chapter 5 Amino acids and proteins
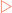
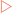
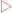
Proteins are the most abundant (usually greater than 50% of the dry weight of most cells) and functionally diverse cellular components, with the vast majority of important life processes being dependent on them. Indeed, the importance of proteins is reflected by their name, which is derived from the Greek word ‘proteios’ which means ‘first placed’. This and other chapters demonstrate that while proteins display an incredible diversity of function they all share the structural feature of being polymers of amino acids.
Amino acids
There are over 300 naturally occurring molecules that can be classified as amino acids. In this chapter the focus will be on the 20 which are commonly found in mammalian proteins. All amino acids except proline (see below) have a carboxyl group, an amino group and a defined side chain attached to a central α-carbon atom (Fig 5-1). At physiological pH (pH ≈︀ 7.4) the carboxyl group is fully dissociated to form a negatively charged carboxylate ion (–COO−) whereas the amino group remains protonated (–NH3+). When amino acids are present in proteins the majority of these carboxyl and amino groups are used to form peptide bonds and become largely unreactive. However, there is one component of each amino acid that is not used in peptide bond formation, namely the side chain, which remains reactive. This means that it is the nature of these side chains which ultimately determines both the position of the amino acid in a protein and the protein’s functionality.
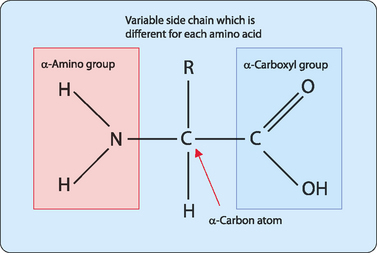
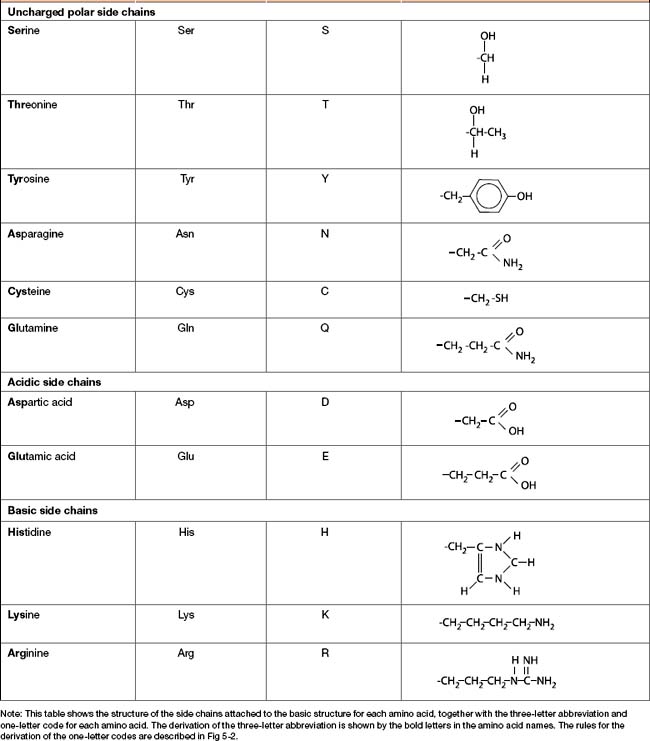
Amino acids can be divided into four main groups (Table 5-1) based on the chemical characteristics of their side chains: nonpolar, uncharged polar, acidic and basic.
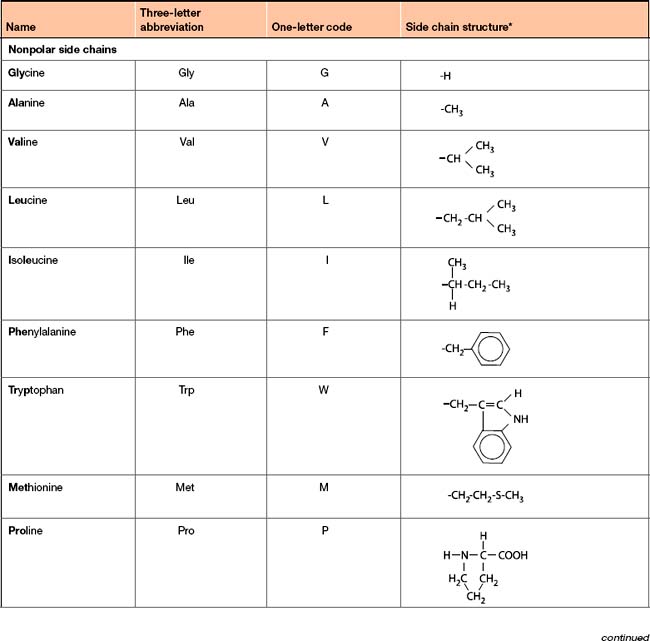
Abbreviations and symbols for amino acids
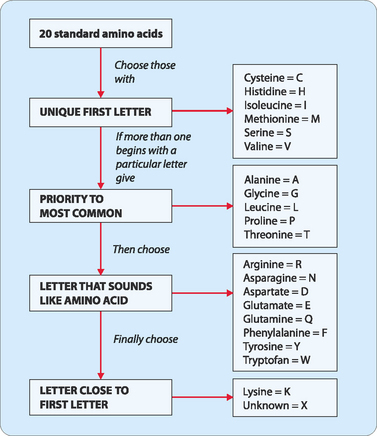
Each amino acid has an associated three-letter abbreviation and a one-letter code. The derivation of the three-letter abbreviation is shown in the accompanying table (Table 5-1). The one-letter codes were determined by the application of a set of naming rules (Fig 5-2).
