Information Management
Information and data are the coins of the drug discovery and development realm.
–Bert Spilker
No amount of sophistication is going to allay the fact that all your knowledge is about the past and all your decisions are about the future.
–Ian E. Wilson
The traditional view of knowledge management primarily focuses on information, whereas the knowledge ecology adds the context, synergy and trust necessary for translating such information into actionable knowledge.
–Yogesh Malhotra
TYPES OF INFORMATION IN A PHARMACEUTICAL COMPANY
Pharmaceutical companies are extremely information-intensive enterprises. A large quantity of information is obtained from external sources and is also generated internally throughout discovery, development, manufacturing, and marketing groups. Information is systematically recorded and stored for easy retrieval to support each product’s survival, from its conception through its life in the market.
While information exists in every aspect of a company, this chapter focuses on drug development activities. Information generally falls into the following categories.
Raw Data
Raw data are the observations, measurements, and assessments recorded by investigators, coordinators, ancillary personnel, study subjects or their surrogates during the course of a clinical study. Raw data may be quantitative or qualitative; it may represent physiological values or psychological scores, and be recorded as images, sounds, waveforms, genetic maps, and many other ways relevant to evaluating the safety and efficacy of a new product. Raw data are the foundational elements from which all subsequent analyses, graphs, figures, and tables are derived. Raw data may be difficult to manage due to large volumes, disparate formats, and the multitude of ways in which they are collected and entered into an information system. However, as the basis for all subsequent information flows and knowledge development, raw data should be handled as the core lifeblood of a development program. Previous chapters have focused on the collection of raw data via case report forms or electronic data capture systems. The storage and retrieval of raw data is not the focus of this chapter.
Analyzed Data
Analyzed data are the descriptive, statistical, and graphical aggregation of raw data that enables scientific and business experts to make meaningful interpretations and conclusions. Analyzed data are derived from raw data, using logical principles such as hypothesis testing and data visualization. The intent of analyzed data is to make evident inferences and conclusions which are justified based on the raw data. Data analysis can be both illuminating and misleading. A carefully constructed analysis can reveal relationships and conclusions not apparent from a large mass of disconnected raw data. A poorly constructed or purposefully misleading analysis can obfuscate and/or lead to erroneous conclusions. Analyzed data are the product of careful planning as expressed in the protocol document, following well-known principles of scientific evaluation and hypothesis testing.
External Company Documents
Books, journals, and conference proceedings are one key source of publicly available scientific or technical information for authored scientists not employed by the pharmaceutical company. This class of information is housed in company paper and electronic libraries, which meet most basic information needs of employees. Access to the published literature and various databases is facilitated by many computerized online bibliographic and other databases. These online databases classify these documents using standardized terms which attempt to describe the key topics addressed by the documents. The ability to locate appropriate external documents is tied directly to the richness and specificity of these indexing terms. Most of the cost of acquiring or licensing these online databases is due to the process of reading, abstracting and indexing the external literature.
Unlike the technical/scientific literature, documents which describe company products require special attention. Articles from the worldwide biomedical literature must be gathered, analyzed, indexed, and entered into in-house, online computer databases to make information rapidly available. As with public document databases, a rich set of terms for indexing these documents is critical for users to be able to locate the desired document at a later time. As described in the following text, this indexing effort represents a significant cost to the company that can only be done by knowledgeable (therefore expensive) document management librarians or curators who must read the articles and apply the correct terms in a uniform manner. Without this effort, documents stored in an information system will “disappear” into a black hole, frustrating users who later attempt to locate an article that they know has been entered into the system.
