Chapter 6 DNA, RNA, and Protein Synthesis
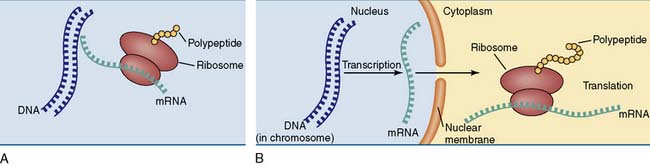
A typical human cell contains about 10,000 different proteins, which are synthesized according to instructions that are sent from the chromosome to the ribosome in the form of messenger ribonucleic acid (mRNA). Therefore gene expression requires two steps (Fig. 6.1):
All living organisms use DNA as their genetic databank
Differences between prokaryotes and eukaryotes are summarized in Figure 6.2 and Table 6.1. Despite these differences, all living cells have three features in common:
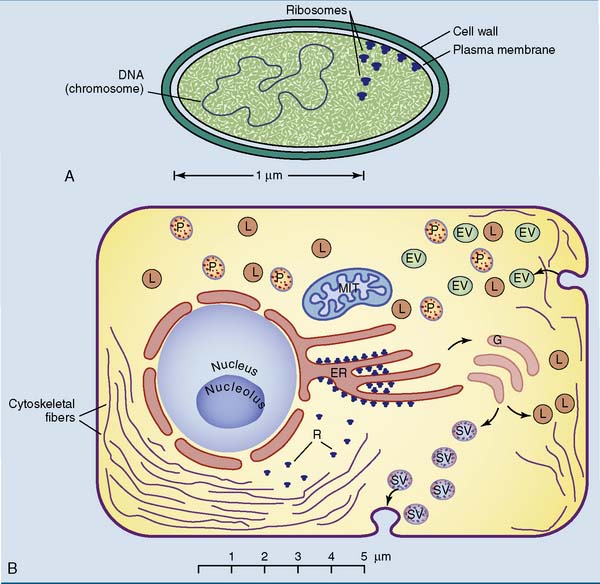
Table 6.1 Typical Differences between Prokaryotic and Eukaryotic Cells
| Property | Prokaryotes | Eukaryotes |
|---|---|---|
| Typical size | 0.4–4 μm | 5–50 μm |
| Nucleus | − | + |
| Membrane-bounded organelles | − | + |
| Cytoskeleton | − | + |
| Endocytosis and exocytosis | − | + |
| Cell wall | + (some −) | + (plants) |
| − (animals) | ||
| No. of chromosomes | 1 (+plasmids) | >1 |
| Ploidy | Haploid | Haploid or diploid |
| Histones | − | + |
| Introns | − | + |
| Ribosomes | 70S | 80S |
This chapter describes DNA replication and protein synthesis in prokaryotes. The corresponding processes in eukaryotes (see Chapter 7) are similar but are often more complex.
DNA contains four bases
DNA is a polymer of nucleoside monophosphates (also called nucleotides) (Fig. 6.3, B). Its structural backbone consists of alternating phosphate and 2-deoxyribose residues that are held together by phosphodiester bonds involving carbon-3 and carbon-5 of the sugar. Carbon-1 forms a β-N-glycosidic bond with one of the four bases shown in Figure 6.4.