Amino acid optical isomers
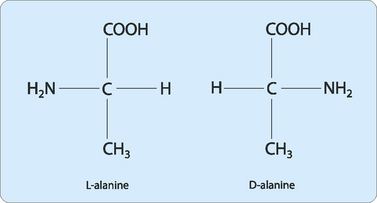
The α-carbon of each amino acid is attached to four different chemical groups and is therefore a chiral carbon. The exception to this is glycine where the α-carbon is not chiral since two of its substituents are single hydrogen atoms. Amino acids with a chiral α-carbon can exist in two forms that are a mirror image of each other (Fig 5-3) such that their three-dimensional structures are not superimposable. These pairs of forms are termed stereoisomers, optical isomers or enantiomers. Optical isomerism occurs when one of a pair of isomers rotates plane-polarised light in the opposite direction from the other. Molecules that are capable of optical isomerism must have at least one chiral centre. One of each pair is designated the D and one the L configuration by comparison with the structures of the isomers of glyceraldehyde, one of the smallest commonly used chiral molecules. Only L isomers of amino acids are found in mammalian proteins.
Polypeptides
Peptide bonds
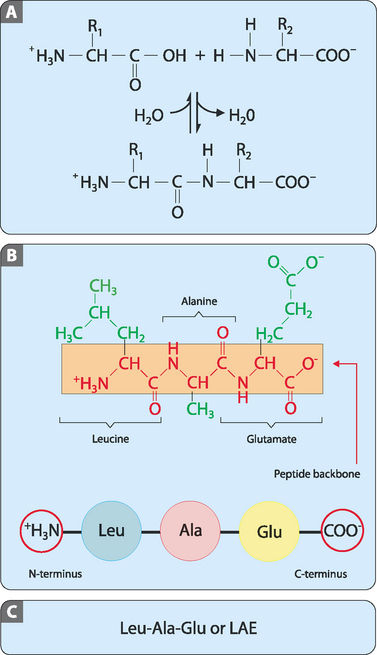
Polypeptides are constructed by covalently joining amino acids via a series of condensation reactions (when two molecules combine to form a single molecule, together with the loss of a small molecule) that occur in a cellular structure known as the ribosome (see Ch 9). These reactions can occur when the α-carboxyl group of one amino acid is close to the α-amino group of another. A dehydration reaction (when two molecules combine to form one single molecule, together with the loss of water) then occurs and the resulting covalent bond is termed a peptide bond (Fig 5-4A). This process is repeated sequentially until the required number of amino acids is covalently joined in a linear polymer. The amino and carboxyl groups on the side chains are not involved in the formation of polypeptides. At one end of the polypeptide there is a free α-carboxyl group (the C-terminus) and at the other end is a free α-amino group (the N-terminus). By following the atoms from the free terminal carboxyl directly along the chain to the free terminal amino group it can be seen that there is a repeating sequence of C, C and N atoms (Fig 5-4B). This part of the polypeptide is often referred to as the backbone. This backbone is common to all peptides such that it is the nature of the amino acid side chains that extend from it that differentiate polypeptides and determine their structure and functions. The length of polypeptides can vary from a few residues (e.g. peptide hormones) to over a thousand (e.g. complex proteins). However, the polypeptide chains of a specific protein all have the same set sequence of amino acids which is different from that of other proteins. This is referred to as the primary structure of the polypeptide. This means that a cell can use a limited set of amino acids to produce polypeptides of varying length and primary structure that can carry out a diverse array of roles.