In-house Company Documents
These include a wide variety of meeting minutes, reports, analyses, regulatory submissions, archives supporting Good Manufacturing Practices and Good Laboratory Practices procedures, litigation records, and other material. These are usually kept in one or more document repositories, and many documents are recorded in machine-readable form. Automated optical character recognition with full-text indexing (a la Google) and key terms indexing (a la Medline) are applied to these documents to facilitate rapid retrieval via computer searches. To condense data and to enable access to large quantities of old data and reports, electronic methods have almost entirely replaced microfiche and microfilm methods. Optical storage facilities on laser disks had been used by an increasing number of companies for long-term archival storage, whereas magnetic storage is almost exclusively used for access to more current documents. Developing a document storage strategy that balances the costs, stability, and access differences in archival versus action document storage is an important component of a company’s information technology infrastructure strategy.
A key technical issue has been the rapid obsolescence of storage technologies. Companies may need to archive information for 20 or more years. Over that period of time, the industry has witnessed the rise and fall of nine-track magnetic tape, removable Winchester disk platters, 8-inch floppy disks, 3.5-inch hard disks, ZIP drives, and CD-Roms. With each innovation in storage, the previous technology becomes obsolete. Hardware and software support for accessing and understanding the information on these devices diminishes quickly as the technical marketplace moves on. Given the constant push for replacing archival technologies by manufacturers, it is a “battle” by companies seeking to maintain large amounts of data in forms that will not go out of date rapidly and do not frequently need to be upgraded to the next technology. For devices which depend on proprietary formats, the disappearance of the technology company can result in the complete loss of access to the data. Hence, a recent strong push has developed for open, nonproprietary standards for data storage.
Laboratory Notebooks
Until recently, arguably the most important set of documents, created by the internal scientists doing basic drug discovery, were completely paper-based and, therefore, inaccessible via electronic
document management systems. These laboratory notebooks capture, in detail, the processes used to create, validate, and screen the next potential blockbuster drug. They also are keys to any subsequent patent or intellectual property activities. New products, called electronic notebooks, are now available which enable scientists to enter detailed information regarding their activities. Unlike paper lab notebooks, the information entered into electronic notebooks can be included in a company’s document management system.
document management systems. These laboratory notebooks capture, in detail, the processes used to create, validate, and screen the next potential blockbuster drug. They also are keys to any subsequent patent or intellectual property activities. New products, called electronic notebooks, are now available which enable scientists to enter detailed information regarding their activities. Unlike paper lab notebooks, the information entered into electronic notebooks can be included in a company’s document management system.
Information on Chemicals Synthesized
Records may contain a great deal of information beyond the chemical structure and its physical properties, such as amounts synthesized in each batch, amounts remaining from each batch, physical locations where the material resides, and specific chemical and biological test results obtained with the material. Data about chemicals used as raw materials often may be purchased electronically from manufacturers or may be obtained online.
Regulatory Documents
Although considered part of a company’s internal documents, these documents have special requirements, such as audit trails, sign-offs, and locking down final versions of the documents, that are actually submitted to the regulatory agency. Although the information contained in these documents generally can be found within other company documents (e.g., clinical trial study reports or toxicology reports), these documents repackage this information following regulatory requirements. Therefore, these documents must be stored as separate entities, even if no new information is contained within them. Often, regulatory documents have unique archival requirements, often being maintained for much longer than many of the other documents stored related to a compound’s development.
Media References to the Company’s Products
These documents can be organized by product and will contain newspaper, news magazine, and other media references. These documents may be electronic or scanned images. As with all documents, indexing strategies are key to enabling future users the ability to locate these documents. This folder may be started when a compound is first tested in humans, passes an efficacy go-no-go decision point, or is marketed. Electronic or paper clipping news and marketing services may be used, not only for hard copy text, but to provide written verbatim texts of radio and television reports, as well as DVDs if available.
Internet Sources of Information
More recently, the Internet has emerged as an important source of external references to a company’s products. Newgroups, listservs, and most recently, blog sites have exploded as additional forums in which a company’s products are praised or disparaged. An entirely new industry has emerged that “trolls” these new Internet sites for comments posted about a company and its products.
