chapter 21 Copying DNA, DNA damage and heritable disease
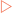
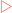
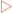
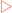
DNA is the molecule that stores the information that enables a cell to produce the many proteins and RNA it requires. This means that the fidelity of this information must remain high; otherwise the information will become scrambled and lost. Therefore, the cell invests time and effort to maintain the integrity of its DNA by protecting it against the many sources of damage and to repair it if such damage does occur. It also has to be able to faithfully copy the DNA to allow for growth, development and reproduction. There are many differences in these processes between prokaryotic and eukaryotic organisms, but this chapter focuses on the molecular mechanisms used in humans and other eukaryotic organisms.
DNA replication
The DNA present in the cell nucleus must occasionally be copied to allow cell division to occur. Mitotic division is employed to provide new cells for growth whereas meiotic division is used to produce gametes for reproduction. In the end it does not matter what the end product of the division is for, what matters is that the DNA is faithfully copied. This process, referred to as DNA replication, involves the use of many enzymes and other proteins, and has many checks and balances to ensure a true copy is made. For copying to occur the cell separates the two strands in each double-stranded molecule, and uses them as templates to synthesise complementary strands. Thus, at the end of replication each double-stranded molecule consists of one parent strand hydrogen-bonded to a new daughter strand (Fig 21-1), a process termed semi-conservative replication.
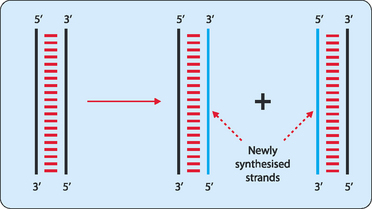
The copying process begins at special sequences on each DNA strand referred to as origins of replication. In bacteria the circular chromosome that each cell contains has a single origin of replication whereas the many linear chromosomes in eukaryotic cells have many hundreds of origins. To initiate replication specific proteins recognise and bind to the origins of replication, and force the two strands of DNA apart—a process known as denaturation. This produces a replication ‘bubble’ which allows replication to spread in each direction from the bubble until the entire molecule has been copied (Fig 21-2).
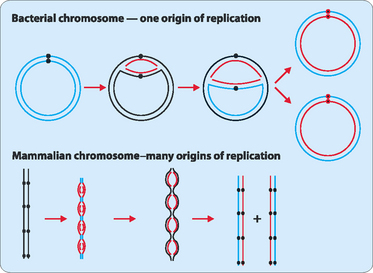
Each side of the replication bubble is called the replication fork, where the two DNA strands are being continuously unwound and separated (Fig 21-3). This is carried out by enzymes called DNA helicases. Once separated, molecules of replication protein A (RPA) adhere to the DNA strands to stabilise them. If RPA did not bind then the two DNA strands would reanneal and be useless as templates for replication. One other enzyme involved in the process is topoisomerase which helps to relieve the strain induced in the double-stranded DNA by the unwinding process by breaking and then rejoining the DNA ahead of the replication fork (Fig 21-4).
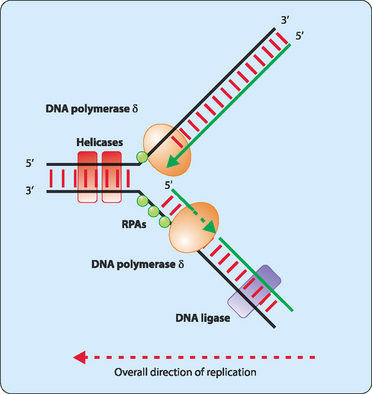
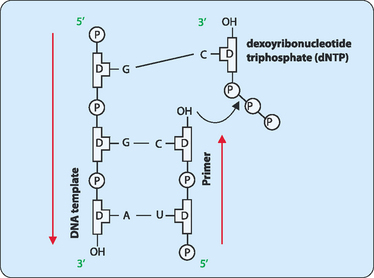
The unwound sections of DNA can now act as templates for the synthesis of new complementary strands. For this synthesis to occur a short stretch of RNA which is referred to as a primer is synthesised by the enzyme primase. Initially primase adds a single ribonucleotide complementary to the DNA template, which is held in place by base-pairing with template. Primase then successively adds ribonucleotides until a stretch of 5–10 residues has been made. The enzymes involved in synthesising the new DNA strand now have a starting point and add deoxyribonucleotides to the 3′ end of the primer. These enzymes are called DNA polymerases, with up to 11 so far identified in eukaryotic cells. The main polymerase involved in replication is DNA pol δ, but all the enzymes act in a similar manner. DNA pol δ adds single nucleotides complementary to those on the template DNA using nucleotide triphosphates. As each nucleotide becomes incorporated into the new strand the terminal two phosphates are removed as a pyrophosphate group which is later hydrolysed to two phosphates (Fig 21-5).