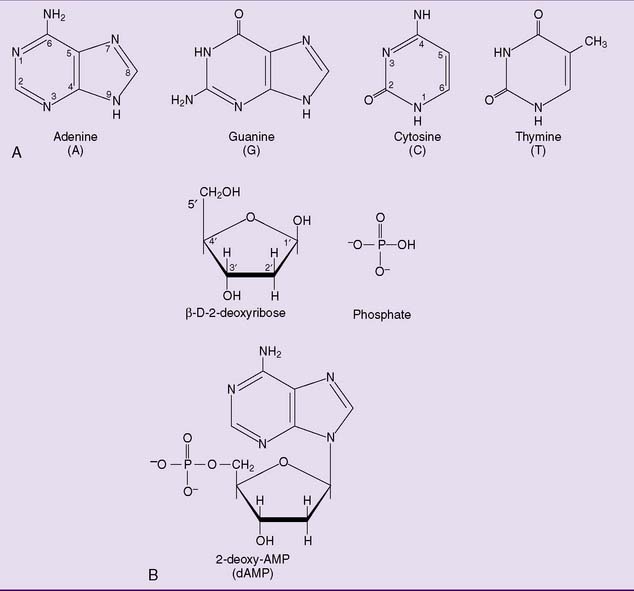
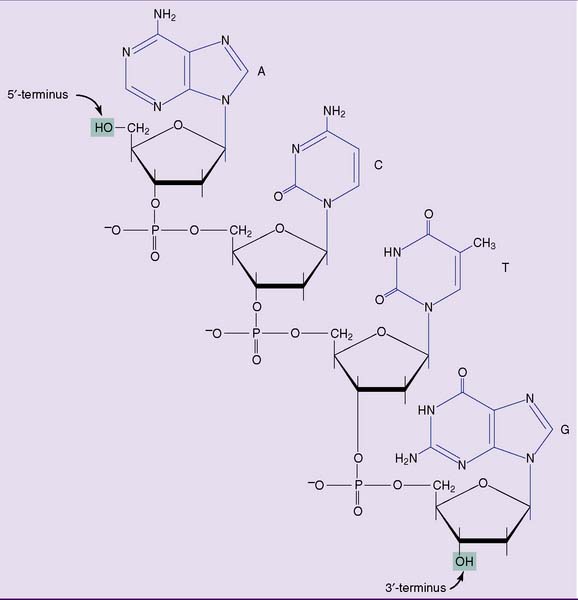
One end of the DNA strand has a free hydroxyl group at C-5 of the last 2-deoxyribose. The other end has a free hydroxyl group at C-3. The carbons of 2-deoxyribose are numbered by a prime (′) to distinguish them from the carbon and nitrogen atoms of the bases; therefore, each strand has a 5′ end and a 3′ end. By convention, the 5′ terminus of a DNA (or RNA) strand is written at the left end and the 3′ terminus at the right end. Thus the tetranucleotide in Figure 6.4 can be written as ACTG but not GTCA.
DNA forms a double helix
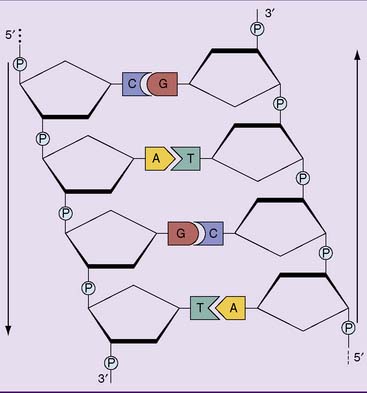
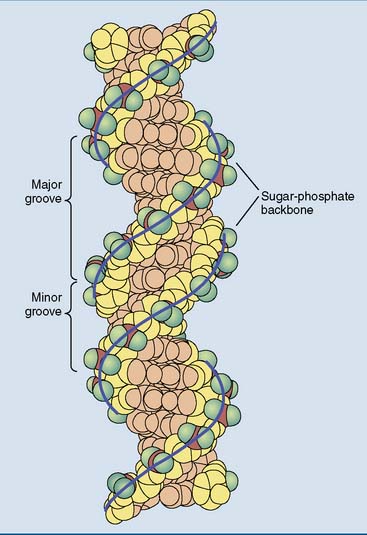
Cellular DNA is double stranded, and almost all of it is present as a double helix, as first described by James Watson and Francis Crick in 1953. The most prominent features of the Watson-Crick double helix (Figs. 6.5 to 6.7) are as follows:
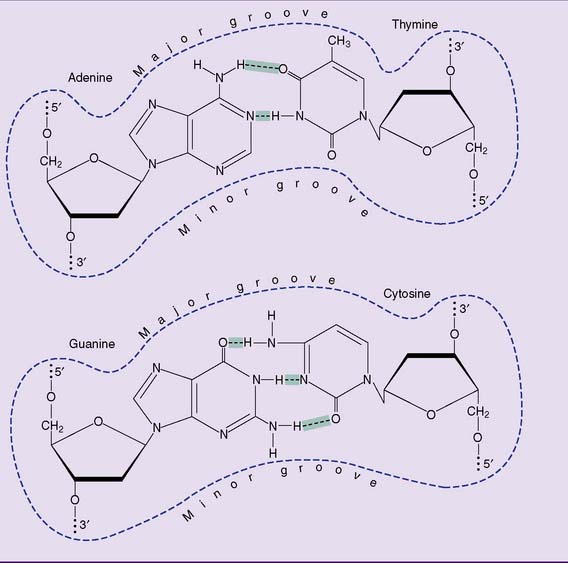
 ] and the G-C base pair by three.