Competitive Intelligence
Relevant information may be collected on the competitors’ activities, status of competitive drugs, size and nature of relevant markets, trends in those markets, plus any other useful information. It is easy to collect huge amounts of data on most competitors’ drugs. The challenge for any company is to keep this file limited to the true essentials and to update the material periodically so that it remains current. This is usually too expensive or too arduous a task to perform on any but the most important products of the competitors. Rather than use this approach at all, most companies run searches on external databases as the need arises. Addressing selected questions and focusing on specific topics are two methods that may be used to accomplish a company’s goals. Chapter 24 discusses this in greater detail.
FLOW OF INFORMATION
Figure 100.1 illustrates general ways of visualizing the flow of information. Many variations of this flow exist depending on the type and uses of information involved. This figure is a simplified theoretical approach illustrating the steps involved. The initial step of identifying the information needed is not shown. The real situation is usually much more complex, primarily owing to numerous feedback loops and cycles that occur among different stages in this scheme.
A few of the many types of considerations and aspects associated with each stage are described.
Obtaining Information
Information comes from scientific, clinical, and other experiments; sales data; production information; and many other sources both within and external to the company. The Internet has become an essential source of information. Information arrives electronically, verbally, and/or in hard copy. Information may be in text reports, slide presentations, video or audio clips, or combinations of these media types.
Confirming the Accuracy of Information
This may involve editing information via various means. Computer programs may be able to check the accuracy of some scientific data, raising “flags” when data are outside preset limits or have internal inconsistencies. Artificial intelligence is emerging as an important technology that has been applied to the accuracy or plausibility of information. Despite efforts to modernize, most pharmaceutical companies still use a substantial amount of manual labor in reviewing and checking raw data, particularly clinical data. Reviewing and annotating more complex sources of information are also very labor intensive.
Organizing and Categorizing Information
As described previously in this chapter, information must be categorized and organized by knowledgeable people prior to being processed and indexed. A variety of systems may be used to classify the information. The two major types are a classification based on the contents of the information itself that is to be categorized, and the other is a classification based on the needs and interests of the group for whom the information has been collected. Rich standardized vocabularies which provide terms that allow indexers to capture meaningful distinctions are critical to retrieving just the right documents at a later time. Correctly indexing documents represents a significant information management cost. Full-text
search, similar to the searching capabilities of Google, can be a cheap alternative in some settings, especially if key documents contain unique terms not found in other documents. This important feature is likely to be found in most drug development documents. Hence, full-text document indexing may prove to be a very useful tool for document management.
search, similar to the searching capabilities of Google, can be a cheap alternative in some settings, especially if key documents contain unique terms not found in other documents. This important feature is likely to be found in most drug development documents. Hence, full-text document indexing may prove to be a very useful tool for document management.
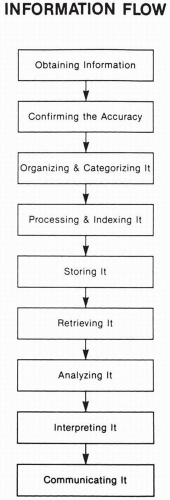 Figure 100.1 Prototype pattern of how information usually flows from the time it is obtained. These steps occur after the specific information needed is identified and a plan is developed and implemented to collect the information. Numerous variations exist on the order of steps followed in specific situations. |
Processing and Indexing Information
Processing information involves putting it into a computer (photographing it on microfiche or microfilm are rarely done anymore) and indexing it for eventual retrieval. The data must be processed so that the company retains the ability to combine and/or analyze it efficiently at the present time or at a later date.
Two quite different approaches may be followed in indexing articles for later identification and retrieval. One approach puts significant effort into indexing articles in detail prior to any request for their contents. Then, when a search of the database is run, only the most relevant articles will be identified and the requester has less bulk to deal with. Another approach is to index articles more superficially to save time for the indexing staff. The potential problem that arises using this approach is that when a request is made a large amount of material may be identified and must be sorted through to find the most relevant documents.
The choice of a preferred approach depends, at least in part, on the salaries and levels of the people who have to index the material and those who must winnow down the output. Available funds are also an important factor.