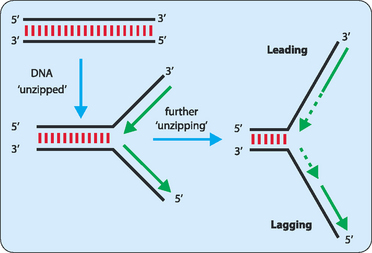
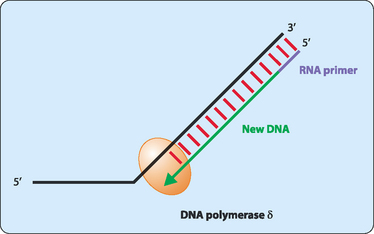
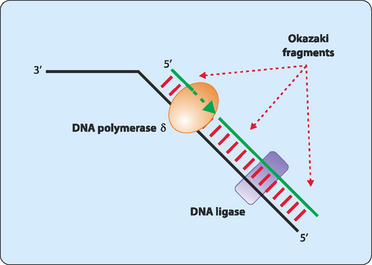
DNA synthesis proceeds only in a 5′ to 3′ direction. In a double-stranded DNA molecule the two strands are oriented antiparallel to each other. This means that replication occurs differently on each strand. One strand, referred to as the leading strand, can have its complementary strand synthesised in a continuous manner (Fig 21-6). DNA polymerase cannot synthesise the other lagging strand in the same manner. Instead, the lagging strand is synthesised in small fragments in a discontinuous manner (Fig 21-7). The discontinuous nature of replication on this strand requires many primers which are then elongated in eukaryotes to produce fragments 100–200 nucleotides long that are referred to as Okazaki fragments.
Sources of DNA damage
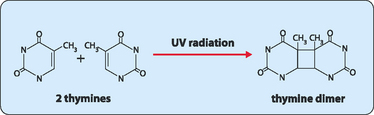
DNA is constantly exposed to harmful chemical and physical agents. Reactive chemicals, from the environment or cellular metabolism, and radiation such as ultraviolet rays or x-rays, can interact with the bases in DNA to alter their base-pairing characteristics. However, these changes are normally detected and repaired before they become ensconced as mutations and perpetuated. Generally the repair procedure involves an endonuclease, an enzyme that removes a section of the strand containing the damaged nucleotide so that it can be replaced with appropriate nucleotides using the undamaged strand as a template by DNA polymerase and DNA ligase. One common type of damage repaired by this excision repair process occurs in skin cells exposed to sunlight. In these cells UV radiation interacts with adjacent thymidines to form a thymidine dimer (Fig 21-8). These dimers need to be repaired or they can cause mutations which can lead to skin cancer. More profound damage can occur to DNA when it encounters ionising radiation. Low exposure to ionising radiation can cause irreparable DNA damage to the bases, leading to errors in replication and transcription that may cause premature ageing and cancer. Higher doses of radiation can lead to breaks in one or both of the DNA strands in the double helix. These breaks are dangerous to cells as they can lead to chromosomal rearrangements. Single-stranded breaks are repaired by direct ligation or by excision repair. Cells have a specialised enzyme system to recognise and repair double-stranded breaks but they are not always successful.
When proofreading fails
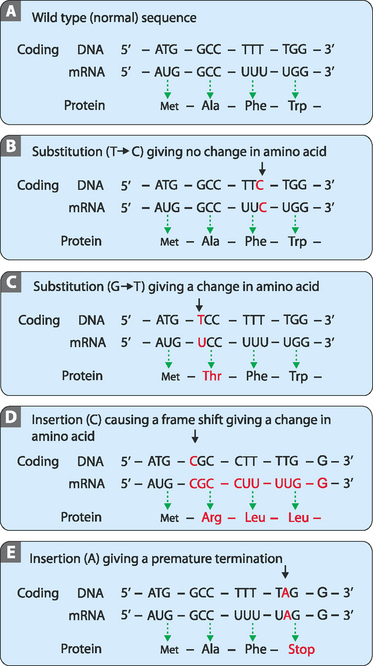
Genetic information, as described in the previous chapter, is relatively resistant to mutational changes due to the inbuilt degeneracy of the genetic code. A sequence that codes for a short peptide can be used to illustrate the effect, or lack of effect, of various mutations (Fig 21-9A). The degeneracy of the genetic code acts to preserve stored information because it is possible to change the sequence (codon) without affecting the amino acid inserted into the peptide. This is because many amino acids have more than one codon which directs their insertion into the peptide. In these cases the codons are usually closely related in their sequences, often being one base different from each other. This type of mutation is referred to as a substitution. One variety of this mutation is a silent or synonymous mutation (Fig 21-9B). It is a mutation in that it changes the sequence of the DNA from the wild type but does not affect the amino acid inserted into the peptide (the phenotype).