] and the G-C base pair by three.DNA can be denatured
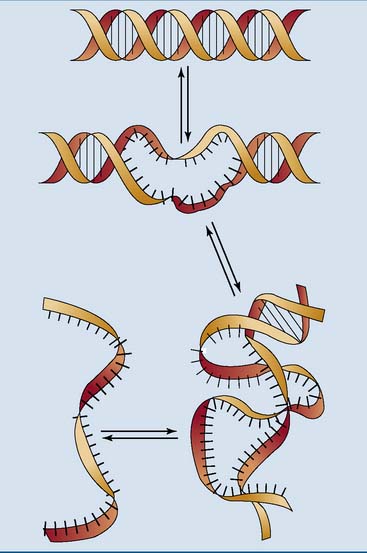
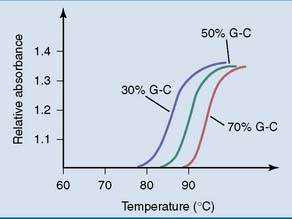
Like other noncovalent structures, the Watson-Crick double helix disintegrates at high temperatures. Heat denaturation of DNA is also called melting. Because A-T base pairs are held together by two hydrogen bonds and G-C base pairs by three, A-T–rich sections of the DNA unravel more easily than G-C–rich regions when the temperature is raised (Figs. 6.8 and 6.9). At physiological pH and ionic strength, this typically happens between 85°C and 95°C.
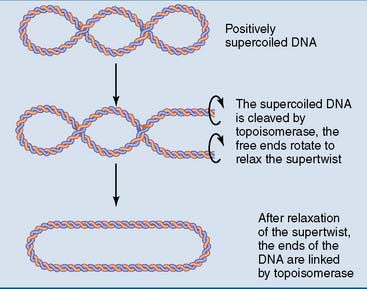
DNA is supercoiled
The supertwisting of DNA is regulated by two types of topoisomerase. Type I topoisomerases cleave one strand of the double helix, creating a molecular swivel that relaxes supertwists passively. Type II topoisomerases are more complex. They cleave both strands and allow an intact helix to pass through this transient double-strand break, before resealing the break. Type II topoisomerases hydrolyze ATP to pump negative supertwists into the DNA (Fig. 6.10).
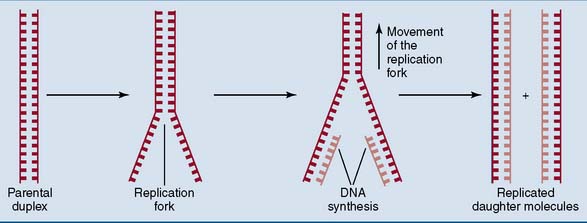
DNA replication is semiconservative
DNA is replicated in two steps (Fig. 6.11):
DNA is synthesized by DNA polymerases
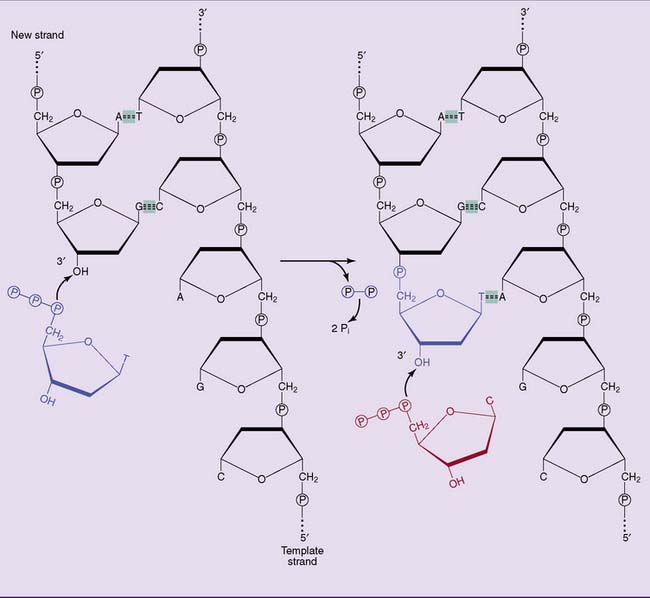
The key enzymes of DNA replication in E. coli, as in all other cells, are the DNA polymerases. DNA polymerases synthesize the new DNA strand stepwise, nucleotide by nucleotide, in the 5′→3′ direction. The precursors are the deoxyribonucleoside triphosphates: deoxy-adenosine triphosphate (dATP), deoxy-guanosine triphosphate (dGTP), deoxy-cytosine triphosphate (dCTP), and deoxy-thymidine triphosphate (dTTP). DNA polymerase elongates DNA strands by linking the proximal phosphate of an incoming nucleotide to the 3′-hydroxyl group at the end of the growing strand (Fig. 6.12). The pyrophosphate formed in this reaction is rapidly cleaved to inorganic phosphate by cellular pyrophosphatases.