Storing Information
Information may be stored as hard copy and electronically scanned into a computer, may be stored in its native electronic file format, or may be converted into another format (e.g., PDF). Each of these methods has particular features that make it desirable for use in active files, archival files, or files that have both functions. Specific systems and equipment are usually purchased based on a myriad of factors, including those listed in Table 102.3. This table does not list various general criteria such as servicing, number of units sold, availability, reliability of the equipment, and so on. Companies usually have a backup system for protection and storage, and at the minimum, store important information in at least two geographically separate locations.
Retrieving Information
It is essential to separate the topics of information storage and retrieval because the procedures used for each can be quite different. Different types of access to data exist (e.g., physical access and logical access). These types of access and other related topics are discussed by Blair (1984). Information is usually indexed with key terms to make it easier to retrieve. The same report would tend to be indexed differently by different people. Thus, a variety of indexing terms usually need to be searched to obtain a broad coverage of topics. As a result, nonexperts are usually unable to identify all ot the reports on complex questions. Therefore, skilled information scientists are necessary to retrieve relatively complete outputs or listings of a topic. As previously described, full-text indexing has emerged as a possible replacement to expensive indexing methods. The characteristics of drug development documents make them particularly amenable to this much less expensive approach.
A critical issue about retrieval sometimes concerns classifying people to determine which groups have the right to access stored information. A common question is whether the person who is requesting data or a report has a desire or a need to know the information. For particularly sensitive documents, access restrictions can be applied. One of the key advantages of electronic retrieval systems over paper-based systems is that detailed logs can capture every query and every document retrieval by all system users.
Analyzing Information
This may be done by many techniques varying from casual observation to formal statistical analyses. Analysis often means selecting, combining, or organizing the information into tables or figures so that it may subsequently be interpreted. One key feature of this step is capturing the assumptions made and the methods used when data or information are combined. Quite often, the assumptions are critical to understanding the limitations of subsequent interpretations. When the assumptions and methods get separated from the analysis, later attempts to interpret the information may lead to unsupportable conclusions.
Interpreting Information
The meaning of the information is gleaned using the analyses as the basis of the interpretation. After the interpretation is made, it may be extrapolated to other situations. Several chapters in this book discuss interpretation of data and this is covered in greater detail in Guide to Clinical Trials (Spilker 1991).
Communicating Information
Information must be effectively communicated to achieve its appropriate and full impact. If all of the steps mentioned earlier are conducted, but the results are either not communicated or are not communicated well, then most of the value in the exercise shown in Steps 1 to 8 of Fig. 100.1 may be lost. The transfer of information may be between people or machines (Fig. 100.2). As mentioned above, it is critical that the assumptions made and methods used to analyze and interpret the information be included in the communications. Otherwise, other consumers of the information could easily reach conclusions that are not valid, thus making the entire effort in Steps 1 to 8 not only useless, but potentially dangerous.
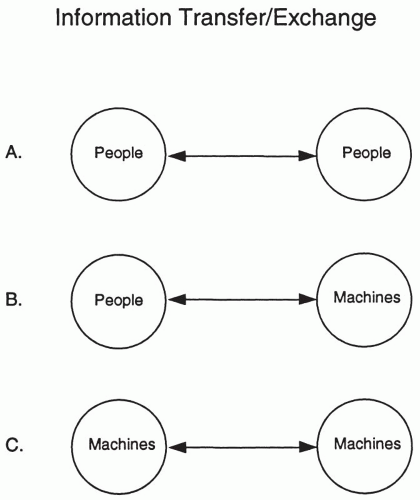 Figure 100.2 The relative amount of information transfer is increasingly occurring between people and machines (Panel B) and also between machines (Panel C). |
DATA MINING
After spending many hours reading several dozen articles and reviews on data mining, the question crossed the author’s mind of how much of this information do drug discovery and development students and professionals need to know, or would they want to know? Of course, the answer depends on the interests and responsibilities of the people involved, as well as other factors. However, an awareness of this technique’s potential and its range of uses might help a professional determine if he could take advantage of this methodology. It would also assist a student in learning how to proceed further to explore this area. This section presents a general overview that an average student or professional who is not knowledgeable about data mining might wish to understand.
