are short, usually less than 30 amino acids in length, and they alternate with irregularly folded sequences (Fig. 2.9). Unlike the α-helix and β-pleated sheet, tertiary structures are formed mainly by hydrophobic interactions between amino acid side chains. These amino acid side chains form a hydrophobic core.
Glycoproteins contain covalently bound carbohydrate, and phosphoproteins
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