Bacterial DNA polymerases have exonuclease activities
Nobody is perfect, and even DNA polymerase sometimes incorporates a wrong nucleotide in the new strand. This can create a lasting mutation, which can be deadly if it leads to the synthesis of a faulty protein. To minimize such mishaps, the bacterial DNA polymerases are equipped with a 3′-exonuclease activity that they use for proofreading. When the nucleotide that has been added to the 3′ end of a growing chain fails to pair with the base in the template strand, it is removed by the 3′-exonuclease activity (Fig. 6.13). This proofreading mechanism reduces the error rate from 1 in 104 or 1 in 105 to less than 1 in 107.
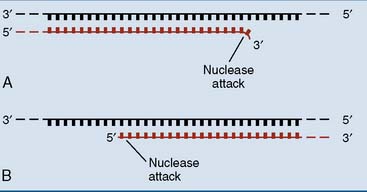
Most bacterial DNA polymerases also have a 5′-exonuclease activity (see Fig. 6.13). This activity is not used for proofreading, but it cleaves damaged DNA strands during DNA repair and erases the RNA primer during DNA replication.
Unwinding proteins present a single-stranded template to the DNA polymerases
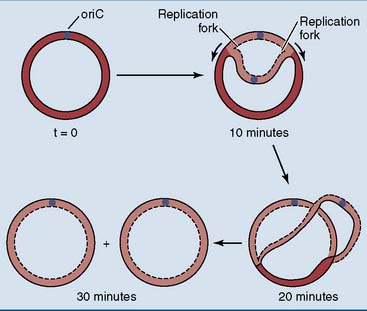
Escherichia coli has a single circular chromosome with 4.6 million base pairs and a length of 1.3 mm. This is 1000 times the diameter of the cell. The replication of this chromosome starts at a single site, known as oriC. The 245 base-pair sequence of oriC binds multiple copies of an initiator protein that triggers the unwinding of the double helix. This creates two replication forks that move in opposite directions. Unwinding and DNA synthesis proceed bidirectionally from oriC until the two replication forks meet at the opposite side of the chromosome (Fig. 6.14). The replication of the whole chromosome takes 30 to 40 minutes.
One of the new DNA strands is synthesized discontinuously
None of the known DNA polymerases can assemble the first nucleotides of a new chain. This task is left to primase (dnaG protein), a specialized RNA polymerase that is tightly associated with the dnaB helicase in the replication fork. Primase synthesizes a small piece of RNA, only about 10 nucleotides long. This small RNA, base paired with the DNA template strand, is the primer for poly III (Fig. 6.15, A).
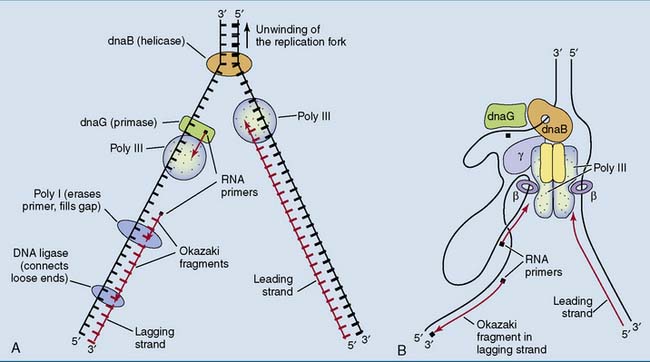
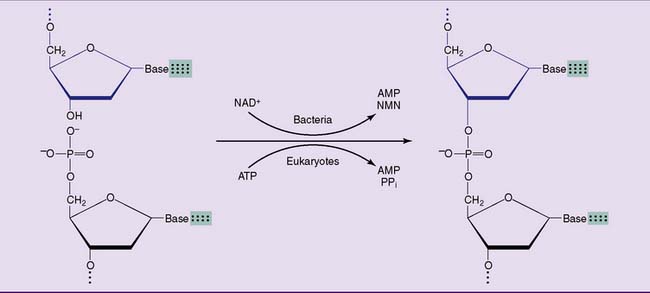
Poly I cannot connect the loose ends of two Okazaki fragments. This is the task of a DNA ligase, which links the phosphorylated 5′ terminus of one fragment with the free 3′ terminus of another. The hydrolysis of a phosphoanhydride bond in NADH (in bacteria) or ATP (in humans) is required for this reaction (Fig. 6.16).