What Is Data Mining?
Data mining is defined as “the application of statistical methods to large databases with the objective of discovering new information” (Stephenson and Hauben 2007). It is a process that is primarily applied to the literature (and other documentation) to learn what has been reported, and is also applied to large databases with data to search (e.g., genomic and proteomic databases, high throughput screening databases) with the hope or expectation of finding an answer to a question/problem or to help develop a hypothesis. Although there are various algorithms used in the mining, Obenshain (2004) describes mining as a process rather than a set of tools. She mentions five stages that are involved in data mining:
Sample—to draw a statistically representative sample of data from the database
Explore—to apply exploratory and statistical and visualization techniques
Modify (or manipulate)—to select and transform the most significant predictive variables
Model—to model the variables to predict outcomes
Assess—to confirm a model’s accuracy
Note that these steps can be performed iteratively with the goal of being able to turn the data to information, and one hopes eventually into knowledge.
Methods of Data Mining
Castellani and Castellani (2003) present a straightforward yet detailed analysis of the data mining process using health data. They discuss the self-organizing map and decision tree analysis approaches, which are too technical to discuss in this overview. References to other algorithms that are used in data mining are mentioned in the clinical section in the following text.
Several reviews (Boyack 2004; Natarajan et al. 2005; Roberts 2006) focus on the data mining approaches to seeking information from the rapidly growing literature. Ananiadou, Kell, and Tsujii (2006) mention that the number of MEDLINE searches in March 2006 were over 82 million, whereas in January 1997 it was only 163,000. These authors also discuss the topic of text mining and its potential applications to generate
hypotheses by discovering associations, patterns and clusters of related texts. They describe “the primary goal of text messaging is to retrieve knowledge that is hidden in text and to present the distilled knowledge to users in a concise form. Text messaging can discover associations, patterns, and clusters of related texts.” Moore (2007) discusses software packages used for data mining.
hypotheses by discovering associations, patterns and clusters of related texts. They describe “the primary goal of text messaging is to retrieve knowledge that is hidden in text and to present the distilled knowledge to users in a concise form. Text messaging can discover associations, patterns, and clusters of related texts.” Moore (2007) discusses software packages used for data mining.
The methods of data mining are highly complex statistical approaches and it is not necessary for those who use data mining to understand them, as long as one has a guide or expert to help him find the right ways of approaching the literature or database.
Uses of Data Mining in Drug Discovery and Development
The uses are discussed under several categories that are amenable to data mining techniques.
Drug Discovery
This topic is so broad and heterogeneous that it is divided into the following categories:
General—An introduction to mining the literature for the purposes of drug discovery is given by Jensen, Seric, and Bork (2006).
Chemoinformatics—This field applies information technology to the study of chemicals in terms of their properties, effects and uses (Rosania et al. 2007).
Pharmacology—Use of data generated by high throughput screening techniques are discussed by Harper and Pickett (2006). A discussion of many in silico methods used in drug discovery is given by Elkins, Mestress, and Testa (2007b).
Drug delivery—Elkins, Mestress, and Testa (2007a) discuss various approaches that can be used to assist in drug delivery goals after mining data.
Genomics and proteomics—Data mining is particularly important in this area due to the huge and rapidly growing databases in this area.
A few activities involving data mining are as follows:
Text mining to aid in the interpretation of microarray data and pathology reports (Elkins, Shimada, and Chang 2006)
Array Express is a repository that archives microarray data and can be mined (Krallinger, Erhardt, and Valenica 2005).
Cancer Gene Anatomy Project is a database of the National Cancer Institute of the National Institutes of Health and has thousands of expressed sequence tags from both normal and tumor cDNA libraries (Brazma et al. 2006).
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


